
探索云世界



“买家秀”秒变“卖家秀”,AI一键更换商品模特,虚拟模特功能等你解锁🔒 “小草图”秒变“大制作”,AI涂鸦作画让你的草图“一秒”成画🖌️ “2-4图”生成“个人写真”,AI虚拟分身在线创作,在家也是巴厘岛🏖️ 阿里云的微博视频 全网征集灵魂画手,几笔生成精美大作,精美礼物等你来拿

通义妙谈-阿里云图像生成大模型通义万相,Composer算法实现绘图精准可控
facechain人物写真应用自8月11日开源了第一版证件照生成后。目前在github(GitHub - modelscope/facechain: FaceChain is a deep-learning toolchain for generating your Digital-Twin.)上已有5.7K的star,论文链接:FaceChain: A Playground for Identity-Preserving Portrait Generation:https://arxiv.org/abs/2308.14256。
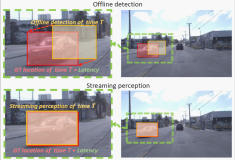
传统视频目标检测(Video Object Detection, VOD)是离线(offline)的检测任务,即仅考虑算法的检测精度,未考虑算法的延时。流感知(Streaming Perception)任务作为VOD的一个细分方向,采用流平均精度(Streaming Average Precision, sAP)指标,衡量算法的在线(online)检测能力,即同时衡量算法的精度和延时。本文针对现有的流感知工作在训练方式和模型感受野两方面的不足,提出了DAMO-StreamNet,在保证算法实时性的前提下,实现了SOTA的性能。

本文旨在整理一份可供参考和学习的专业ChatGPT相关资料,包括ChatGPT相关论文、Github项目、以及当前市场上出现的ChatGPT相关产品等。
本文介绍 阿里云开放视觉智能团队 被计算机视觉顶级国际会议ICCV 2023接收的论文 "TransFace: Calibrating Transformer Training for Face Recognition from a Data-Centric Perspective"。TransFace旨在探索ViT在人脸识别任务上表现不佳的原因,并从data-centric的角度去提升ViT在人脸识别任务上的性能。
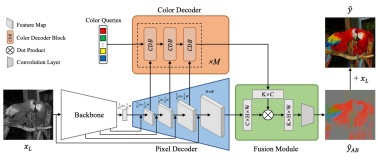
图像上色是老照片修复的一个关键步骤,本文介绍发表在 ICCV 2023 上的最新上色论文 DDColor

随着图像生成领域的研究飞速发展,基于diffusion的生成式模型取得效果上的大突破。在图像生成/编辑产品大爆发的今天,视频生成/编辑技术也引起了学术界和产业界的高度关注。该分享主要介绍视频生成/编辑的研究现状,包括不同技术路线的优劣势,以及该领域当下面临的核心问题与挑战。
伴随着持续不断的AIGC浪潮,越来越多的AI生成玩法正在被广大爱好者定义和提出,图像卡通化(动漫化)基于其还原效果高,风格种类丰富等特点而备受青睐。早在几年前,伴随着GAN网络的兴起,卡通化就曾经风靡一时。而今,伴随着AIGC技术的兴起和不断发展,扩散生成模型为卡通化风格和提供了更多的创意和生成的可能性。本文就将详细介绍达摩院开放视觉团队的卡通化技术实践。
本文主要用尽量简单白话的描述来剖析下AI换脸技术的原理,做一个科普文章,了解下当前换脸技术的发展现状及其局限性。
阿里巴巴最新自研的像素感知扩散超分模型已经开源,它把扩散模型强大的生成能力和像素级控制能力相结合,能够适应从老照片修复到AIGC图像超分的各种图像增强任务和各种图像风格,并且能够控制生成强度和增强风格。这项技术的直接应用之一是AIGC图像的后处理增强和二次生成,能够带来可观的效果提升。
本文介绍了ICCV23中稿论文 GAP: Generative Action Description Prompts for Skeleton-based Action Recognition
本地生活技术雷达是由本地生活技术中心战略管理&PMO团队开展的,定期扫描和评估新兴技术的战略研究工作。目的是对技术趋势进行前瞻性预判,提出新技术布局建议,在技术驱动业务创新和业务增长、践行社会责任等方面有一些实质性探索。 本篇尝试探讨 1)理解AI范式——从分析型(Analytical AI)到生成式(Generative AI)的拐点在2022年,其对人类社会以及商业模式的长期影响; 2)生成式AI(文生文、文生图、图生图等)在本地业务目前场景的应用和未来的方向。 欢迎技术、产品、运营、战略、管理层、国内国际等各种视角的指点和碰撞!

在Windows环境下,为FFmpeg集成音频编解码库,包括libogg、libvorbis和opencore-amr,涉及下载源码、配置、编译和安装步骤。首先,安装libogg,通过配置、make和make install命令完成,并更新PKG_CONFIG_PATH。接着,安装libvorbis,同样配置、编译和安装,并修改pkgconfig文件。之后,安装opencore-amr。最后,重新配置并编译FFmpeg,启用ogg和amr支持,通过ffmpeg -version检查是否成功。整个过程需确保环境变量设置正确,并根据路径添加相应库。

在《FFmpeg开发实战》一书中,介绍了如何在Linux环境下为FFmpeg集成libopus和libvpx,以支持WebM格式的Opus和VP8/VP9编码。首先,下载并安装libopus。接着,下载并安装libvpx。最后,在FFmpeg源码目录下,重新配置FFmpeg,启用libopus和libvpx,编译并安装。通过`ffmpeg -version`检查版本信息,确认libopus和libvpx已启用。

在Linux环境下,为FFmpeg添加对AAC、MP3、OGG和AMR音频格式的支持,需安装libogg、libvorbis和opencore-amr库。首先,从官方源下载各库的最新源码,如libogg-1.3.5、libvorbis-1.3.7和opencore-amr-0.1.6,然后解压并依次执行`./configure`、`make`和`make install`进行编译安装。接着,在FFmpeg源码目录中,使用`./configure`命令重新配置,并重新编译安装FFmpeg。最后,验证FFmpeg版本信息确认已启用ogg和amr支持。














