
flinkcdc 怎么做批?kafka怎么做批?
flinkcdc 怎么做批?kafka怎么做批?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
1、Flink CDC (Flink Change Data Capture) 是基于数据库的日志 CDC 技术,实现了全增量一体化读取的数据集成框架。搭配Flink计算框架,Flink CDC 可以高效实现海量数据的实时集成。
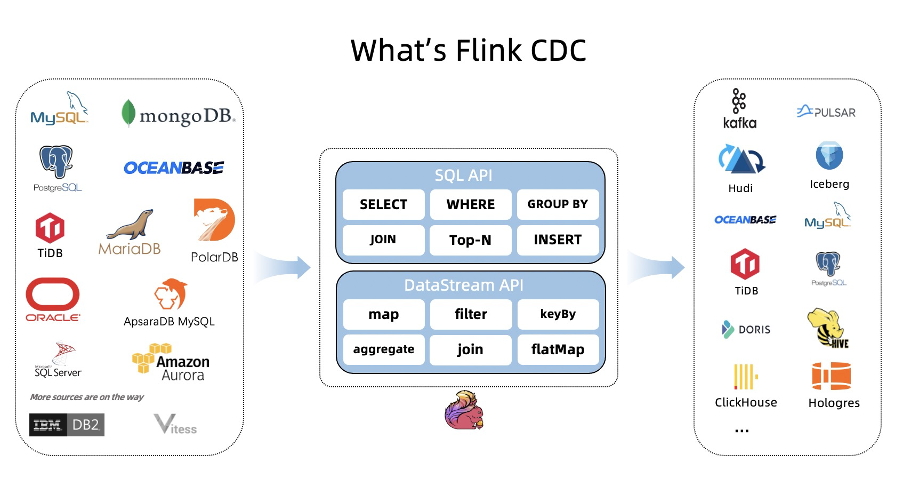
基于查询的 CDC,离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据。
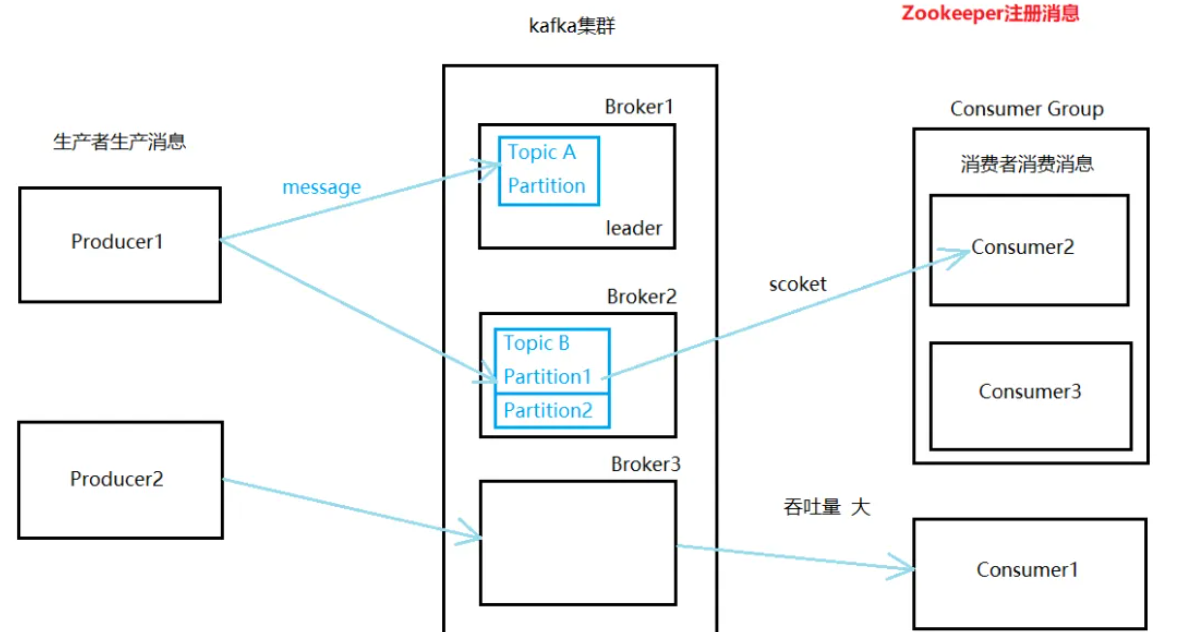
2、Kafka中的消息可以通过批量处理来提高性能,即一次性处理多个消息而不是单个消息。Kafka的批量处理包括生产者端和消费者端。
- 生产者批量处理
Kafka生产者可以使用批量方式发送消息,即将多个消息封装为一个批次进行发送,这样可以减少网络传输的开销,提高生产者的性能。
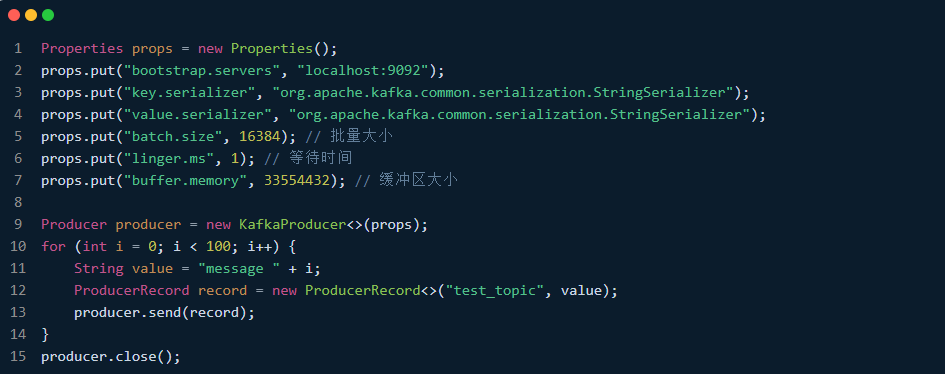
在Java中,可以使用Kafka提供的ProducerRecord和Producer实例进行批量发送消息,示例代码如下:
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("batch.size", 16384); // 批量大小 props.put("linger.ms", 1); // 等待时间 props.put("buffer.memory", 33554432); // 缓冲区大小 Producer producer = new KafkaProducer<>(props); for (int i = 0; i < 100; i++) { String value = "message " + i; ProducerRecord record = new ProducerRecord<>("test_topic", value); producer.send(record); } producer.close();在上述示例中,使用Properties对象设置Kafka相关属性,其中batch.size、linger.ms和buffer.memory用于控制批处理的行为。然后使用KafkaProducer实例创建ProducerRecord对象,并批量发送消息至Kafka服务器。
- 消费者批量处理
Kafka消费者可以使用poll()方法批量获取消息,即一次性获取多个消息进行处理,这样可以减少网络传输的开销,提高消费者的性能。
在Java中,可以使用Kafka提供的ConsumerRecord和Consumer实例进行批量接收消息,示例代码如下:
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "test_group"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("max.poll.records", "100"); // 最大批量数 Consumer consumer = new KafkaConsumer<>(props); consumer.subscribe(Arrays.asList("test_topic")); while (true) { ConsumerRecords records = consumer.poll(Duration.ofSeconds(1)); // 获取批量消息 for (ConsumerRecord record : records) { System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value()); } }在上述示例中,使用Properties对象设置Kafka相关属性,其中max.poll.records用于控制批处理的行为,设置一次最多拉取100条记录。然后使用KafkaConsumer实例订阅test_topic主题,并使用poll()方法批量获取消息,并进行处理。
Kafka中的消息可以通过批量处理来提高性能。生产者端可以将多个消息封装为一个批次进行发送,消费者端可以使用poll()方法批量获取消息进行处理。需要注意的是,Kafka提供的批量处理机制需要根据具体场景进行调整,选择合适的批量大小和等待时间参数,以获得最佳性能。
2023-08-26 19:11:53赞同 展开评论 -
十分耕耘,一定会有一分收获!
楼主你好,阿里云 Flink CDC 支持使用 Flink 官方提供的批处理 API 进行数据处理。具体做法如下:
使用 Flink DataSet API 或 Flink SQL API 读取 CDC 数据。
将读取的数据进行必要的转换和处理。
使用 Flink DataSet API 或 Flink SQL API 将数据写入目标存储。
Kafka 也可以进行批处理,常见的做法是使用 Kafka Connect 框架来对 Kafka 数据进行批处理。具体做法如下:
安装并启动 Kafka Connect。
编写一个 Kafka Connect 插件,实现对数据的批处理逻辑。
将编写的插件安装到 Kafka Connect 中。
使用 Kafka Connect 提供的 REST API 或者命令行工具来配置和启动批处理任务。
需要注意的是,Flink CDC 和 Kafka Connect 都支持对流数据进行处理,如果处理场景不需要批处理,可以使用流处理的方法来实现。
2023-08-21 14:00:27赞同 展开评论 -
Flink CDC和Kafka都可以支持批处理操作,下面是一些关于如何在它们中进行批处理的概述:
Flink CDC的批处理:
Flink CDC是基于流处理引擎的技术,主要用于实时处理和捕获数据变化。但是,您可以通过以下方式在Flink中执行批处理操作:
使用窗口(Windows):Flink提供了各种类型的窗口,如滚动窗口、滑动窗口和会话窗口。您可以根据时间或者其他条件将数据划分为不同的窗口,并在窗口上应用聚合函数或其他操作来实现批处理。
设置触发器(Trigger):Flink的窗口可以根据特定的触发条件触发计算。例如,根据元素数量或者事件时间的进展等条件触发计算。通过选择适当的触发策略,您可以控制数据在窗口中的处理,以实现批处理效果。
使用批处理源(Batch Source):如果您有一个数据源是批量读取数据的(例如,从文件系统),您可以使用Flink的批处理源读取数据,并在Flink中进行处理。这样,您可以利用Flink的批处理算子对数据进行转换和分析。
Kafka的批处理:
Kafka是一个高性能的分布式消息队列系统,也可以支持批处理操作。以下是一些在Kafka中进行批处理的方法:
设置批量大小(Batch Size):您可以通过调整Kafka Producer的
batch.size参数来控制批处理的大小。较大的批量大小将允许Producer在发送消息之前累积更多的消息,从而提高吞吐量。使用分区器(Partitioner):Kafka的分区器决定将消息发送到哪个分区。通过合理地选择分区键或配置自定义分区器,您可以将相关的消息聚集在同一个分区中,从而实现批处理效果。
消费者拉取(Consumer Pulling):Kafka的消费者可以使用
poll()方法从Broker中拉取一批消息。您可以通过调整max.poll.records参数来控制每次拉取的消息数量,从而实现批处理。
2023-08-19 18:36:57赞同 展开评论 -
Flink CDC 和 Kafka 都可以用于批处理。使用 Flink CDC,您可以将 MySQL 数据库中的更改数据捕获到 Flink 中,然后使用 Flink 的 Kafka 生产者将数据写入 Kafka 主题。在处理过程数据时,可以使用 Flink 的流处理功能对数据进行转换、聚合、过滤等操作,然后将结果写回到 Kafka 中 。
2023-08-17 16:38:03赞同 展开评论 -
使用Flink的DataStream API和Kafka的KafkaConsumer API来实现批处理,可以按照以下步骤进行:
1、在Flink中安装和配置CDC。可以使用以下命令安装和配置CDC:
$ bin/flink run -c org.apache.flink.client.cli.CliFrontend ./flink run -m yarn-cluster -yn 2 -ys 2 -yjm 1024 -ytm 1024 -c com.example.CDC /path/to/cdc.jar /path/to/config.yml2、启用CDC。可以使用以下命令启用CDC:
$ bin/flink run -c org.apache.flink.client.cli.CliFrontend ./flink run -m yarn-cluster -yn 2 -ys 2 -yjm 1024 -ytm 1024 -c com.example.CDC /path/to/cdc.jar /path/to/config.yml start3、在Flink中定义一个DataStream,用于读取CDC数据。可以使用以下代码来定义DataStream:
DataStream<String> stream = env.addSource(new CDCSource());4、在DataStream中使用转换器将CDC数据转换为需要的格式。可以使用以下代码来使用转换器:
DataStream<String> stream = env.addSource(new CDCSource()); DataStream<String> result = stream.map(new MapFunction<String, String>() { @Override public String map(String value) throws Exception { // 对CDC数据进行转换 return value; } });5、将DataStream写入Kafka。可以使用以下代码来将DataStream写入Kafka:
DataStream<String> stream = env.addSource(new CDCSource()); DataStream<String> result = stream.map(new MapFunction<String, String>() { @Override public String map(String value) throws Exception { // 对CDC数据进行转换 return value; } }); KafkaSink<String> sink = KafkaSinkBuilder.<String>newBuilder() .setBootstrapServers("localhost:9092") .setKeySerializer(new StringSerializer()) .setValueSerializer(new StringSerializer()) .setTopic("CDC") .build(); result.addSink(sink);6、在Kafka中安装和配置Kafka。可以使用以下命令安装和配置Kafka:
$ bin/zookeeper-server-start.sh config/zookeeper.properties $ bin/kafka-server-start.sh config/server.properties7、创建一个Kafka主题,用于接收CDC数据。可以使用以下命令创建Kafka主题:
$ bin/kafka-topics.sh --create --topic CDC --partitions 1 --replication-factor 18、在Kafka中定义一个Kafka消费者,用于读取CDC数据。可以使用以下代码来定义Kafka消费者:
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "CDC"); KafkaConsumer<String> consumer = new KafkaConsumer<>(props, new StringDeserializer(), new StringDeserializer()); consumer.subscribe(Arrays.asList("CDC"));9、在Kafka消费者中使用转换器将CDC数据转换为需要的格式。可以使用以下代码来使用转换器:
Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", "CDC"); KafkaConsumer<String> consumer = new KafkaConsumer<>(props, new StringDeserializer(), new StringDeserializer()); consumer.subscribe(Arrays.asList("CDC"));2023-08-17 10:54:38赞同 展开评论 -
北京阿里云ACE会长
Flink CDC 和 Kafka 都可以进行批处理,下面我将分别介绍它们如何进行批处理。
Flink CDC 批处理:
使用 Flink CDC 进行批处理,您可以将 CDC 数据以批量的形式进行处理。Flink 提供了批处理 API,例如 DataSet API 和 Table API,可以用于对批量数据进行转换和分析。
您可以使用 Flink CDC 捕获并保存一段时间内的变更事件,然后将其作为批量数据输入到 Flink 的批处理任务中进行处理。这样可以批量处理一段时间范围内的变更数据,例如每小时、每天或每周的数据。
在 Flink 批处理任务中,您可以使用各种转换算子(例如 Map、Filter、Reduce、Join 等)对批量数据进行处理和分析。此外,Flink 还提供了丰富的窗口操作和聚合功能,可以用于处理时间窗口内的批量数据。
Kafka 批处理:Kafka 本身是一个分布式流处理平台,但也可以用于批处理任务。
对于 Kafka 的批处理,您可以使用 Kafka 的消费者 API 来批量消费一批消息进行处理。您可以设置每次消费的批量大小,以控制一次处理的消息数量。
您可以编写 Kafka 消费者应用程序,使用消费者 API 从 Kafka 主题中获取一批消息并进行处理。在处理消息时,您可以使用适当的逻辑和算法对批量消息进行转换和分析。
另外,您还可以使用 Kafka Connect 连接器来将 Kafka 主题中的消息导入到批处理框架(如 Apache Flink)中进行处理。Kafka Connect 提供了各种连接器,可以将 Kafka 主题中的消息转发到其他系统或存储中,以供批处理任务使用。2023-08-14 18:57:53赞同 展开评论 -
Flink CDC 和 Kafka 都可以通过批处理方式来处理数据。下面我将分别介绍如何在 Flink CDC 和 Kafka 中实现批处理。
在 Flink CDC 中进行批处理,可以通过以下步骤来实现:
将 Flink CDC 的数据流转换为批处理数据集:使用 Flink 的 DataStream API 读取 Flink CDC 的数据流,并使用
window操作符将数据流划分为窗口。例如,您可以使用TimeWindow或TumblingEventTimeWindows来定义时间窗口,或者使用countWindow来定义记录数量窗口。对批处理数据集进行操作和计算:对于每个窗口中的数据集,您可以应用各种操作和计算,例如聚合、转换、过滤等。您可以使用 Flink 提供的各种算子和函数来执行所需的操作。
输出批处理结果:根据您的需求,您可以选择将批处理结果输出到不同的目标。例如,您可以将结果写入文件系统、数据库或消息队列等。
需要注意的是,这种批处理方式可能会引入一定的延迟,因为要等待窗口内的数据达到一定数量或时间后才进行处理。如果您对实时性要求较高,可以根据具体情况调整窗口大小和触发机制。
而在 Kafka 中进行批处理,可以通过以下方式来实现:
批量消费 Kafka 主题的消息:使用 Kafka 的 Consumer API,可以设置批量消费的配置参数。例如,您可以通过设置
fetch.min.bytes和fetch.max.wait.ms来控制每次拉取的最小字节数和最大等待时间。批量处理 Kafka 消息:对于每个批次的消息,您可以将其解析为数据集合,并应用相应的操作和计算。这可以使用您选择的编程和框架来完成。
输出批处理结果:根据您的需求,您可以选择将批处理结果输出到不同的目标。例如,您可以将结果写入文件系统、数据库或再次发送到另一个 Kafka 主题中。
需要注意的是,在进行批处理时,您可能需要考虑一些性能和资源方面的因素。例如,您可以调整批处理大小、并发度、消费者配置等来优化吞吐量和处理能力。
总而言之,无论是在 Flink CDC 还是 Kafka 中进行批处理,都需要根据具体的业务需求和场景进行相应的配置和实现。
2023-08-14 14:45:02赞同 展开评论 -
全栈JAVA领域创作者
Flink CDC和Kafka都可以进行批处理操作。具体来说,您可以使用Flink CDC和Kafka的相关API,对数据进行批处理操作。
在Flink CDC中,您可以使用batch参数,指定从数据源表中读取数据的批量大小。具体来说,您可以在StartupOptions中,指定batch参数和batchSize参数,以指定从数据源表中读取数据的批量大小。同时,您还可以使用Flink CDC提供的TableFunction接口,对读取到的数据进行特殊过滤,以避免出现表字段变少的情况。
在Kafka中,您可以使用Kafka的相关API,对数据进行批处理操作。具体来说,您可以使用Kafka的KafkaProducer和KafkaConsumer类,对数据进行读取和写入操作。同时,您还可以使用Kafka的Record类,对读取到的数据进行特殊处理,以满足您的业务需求。
需要注意的是,如果您使用Flink CDC和Kafka进行批处理操作,那么您需要注意数据的处理效率和准确性。同时,您还需要注意数据的安全性和可靠性,以保证数据的正确性和可靠性。2023-08-14 13:26:10赞同 展开评论
