1、布隆过滤器
Bloom过滤器是一种节省空间的概率数据结构,用于测试元素是否为某集合的成员。它用于我们只需要检查元素是否属于对象的场景。

在BigTable(和Cassandra)中,任何读取操作都必须从组成Tablet的SSTable中读取。如果这些SSTable不在内存中,则读取操作可能最终会执行许多磁盘访问以便读取所需的SSTable。为了减少磁盘访问次数,BigTable 使用Bloom过滤器。
2、一致性哈希
一致的哈希允许您轻松扩展,从而允许以有效的方式复制数据,从而实现更好的可用性和容错能力。
通过对数据项的键进行哈希处理以产生其在环上的位置,然后顺时针遍历环以查找位置大于该项位置的第一个节点,将每个由键标识的数据项分配给节点。与节点关联的节点是数据项的位置。

一致散列的主要优点是增量稳定性;节点离开或到达集群仅影响其直接邻居,其他节点不受影响。
3、Quorum
在分布式环境中,quorum是在确认操作成功之前需要成功执行此分布式操作的最小服务器数。

Cassandra,为了确保数据一致性,每个写入请求都可以配置为仅当数据已写入至少一个quorum(或大多数)副本节点时才成功。
对于领导者选举,Chubby使用Paxos,它使用quorum来确保强大的一致性。
Dynamo 将写入复制到系统中其他节点的草率quorum,而不是像Paxos那样的严格多数quorum。所有读/写操作都在首选项列表中的第一个NN正常节点上执行,该节点可能并不总是在遍历一致哈希环时遇到的第一个NN节点。
4、领导者(Leader)和追随者(Follower)
为了在管理数据的系统中实现容错,需要在多个服务器上复制数据。
在集群中选择一个服务器作为领导者。领导者负责代表整个集群做出决策,并将决策传播到所有其他服务器。
三到五个节点的集群,就像在实现共识的系统中一样,领导者选举可以在数据集群本身内实施,而不依赖于任何外部系统。领导者选举在服务器启动时进行。每个服务器在启动时都会启动领导者选举,并尝试选举领导者。除非选出领导者,否则系统不接受任何客户端请求。
5、心跳
心跳机制用于检测现有领导者是否失败,以便可以启动新的领导者选举。
6、Fencing
在领导者-追随者模式中,当领导者失败时,不可能确定领导者已停止工作。例如,慢速网络或网络分区可能会触发新的领导者选举,即使前一个领导者仍在运行并认为它仍然是活动的领导者。
屏蔽是指在以前处于活动状态的领导者周围设置围栏,使其无法访问集群资源,从而停止为任何读/写请求提供服务。
使用以下两种技术:
- 资源屏蔽:系统会阻止以前处于活动状态的领导者访问执行基本任务所需的资源。
- 节点屏蔽:系统会阻止以前处于活动状态的领导者访问所有资源。执行此操作的常见方法是关闭节点电源或重置节点。
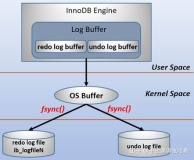
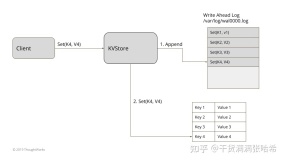
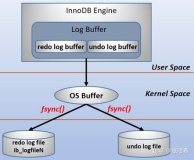
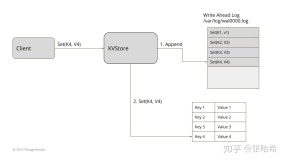
7、WAL(预写日志Write-ahead Log)
预写日志记录是解决操作系统中文件系统不一致的问题的高级解决方案。受数据库管理系统的启发,此方法首先将要执行的操作的摘要记入“日志”中,然后再将其实际写入磁盘。在发生崩溃的情况下,操作系统只需检查此日志并从中断的位置继续。
8、分段日志
将日志拆分为多个较小的文件,而不是单个大文件,以便于操作。
单个日志文件在启动时读取时可能会增长并成为性能瓶颈。较旧的日志会定期清理,并且很难对单个大文件执行清理操作。
单个日志拆分为多个段。日志文件在指定的大小限制后滚动。使用日志分段,需要有一种将逻辑日志偏移量(或日志序列号)映射到日志段文件的简单方法。
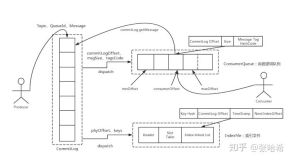
9、高水位线(High-Water mark)
跟踪领导者上的最后一个日志条目,该条目已成功复制到追随者的quorum。日志中此条目的索引称为高水位线索引。领导者仅公开到高水位线索引的数据。
Kafka:为了处理非可重复读取并确保数据一致性,Kafka broker会跟踪高水位线,这是特定分区的最大偏移量。使用者只能看到高水位线之前的消息。
10、租约(Lease)
租约就像一个锁,但即使客户端离开,它也能工作。客户端请求有限期限的租约,之后租约到期。如果客户端想要延长租约,它可以在租约到期之前续订租约。
Chubby客户端与领导者保持有时限的会话租约。在此时间间隔内,领导者保证不会单方面终止会话。
11、Gossip协议
Gossip协议是点对点通信机制,其中节点定期交换有关自己和他们所知道的其他节点的状态信息。
每个节点每秒启动一轮Gossip回合,以与另一个随机节点交换有关自己和其他节点的状态信息。

12、Phi 累计故障检测(Phi Accrual Failure Detection)
此算法使用历史检测信号信息使阈值自适应。通用的应计故障检测器不会判断服务器是否处于活动状态,而是输出有关服务器的可疑级别。
Cassandra使用Phi应计故障检测器算法来确定群集中节点的状态。
13、脑裂
分布式系统具有两个或多个活动领导者的场景称为脑裂。
通过使用生成时钟(Generation Clock)可以解决脑裂问题,生成时钟只是一个单调递增的数字,用于指示服务器的生成。
每次选出新领导者时,时钟数字(generation number)都会增加。这意味着,如果旧领导者的时钟数为“1”,则新领导人的时钟数将为“2”。此时钟号包含在从领导发送到其他节点的每个请求中。通过这种方式,节点现在可以通过简单地信任具有最高数字的领导者来轻松区分真正的领导者。
Kafka:为了处理脑裂(我们可以有多个active controller broker),Kafka使用“纪元数”(Epoch number),这只是一个单调增加的数字来表示服务器的代次(generation)。
HDFS:ZooKeeper用于确保任何时候只有一个NameNode处于活动状态。epoch编号作为每个事务ID的一部分进行维护,以反映NameNode的代次。