大家好,我是极智视界,本文整理介绍一下 Transformer ViT CLIP BLIP BERT 模型结构。
这几个模型都跟 变形金刚 相关,Transformer 是最开始的,然后像 ViT、CLIP、BLIP、BERT 都会用到 Transformer Encoder 模块,其中 ViT、CLIP、BLIP 是多模态模型,BERT 是 NLP 大模型。
Transformer
Paper:《Attention Is All You Need》
- encoder-decoder ==> 编码器 (6x) 一个词一个词往外蹦,解码器 (6x) 一次性看清整个句子;
- Multi-Head Attention ==> 一次性关注全局,多通道类比卷积;
- Masked Multi-Head Attention == > 在 t 时刻,掩盖 t 时刻以后的输入;
- Feed Forward ==> MLP;

ViT
Paper:《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》
- Patch + Position Embedding ==> 打成块 (步长 = 核长的卷积) + 位置编码 + 类别编码;
- Transformer Encoder ==> 图像提特征 ;
- MLP Head ==> 分类头
- Multi-Head Attention ==> linear 实现;

CLIP
Paper:《Learning Transferable Visual Models From Natural Language Supervision 》
- encoder-encoder ==> Image Encoder (Vit / Resnet),Text Encoder (transofer encoder);
- Contrastive pre-training ==> 对比学习,自监督;
- zero-shot == > 迁移学习;

BLIP
Paper:《BLIP: Bootstrapping Language-Image Pre-training for Unifified Vision-Language Understanding and Generation 》
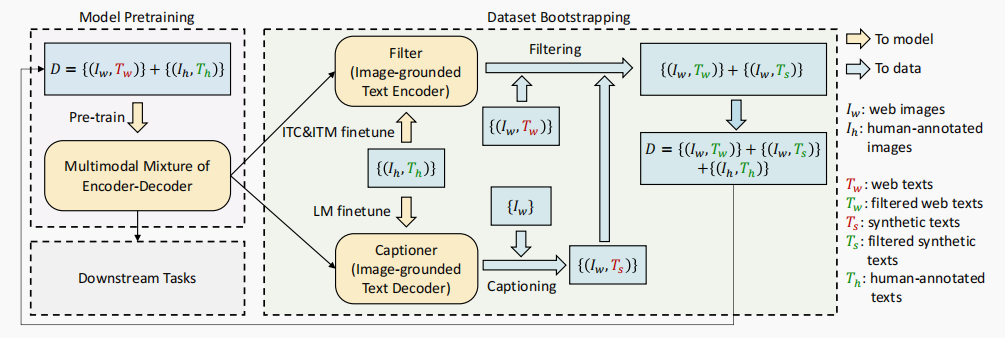
- MED ==> Image Encoder (ViT),Text Encoder (BERT),Image-grounded Text encoder (变种BERT),Image-grounded Text decoder (变种BERT);
- Image Encoder (ViT) ==> 视觉图像特征提取;
- Text Encoder (BERT) ==> ITC (Image-Text Contrastive Loss),对齐 图像-文本 特征空间;
- Image-grounded Text encoder (变种BERT) ==> 于 Bi Self-Att 和 Feed Forward 之间插入 Cross Attention (CA) 模块,以引入视觉特征, ITM (Image-Text Matching Loss),用来预测 图像-文本对 是 正匹配 还是 负匹配;
- Image-grounded Text decoder (变种BERT) ==> 将 Image-grounded Text Encoder 结构中的 Bi Self-Att 替换为 Causal Self-Att,LM (Language Modeling Loss) ,用来生成给定图像的文本描述;

- Captioner ==> 字幕器,用于生成给定 web 图像的字幕;
- Filter ==> 过滤器,用于去除噪声 图像-文本 对;
BERT
Paper:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
- Input Embeddings ==> Token Embeddings,Segment Embeddings,Position Embeddings;
- Masked LM ==> 完形填空,双向;GPT 单向;
- Next Sentence Prediction (NSP) ==> 句子对;


好了,以上整理分享了 Transformer ViT CLIP BLIP BERT 的模型结构。希望我的分享能对你的学习有一点帮助。