一、本文介绍
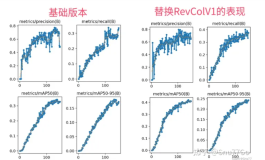
本文带来的改进机制是YOLOv5模型与多元分支模块(Diverse Branch Block)的结合,Diverse Branch Block (DBB) 是一种用于增强卷积神经网络性能的结构重新参数化技术。这种技术的核心在于结合多样化的分支,这些分支具有不同的尺度和复杂度,从而丰富特征空间。我将其放在了YOLOv5的不同位置上均有一定的涨点幅度,同时这个DBB模块的参数量并不会上涨太多,我添加三个该机制到模型中,GFLOPs上涨了0.4。

推荐指数:⭐⭐⭐⭐
打星原因:为什么打四颗星是因为我觉得这个机制的计算量会上涨,这是扣分点,其次涨幅效果也比较一般但是有涨点,当然可能是数据集的原因毕竟不同的数据集效果不同
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新
二、Diverse Branch Block原理

2.1 Diverse Branch Block的基本原理
Diverse Branch Block(DBB)的基本原理是在训练阶段增加卷积层的复杂性,通过引入不同尺寸和结构的卷积分支来丰富网络的特征表示能力。我们可以将基本原理可以概括为以下几点:
1. 多样化分支结构:DBB 结合了不同尺度和复杂度的分支,如不同大小的卷积核和平均池化,以增加单个卷积的特征表达能力。 2. 训练与推理分离:在训练阶段,DBB 采用复杂的分支结构,而在推理阶段,这些分支可以被等效地转换为单个卷积层,以保持高效推理。 3. 宏观架构不变:DBB 允许在不改变整体网络架构的情况下,作为常规卷积层的替代品插入到现有网络中。
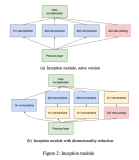
下面我将为大家展示Diverse Branch Block(DBB)的设计示例:

在训练时(左侧),DBB由不同大小的卷积层和平均池化层组成,这些层以一种复杂的方式并行排列,并最终合并输出。训练完成后,这些复杂的结构会转换成单个卷积层,用于模型的推理阶段(右侧),以此保持推理时的效率。这种转换允许DBB在保持宏观架构不变的同时,增加训练时的微观结构复杂性。
2.2 多样化分支结构
多样化分支结构是在卷积神经网络中引入的一种结构,旨在通过多样化的分支来增强模型的特征提取能力。这些分支包含不同尺寸的卷积层和池化层,以及其他潜在的操作,它们并行工作以捕获不同的特征表示。在训练完成后,这些复杂的结构可以合并并简化为单个的卷积层,以便在推理时不增加额外的计算负担。这种设计使得DBB可以作为现有卷积层的直接替换,增强了现有网络架构的性能,而不需要修改整体架构。
下面我详细展示了如何通过六种转换方法将训练时的Diverse Branch Block(DBB)转换为推理时的常规卷积层,每一种转换对应于一种特定的操作:

1. Transform I:将具有批量规范化(batch norm)的卷积层融合。 2. Transform II:合并具有相同配置的卷积层的输出。 3. Transform III:合并序列卷积层。 4. Transform IV:通过深度串联(concat)来合并卷积层。 5. Transform V:将平均池化(AVG)操作融入卷积操作中。 6. Transform VI:结合不同尺度的卷积层。
可以看到右侧的框显示了经过这些转换后,可以实现的推理时DBB,其中包含了常规卷积、平均池化和批量规范化操作。这些转换确保了在不增加推理时负担的同时,能够在训练时利用DBB的多样化特征提取能力。
2.3 训练与推理分离
训练与推理分离的概念是指在模型训练阶段使用复杂的DBB结构,而在模型推理阶段则转换为简化的卷积结构。这种设计允许模型在训练时利用DBB的多样性来增强特征提取和学习能力,而在实际应用中,即推理时,通过减少计算量来保持高效。这样,模型在保持高性能的同时,也保证了运行速度和资源效率。
下面我将展示在训练阶段如何通过不同的卷积组合(如图中的1x1和KxK卷积),以及在推理阶段如何将这些组合转换成一个简化的结构(如图中的转换IV所示的拼接操作):

经过分析,我们可以发现它说明了三种不同的情况:
A)组卷积(Groupwise conv):将输入分成多个组,每个组使用不同的卷积核。 B)训练时的1x1-KxK结构:首先应用1x1的卷积(减少特征维度),然后是分组的KxK卷积。 C)从转换IV的角度看:这是将多个分组的卷积输出合并的视角。这里,组内卷积后的特征图先分别通过1x1卷积处理,然后再进行拼接(concat)。
2.4 宏观架构不变
宏观架构不变指的是DBB在设计时考虑到了与现有的网络架构兼容性,确保可以在不改变整体网络架构(如ResNet等流行架构)的前提下,将DBB作为一个模块嵌入。这意味着DBB增强了网络的特征提取能力,同时保持了原有网络结构的布局,确保了推理时的效率和性能。这样的设计允许研究者和开发者将DBB直接应用到现有的深度学习模型中,而无需进行大规模的架构调整。