
摘要:在很长一段时间内,语音识别领域最常用的模型是GMM-HMM。但近年来随着深度学习的发展,出现了越来越多基于神经网络的语音识别模型。
一、概述
在很长一段时间内,语音识别领域最常用的模型是GMM-HMM。但近年来随着深度学习的发展,出现了越来越多基于神经网络的语音识别模型。在各种神经网络类型中,RNN因其能捕捉序列数据的前后依赖信息而在声学模型中被广泛采用。用得最多的RNN模型包括LSTM、GRU等。但RNN在每一个时刻的计算都需要上一个时刻的输出作为输入,因此只能串行计算,速度很慢。
除此之外,相比于FNN等网络结构,RNN的训练易受梯度消失的影响,收敛得更慢,且需要更多的计算资源。前馈序列记忆神经网络(Feedforward Sequential Memory Networks, FSMN)[1][2]的提出,就是为了既能保留RNN对序列前后依赖关系的建模能力,又能加快模型的计算速度,降低计算复杂度。而之后提出的cFSMN[3]、DFSMN[4]和Pyramidal FSMN[5],都是在FSMN的基础上,进一步做出了改进和优化。FSMN、cFSMN和DFSMN都是中科大张仕良博士的工作,Pyramidal FSMN则是云从科技在2018年刷榜Librispeech数据集时提出的模型。
二、FSMN
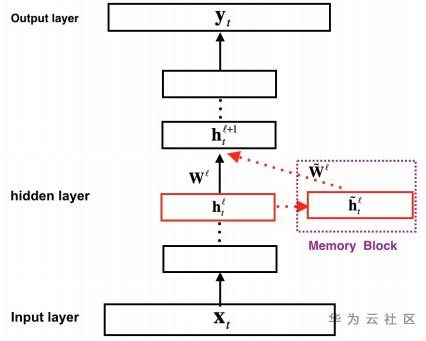
图1. FSMN模型结构
FSMN从本质上来说是一个前馈全连接网络(FNN),创新之处在于其隐藏层中增加了一个记忆模块(memory block)。记忆模块的作用是把每个隐藏状态的前后单元一并编码进来,从而实现对序列前后关系的捕捉。具体的计算流程如下:假设输入序列为,其中表示t时刻的输入数据,记对应的第层隐藏层状态为,则记忆模块的输出为:
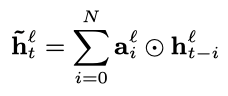
其中,表示逐元素相乘,是需要学习的系数参数。这是单向的FSMN,因为只考虑了t时刻过去的信息,若要考虑未来的信息,只需把t时刻之后的隐藏状态也用同样的方式进行添加,双向FSMN的计算公式如下:
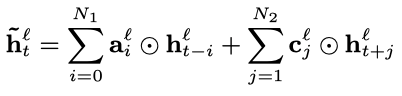
其中,表示考虑过去信息的阶数,表示考虑未来信息的阶数。记忆模块的输出可以视作t时刻的上下文的信息,与t时刻的隐藏层输出一起送入下一隐藏层。下一隐藏层的计算方式为:
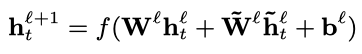
FSMN也可以与注意力机制相结合,此时记忆模块的参数以及输出的计算方式为:
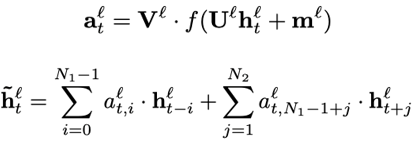
三、cFSMN
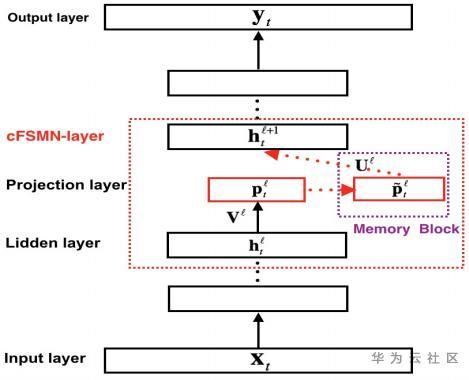
图2. cFSMN模型结构
为了进一步简化模型,压缩模型大小,提高训练和推理速度,cFSMN对FSMN主要做了两个改进:
通过对权重矩阵进行低秩矩阵分解,将隐藏层拆成两层;
在cFSMN层的计算中进行降维操作,并只把记忆模块的输出送入下一层,当前帧的隐藏状态不再直接送入下一层。
cFSMN层的具体计算步骤为:通过一个低秩线性变换将上一层的输出进行降维,得到的低维向量输入记忆模块,记忆模块的计算类似于FSMN,只是多加一个当前帧的低维向量来引入对齐信息。最后把记忆模块的输出进行一次仿射变换和一次非线性变换,作为当前层的输出。参照图2,每个步骤的计算公式如下:
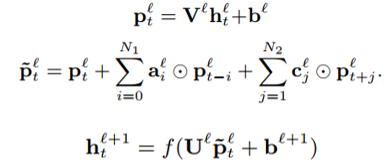
在Switchboard任务上,cFSMN可以在错误率低于FSMN的同时,模型大小缩减至FSMN模型的三分之一。
四、DFSMN
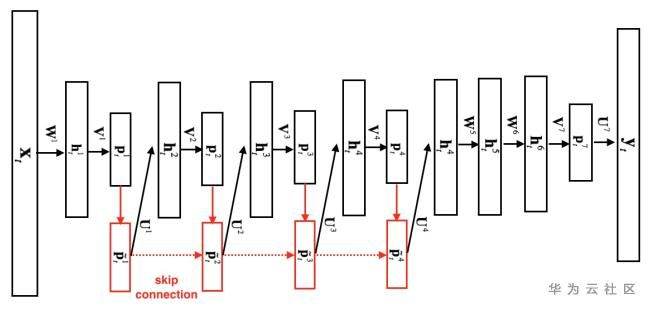
图3. DFSMN模型结构
顾名思义,DeepFSMN (DFSMN)的目的是希望构建一个更深的cFSMN网络结构。但通过直接堆叠cFSMN层很容易在训练时遇到梯度消失的情况,受残差网络(Residual Network)和高速网络(Highway Network)的启发,DFSMN在不同层的记忆模块之间添加了skip connection。同时,由于语音信号的相邻帧之间存在重叠和信息冗余,DFSMN仿照空洞卷积在记忆模块中引入了步幅因子(stride factor)。参照图3,第层记忆模块的计算方式为:
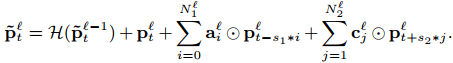
其中,表示skip connection操作,论文中选择的是恒等映射(identity mapping)。和分别是记忆模块在处理过去信息和未来信息时使用的步幅大小。
五、Pyramidal FSMN
Pyramidal FSMN(pFSMN)认为之前的FSMN系列模型的一个缺点是,底层和顶层的网络层都会去提取长期上下文信息,这就造成了重复操作。pFSMN提出了金字塔型的记忆模块,越深的网络层提取越高级的特征,即底层网络层提取音素信息,而顶层网络层提取语义信息和句法信息。这种金字塔结构可以同时提高精度、减少模型参数量。pFSMN减少了DSFMN中使用的skip connection的数量,只在记忆模块的维度发生变化时才进行skip connection操作。记忆模块的计算方式为:
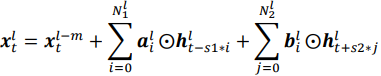
除了引入金字塔结构,pFSMN的另外两个改进是:
借鉴图像处理的方法,在FSMN层之前加入一个6层Residual CNN模块,用于提取更为鲁棒的语音特征,并通过降采样减少特征维度。
采用交叉熵损失(CE loss)和LF-MMI损失的加权平均来作为模型训练时使用的损失函数。引入CE loss的原因是训练序列数据时很容易出现过拟合的情况,CE loss相当于起到一个正则化的效果。
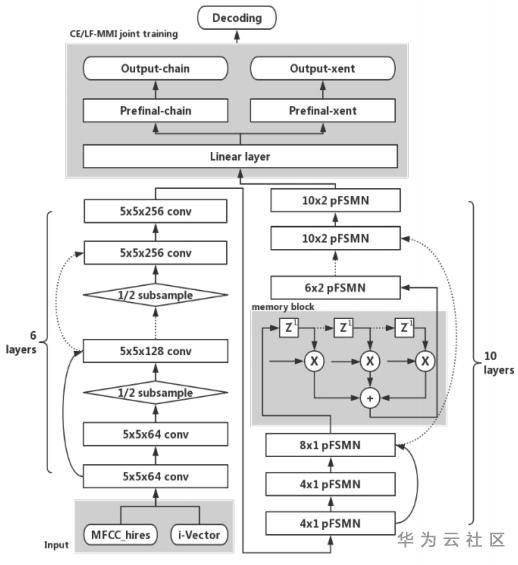
图4. Pyramidal FSMN模型结构
参考文献:
[1] Zhang S, Jiang H, Wei S, et al. Feedforward sequential memory neural networks without recurrent feedback[J]. arXiv preprint arXiv:1510.02693, 2015.
[2] Zhang S, Liu C, Jiang H, et al. Feedforward sequential memory networks: A new structure to learn long-term dependency[J]. arXiv preprint arXiv:1512.08301, 2015.
[3] Zhang S, Jiang H, Xiong S, et al. Compact Feedforward Sequential Memory Networks for Large Vocabulary Continuous Speech Recognition[C]//Interspeech. 2016: 3389-3393.
[4] Zhang S, Lei M, Yan Z, et al. Deep-fsmn for large vocabulary continuous speech recognition[C]//2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018: 5869-5873.
[5] Yang X, Li J, Zhou X. A novel pyramidal-FSMN architecture with lattice-free MMI for speech recognition[J]. arXiv preprint arXiv:1810.11352, 2018.
————————————————
原文链接:https://blog.csdn.net/devcloud/article/details/110524062

