
可以将MaxCompute的数据迁移到Hadoop集群吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
MaxCompute不支持直接将数据迁移到Hadoop的工具,您可以考虑使用像Sqoop这样的工具,它支持从MaxCompute导出数据到Hadoop,但反向迁移可能需要自定义解决方案。
可以将MaxCompute的数据迁移到Hadoop集群。以下是将数据从MaxCompute迁移到Hadoop集群的基本步骤:
准备环境:
确保您有访问阿里云MaxCompute和目标Hadoop集群的权限。
在您的本地机器上安装并配置好Python环境和PyODPS库。
在Hadoop集群上配置好HDFS和必要的客户端工具。
使用PyODPS导出数据:
使用PyODPS连接到MaxCompute项目。
执行SQL查询或使用PyODPS的API来读取需要迁移的数据。
将数据保存为CSV或其他格式的文件。
上传数据到Hadoop集群:
使用SCP、FTP或其他文件传输方法将数据文件从本地上传到Hadoop集群的HDFS中。
或者,如果Hadoop集群支持,可以直接从MaxCompute导出数据到HDFS。
验证数据:
在Hadoop集群上检查数据文件是否完整无误。
可以使用Hadoop命令行工具如hdfs dfs -ls查看文件,或使用hdfs dfs -cat查看文件内容。
处理后续任务:
根据需要在Hadoop集群上进行数据处理或分析。
可以编写MapReduce作业或使用其他大数据处理框架(如Apache Spark)来处理数据。
优化和监控:
监控数据传输和处理过程的性能。
根据需要调整配置以优化性能。
请注意,具体的操作可能会因您的具体需求和环境配置而有所不同。如果您在迁移过程中遇到任何问题,建议参考阿里云和Hadoop的官方文档或寻求技术支持帮助。
可以。
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、HDFS、Hive、OceanBase、HBase、OTS、MaxCompute 等各种异构数据源之间高效的数据同步功能。 DataX同步引擎内部实现了任务的切分、调度执行能力,DataX的执行不依赖Hadoop环境。
DataX-On-Hadoop是DataX针对Hadoop调度环境实现的版本,使用hadoop的任务调度器,将DataX task(Reader->Channel->Writer)调度到hadoop执行集群上执行。这样用户的hadoop数据可以通过MR任务批量上传到MaxCompute等,不需要用户提前安装和部署DataX软件包,也不需要另外为DataX准备执行集群。但是可以享受到DataX已有的插件逻辑、流控限速、鲁棒重试等等。
目前DataX-On-Hadoop支持将Hadoop中的数据上传到公共云MaxCompute当中。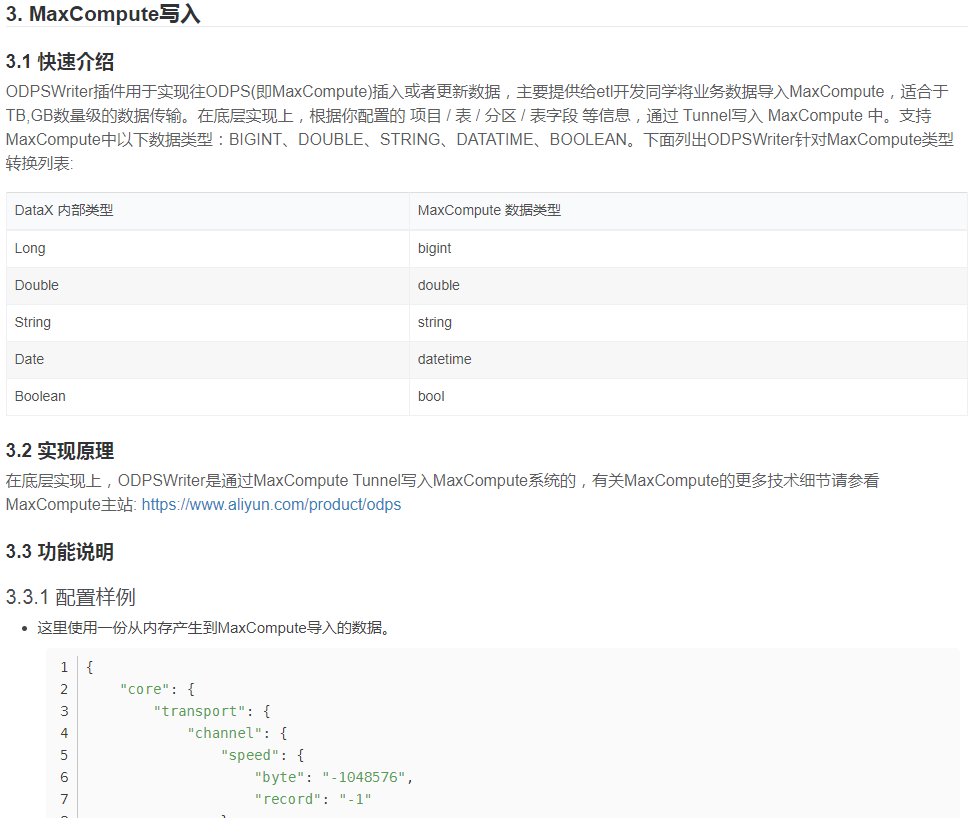
——参考链接。
本文为您介绍数据迁移的最佳实践,包含将其他业务平台的业务数据或日志数据迁移至MaxCompute,或将MaxCompute的数据迁移至其它业务平台。
MaxCompute跨项目数据迁移:
同一地域的MaxCompute跨项目数据迁移,详情请参见使用CLONE TABLE实现同地域MaxCompute跨项目数据迁移或通过DataWorks实现MaxCompute跨项目迁移。
不同地域的MaxCompute跨项目数据迁移,详情请参见通过跨项目数据访问实现不同地域MaxCompute项目数据迁移。

参考文档https://help.aliyun.com/zh/maxcompute/use-cases/overview-27
将MaxCompute的数据迁移到Hadoop集群是可行的,但需要一些中间步骤和工具来完成这个过程。以下是一些常见的方法和步骤:
阿里云提供了DataX工具,它是一个异构数据源离线同步工具,支持多种数据源之间的数据同步,包括MaxCompute和Hadoop HDFS。
下载并安装DataX:
编写JSON配置文件:
示例配置文件如下:
{
"job": {
"content": [
{
"reader": {
"name": "odpsreader",
"parameter": {
"accessId": "<your-access-id>",
"accessKey": "<your-access-key>",
"endpoint": "<your-maxcompute-endpoint>",
"project": "<your-maxcompute-project>",
"table": "<your-maxcompute-table>",
"column": ["*"],
"splitPk": "<your-split-column>",
"where": "<optional-where-clause>"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://<your-hadoop-namenode>:<port>",
"fileType": "text",
"path": "/user/hive/warehouse/<your-hadoop-directory>",
"fileName": "<your-file-name>",
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "GZIP"
}
}
}
],
"setting": {
"speed": {
"channel": 3
}
}
}
}
运行DataX任务:
python datax.py your_config_file.json
如果你有Hadoop集群并且已经安装了Sqoop,可以使用Sqoop来迁移数据。不过,直接从MaxCompute到Hadoop的连接可能不直接支持,你可以通过以下步骤间接实现:
导出MaxCompute数据到OSS:
tunnel download <your-maxcompute-table> <oss-path>
从OSS下载数据到Hadoop:
hadoop fs -put命令或其他方式将OSS上的数据下载到HDFS。ossutil cp oss://<bucket>/<object> /local/path
hdfs dfs -put /local/path /hdfs/path
如果你有Spark集群,可以使用Spark读取MaxCompute数据并写入HDFS。
配置MaxCompute Connector for Spark:
编写Spark作业:
示例代码(Scala):
import com.aliyun.odps.spark._
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder()
.appName("MaxCompute to HDFS")
.getOrCreate()
// 读取MaxCompute表
val df = spark.read.odps("<your-maxcompute-table>")
// 将数据写入HDFS
df.write.format("parquet").save("hdfs://<your-hadoop-namenode>:<port>/<hdfs-path>")
通过以上方法,你可以将MaxCompute的数据迁移到Hadoop集群。选择哪种方法取决于你的具体需求和现有基础设施。
MaxCompute到Hadoop的数据迁移一般是从Hadoop迁移到MaxCompute,但MaxCompute不支持直接的数据导出到Hadoop。通常,数据迁移是单向的,即从其他数据源迁移到MaxCompute。若需要从MaxCompute导出数据,您可能需要在目标Hadoop集群上构建对应的表和分区,然后通过 Sqoop 或自定义脚本实现数据下载。建议您根据实际情况,先在Hadoop集群上创建对应的表结构,然后使用 Sqoop 或其他数据加载工具进行定制化的数据迁移
Hadoop数据迁移到MaxCompute原理讲解
参考文档https://help.aliyun.com/video_detail/88429.html?spm=a2c4g.11186623.0.0.154869c1AAvgAo

