需要源码和环境搭建请点赞关注收藏后评论区留下QQ~~~
一、核心思想
针对DQN中出现的高估问题,有人提出深度双Q网络算法(DDQN),该算法是将强化学习中的双Q学习应用于DQN中。在强化学习中,双Q学习的提出能在一定程度上缓解Q学习带来的过高估计问题。
DDQN的主要思想是在目标值计算时将动作的选择和评估分离,在更新过程中,利用两个网络来学习两组权重,分别是预测网络的权重W和目标网络的权重W',在DQN中,动作选择和评估都是通过目标网络来实现的,而在DDQN中,计算目标Q值时,采取目标网络获取最优动作,再通过预测网络估计该最优动作的目标Q值,这样就可以将最优动作选额和动作值函数估计分离,采用不用的样本保证独立性
二、允许结果与分析
本节实验在Asterix游戏上,通过控制参数变量对DQN,DDQN算法进行性能对比从而验证了在一定程度上,DDQN算法可以缓解DQN算法的高估问题,DDQN需要两个不同的参数网络,每1000步后预测预测网络的参数同步更新给目标网络,实验设有最大能容纳1000000记录的缓冲池,每个Atari游戏,DDQN算法训练1000000时间步
实战结果如下图所示,图中的DDQN算法最后收敛回报明显大于DQN,并且在实验过程中,可以发现DQN算法容易陷入局部的情况,其问题主要在于Q-Learning中的最大化操作,Agent在选择动作时每次都取最大Q值得动作,对于真实的策略来说,在给定的状态下并不是每次都选择Q值最大的动作,因为一般真实的策略都是随机性策略,所以在这里目标值直接选择动作最大的Q值往往会导致目标值高于真实值
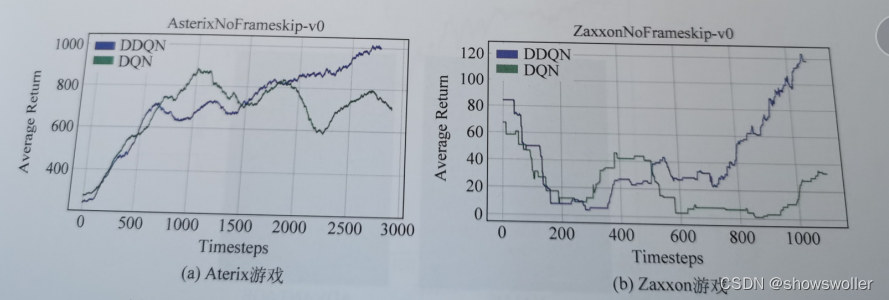
为了解决值函数高估计的问题,DDQN算法将动作的选择和动作的评估分别用不同的值函数来实现,结果表明DDQN能够估计出更准确的Q值,在一些Atari2600游戏中可获得更稳定有效的策略
三、代码
部分源码如下
import gym, random, pickle, os.path, math, glob import numpy as np import pandas as pd import matplotlib.pyplot as plt import torch import torch.optim as optim import torch.nn as nn import torch.nn.functional as F import torch.autograd as autograd import pdb from atari_wrappers import make_atari, wrap_deepmind,LazyFrames def __init__(self, in_channels=4, num_actions=5): nnels: number of channel of input. i.e The number of most recent frames stacked together as describe in the paper num_actions: number of action-value to output, one-to-one correspondence to action in game. """ super(DQN, self).__init__() self.conv1 = nn.Conv2d(in_channels, 32, kernel_size=8, stride=4) self.conv2 = nn.Conv2d(32, 64, kernel_size=4, stride=2) self.conv3 = nn.Conv2d(64, 64, kernel_size=3, stride=1) self.fc4 = nn.Linear(7 * 7 * 64, 512) self.fc5 = nn.Linear(512, num_actions) def forward(self, x): x = F.relu(self.conv1(x)) x = F.relu(self.conv2(x)) x = F.relu(self.conv3(x)) x = F.relu(self.fc4(x.view(x.size(0), -1))) return self.fc5(x) class Memory_Buffer(object): def __init__(self, memory_size=1000): self.buffer = [] self.memory_size = memory_size self.next_idx = 0 def push(self, state, action, reward, next_state, done): data = (state, action, reward, next_state, done) if len(self.buffer) <= self.memory_size: # buffer not full self.buffer.append(data) else: # buffer is full self.buffer[self.next_idx] = data self.next_idx = (self.next_idx + 1) % self.memory_size def sample(self, batch_size): states, actions, rewards, next_states, dones = [], [], [], [], [] for i in range(batch_size): idx = random.randint(0, self.size() - 1) data = self.buffer[idx] state, action, reward, next_state, done= data states.append(state) actions.append(action) rewards.append(reward) next_states.append(next_state) dones.append(done) return np.concatenate(states), actions, rewards, np.concatenate(next_states), dones def size(self): return len(self.buffer) class DDQNAgent: def __init__(self, in_channels = 1, action_space = [], USE_CUDA = False, memory_size = 10000, epsilon = 1, lr = 1e-4): self.epsilon = epsilon self.action_space = action_space self.memory_buffer = Memory_Buffer(memory_size) self.DQN = DQN(in_channels = in_channels, num_actions = action_space.n) self.DQN_target = DQN(in_channels = in_channels, num_actions = action_space.n) self.DQN_target.load_state_dict(self.DQN.state_dict()) self.USE_CUDA = USE_CUDA if USE_CUDA: self.DQN = self.DQN.to(device) self.DQN_target = self.DQN_target.to(device) self.optimizer = optim.RMSprop(self.DQN.parameters(),lr=lr, eps=0.001, alpha=0.95) def observe(self, lazyframe): # from Lazy frame to tensor state = torch.from_numpy(lazyframe._force().transpose(2,0,1)[None]/255).float() if self.USE_CUDA: state = state.to(device) return state def value(self, state): q_values = self.DQN(state) return q_values def act(self, state, epsilon = None): """ sample actions with epsilon-greedy policy recap: with p = epsilon pick random action, else pick action with highest Q(s,a) """ if epsilon is None: epsilon = self.epsilon q_values = self.value(state).cpu().detach().numpy() if random.random()<epsilon: aciton = random.randrange(self.action_space.n) else: aciton = q_values.argmax(1)[0] return aciton def compute_td_loss(self, states, actions, rewards, next_states, is_done, gamma=0.99): """ Compute td loss using torch operations only. Use the formula above. """ actions = torch.tensor(actions).long() # shape: [batch_size] rewards = torch.tensor(rewards, dtype =torch.float) # shape: [batch_size] is_done = torch.tensor(is_done, dtype = torch.uint8) # shape: [batch_size] if self.USE_CUDA: actions = actions.to(device) rewards = rewards.to(device) is_done = is_done.to(device) # get q-values for all actions in current states predicted_qvalues = self.DQN(states) # select q-values for chosen actions predicted_qvalues_for_actions = predicted_qvalues[ range(states.shape[0]), actions ] # compute q-values for all actions in next states ## Where DDQN is different from DQN predicted_next_qvalues_current = self.DQN(next_states) predicted_next_qvalues_target = self.DQN_target(next_states) # compute V*(next_states) using predicted next q-values next_state_values = predicted_next_qvalues_target.gather(1, torch.max(predicted_next_qvalues_current, 1)[1].unsqueeze(1)).squeeze(1) # compute "target q-values" for loss - it's what's inside square parentheses in the above formula. target_qvalues_for_actions = rewards + gamma *next_state_values # at the last state we shall use simplified formula: Q(s,a) = r(s,a) since s' doesn't exist target_qvalues_for_actions = torch.where( is_done, rewards, target_qvalues_for_actions) # mean squared error loss to minimize #loss = torch.mean((predicted_qvalues_for_actions - # target_qvalues_for_actions.detach()) ** 2) loss = F.smooth_l1_loss(predicted_qvalues_for_actions, target_qvalues_for_actions.detach()) return loss def sample_from_buffer(self, batch_size): states, actions, rewards, next_states, dones = [], [], [], [], [] for i in range(batch_size): idx = random.randint(0, self.memory_buffer.size() - 1) data = self.memory_buffer.buffer[idx] frame, action, reward, next_frame, done= data states.append(self.observe(frame)) actions.append(action) rewards.append(reward) next_states.append(self.observe(next_frame)) dones.append(done) return torch.cat(states), actions, rewards, torch.cat(next_states), dones def learn_from_experience(self, batch_size): if self.memory_buffer.size() > batch_size: states, actions, rewards, next_states, dones = self.sample_from_buffer(batch_size) td_loss = self.compute_td_loss(states, actions, rewards, next_states, dones) self.optimizer.zero_grad() td_loss.backward() for param in self.DQN.parameters(): param.grad.data.clamp_(-1, 1) self.optimizer.step() return(td_loss.item()) else: return(0) def moving_average(a, n=3) : ret = np.cumsum(a, dtype=float) ret[n:] = ret[n:] - ret[:-n] return ret[n - 1:] / n def plot_training(frame_idx, rewards, losses): clear_output(True) plt.figure(figsize=(20,5)) plt.subplot(131) plt.title('frame %s. reward: %s' % (frame_idx, np.mean(rewards[-100:]))) plt.plot(moving_average(rewards,20)) plt.subplot(132) plt.title('loss, average on 100 stpes') plt.plot(moving_average(losses, 100),linewidth=0.2) plt.show() # if __name__ == '__main__': # Training DQN in PongNoFrameskip-v4 env = make_atari('PongNoFrameskip-v4') env = wrap_deepmind(env, scale = False, frame_stack=True) gamma = 0.99 epsilon_max = 1 epsilon_min = 0.01 eps_decay = 30000 frames = 1000000 USE_CUDA = True learning_rate = 2e-4 max_buff = 100000 update_tar_interval = 1000 batch_size = 32 print_interval = 1000 log_interval = 1000 learning_start = 10000 win_reward = 18 # Pong-v4 win_break = True action_space = env.action_space action_dim = env.action_space.n state_dim = env.observation_space.shape[0] state_channel = env.observation_space.shape[2] agent = DDQNAgent(in_channels = state_channel, action_space= action_space, USE_CUDA = USE_CUDA, lr = learning_rate) #frame = env.reset() episode_reward = 0 all_rewards = [] losses = [] episode_num = 0 is_win = False # tensorboard summary_writer = SummaryWriter(log_dir = "DDQN", comment= "good_makeatari") # e-greedy decay epsilon_by_frame = lambda frame_idx: epsilon_min + (epsilon_max - epsilon_min) * math.exp( -1. * frame_idx / eps_decay) # plt.plot([epsilon_by_frame(i) for i in range(10000)]) for i in range(frames): epsilon = epsilon_by_frame(i) #state_tensor = agent.observe(frame) #action = agent.act(state_tensor, epsilon) #next_frame, reward, done, _ = env.step(action) #episode_reward += reward #agent.memory_buffer.push(frame, action, reward, next_frame, done) #frame = next_frame loss = 0 if agent.memory_buffer.size() >= learning_start: loss = agent.learn_from_experience(batch_size) losses.append(loss) if i % print_interval == 0: print("frames: %5d, reward: %5f, loss: %4f, epsilon: %5f, episode: %4d" % (i, np.mean(all_rewards[-10:]), loss, epsilon, episode_num)) summary_writer.add_scalar("Temporal Difference Loss", loss, i) summary_writer.add_scalar("Mean Reward", np.mean(all_rewards[-10:]), i) summary_writer.add_scalar("Epsilon", epsilon, i) if iQN_dict.pth.tar") plot_training(i, all_rewards, losses)
创作不易 觉得有帮助请点赞关注收藏~~~


