
系统是windows的wsl2 ubuntu20.04
笔记本显卡3060 6G显存 i7 16G内存
cuda 11.6
python 3.7
torch 1.13.1+cu116
torchaudio 0.13.1+cu116
torchvision 0.14.1+cu116
使用该训练模型进行微调
SambertHifigan语音合成-中文-多人预训练-16k
根据教程指示,在微调sambert声学模型时,程序老是在随机某一代卡住,但是从后台监控来看,程序并没有终端,一直保持着高占用的状态,不过内存和显存还有余量。
数据集train 90条 val 10条,共100条,自己录的。
我一开始分析可能是内存不足或者是多线程导致的互锁问题,尝试过修改配置文件config.yaml里的
num_workers: 0 # 4
pin_memory: true # false
以及减小batch_size,都无济于事。
以下是训练卡住时的终端界面和htop内存使用情况: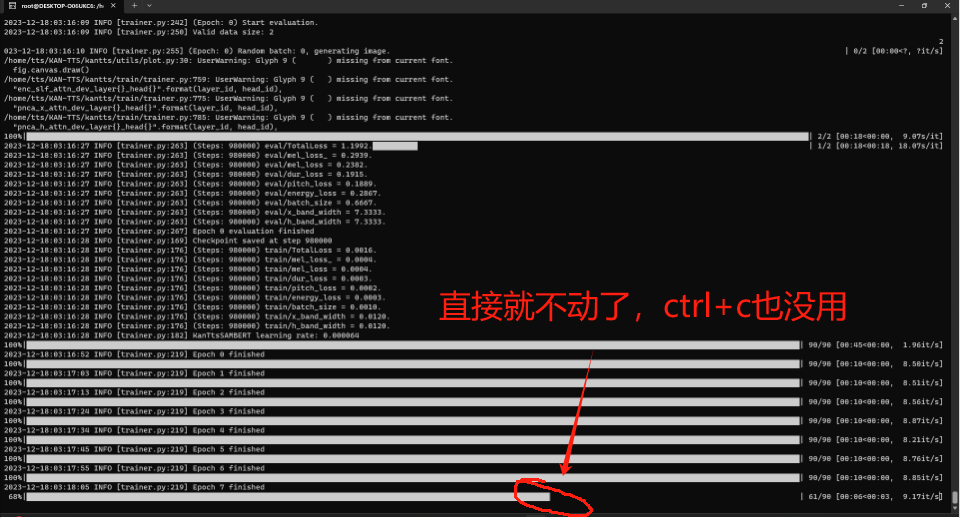
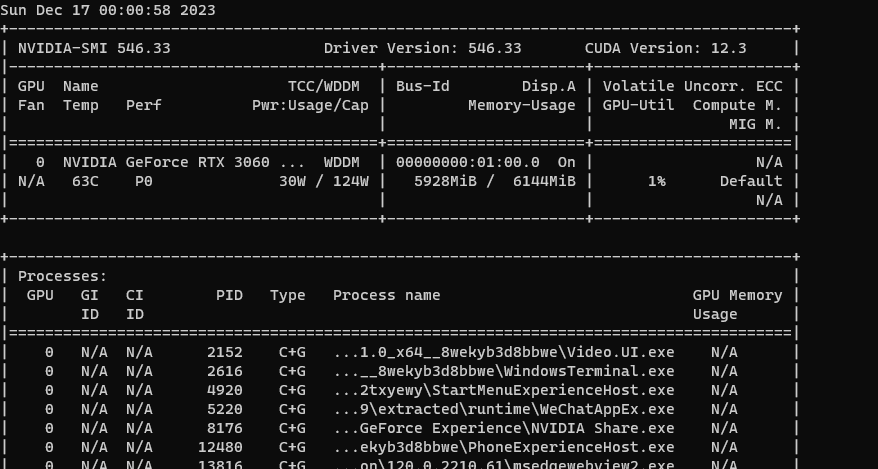
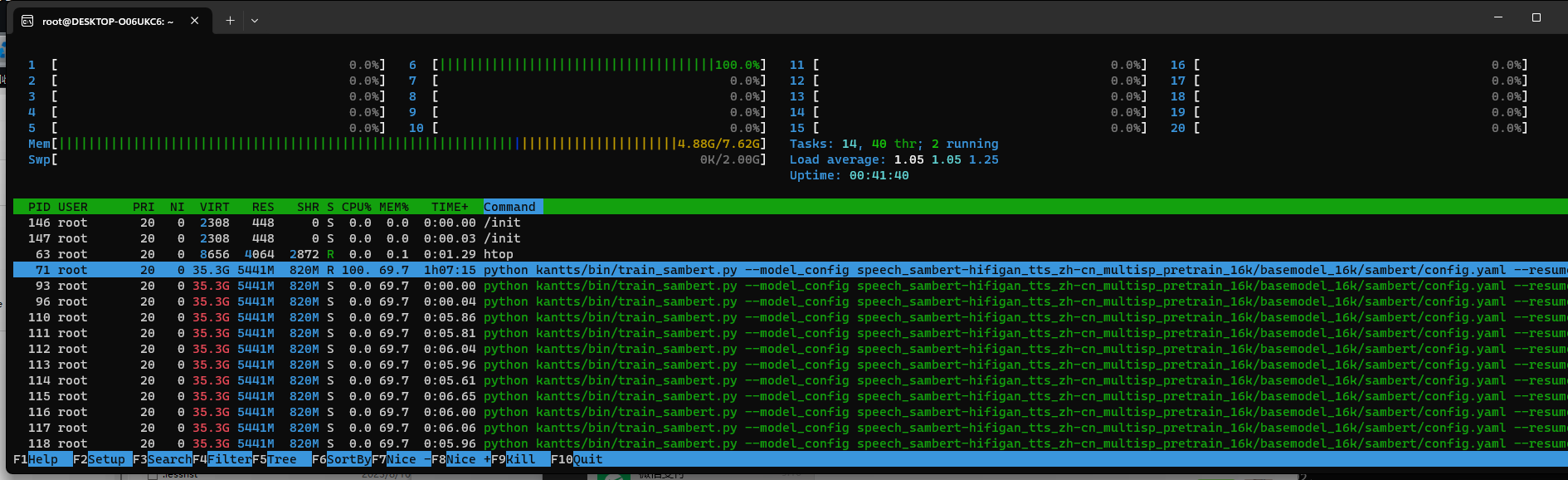
被这个问题折磨2天了,跪求大佬解答,可以有偿。
