
请问大佬,flinkcdc-mongo有没有办法监控到采集的堆积/延时情况?举个例子,假如当前采集的
请问大佬,flinkcdc-mongo有没有办法监控到采集的堆积/延时情况?举个例子,假如当前采集的数据事件时间远早于现在n个小时,那么可以认为cdc采集任务阻塞了n个小时,期望能早于业务方收到报警。 mongoshake的策略是开放了一个端口可以查询到延时,不知flinkcdc-mongo有没有metrics指标可以用?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
link CDC for MongoDB(flinkcdc-mongo)提供了一些监控指标来帮助您监控采集的堆积和延迟情况。您可以使用Flink的Metrics系统来收集和监控这些指标。
以下是一些相关的指标,您可以使用Flink的Metrics系统来获取它们:
- cdc-mongo-num-total-operations: 当前正在处理的操作数量。
- cdc-mongo-num-queued-operations: 当前排队等待处理的操作数量。
- cdc-mongo-last-applied-offset: 最后一次应用的偏移量,用于计算延迟。
- cdc-mongo-max-applied-offset: 最大应用的偏移量,用于计算延迟。
- cdc-mongo-min-applied-offset: 最小应用的偏移量,用于计算延迟。
您可以使用这些指标来计算延迟并触发报警。比如,您可以编写一个定时任务,检查最后一次应用的偏移量和当前时间的差值,如果超过预设的阈值,就触发报警。
2023-08-26 21:29:07赞同 展开评论 -
十分耕耘,一定会有一分收获!
楼主你好,阿里云flinkcdc-mongo可以使用Flink的Metrics体系来监控数据采集的堆积/延时情况,支持以下指标:
records-lag-max:表示当前最大的事件时间与当前时间之间的延时,单位是毫秒。
records-processed-total:表示已经处理的事件数。
records-emitted-total:表示已经输出的事件数。
通过监控 records-lag-max 指标可以实时查看cdc采集任务的延时情况,当延时超过一定阈值时,可以及时发出报警。具体可以参考以下代码示例:
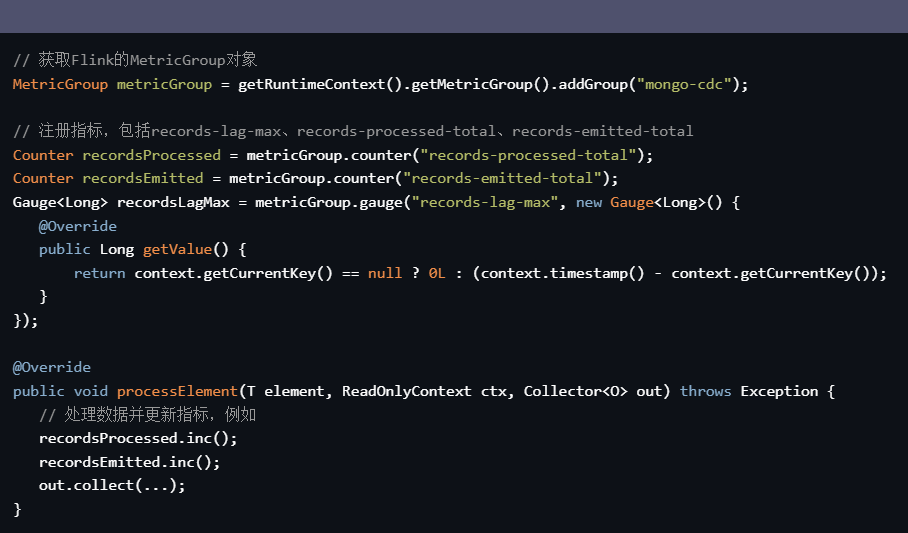
// 获取Flink的MetricGroup对象 MetricGroup metricGroup = getRuntimeContext().getMetricGroup().addGroup("mongo-cdc"); // 注册指标,包括records-lag-max、records-processed-total、records-emitted-total Counter recordsProcessed = metricGroup.counter("records-processed-total"); Counter recordsEmitted = metricGroup.counter("records-emitted-total"); Gauge<Long> recordsLagMax = metricGroup.gauge("records-lag-max", new Gauge<Long>() { @Override public Long getValue() { return context.getCurrentKey() == null ? 0L : (context.timestamp() - context.getCurrentKey()); } }); @Override public void processElement(T element, ReadOnlyContext ctx, Collector<O> out) throws Exception { // 处理数据并更新指标,例如 recordsProcessed.inc(); recordsEmitted.inc(); out.collect(...); }使用以上的指标可以快速监控阿里云flinkcdc-mongo采集任务的延时情况,并及时发出报警。
2023-08-21 14:26:13赞同 展开评论 -
FlinkCDC-Mongo提供了Metrics指标来监控采集的延迟情况。可以通过Flink监控面板或其他类似Prometheus的监控系统来收集并展示这些指标。
具体而言,FlinkCDC-Mongo可以监控到每个collection的采集延迟和每个source任务的采集延迟。可以使用flink.taskmanager.numSlots和source.parallelism参数来控制CDCEngine任务的并行,从而分配更多的任务从而降低延迟。此外,当延迟达到一定程度时,可以通过触发报警机制及时通知业务方。
2023-08-18 11:51:28赞同 展开评论 -
Flink CDC for MongoDB 支持使用 Flink 提供的监控指标来监控采集任务的堆积和延时情况。具体来说,可以通过 Flink 的 Metrics 系统来获取以下指标:
mongodb-cdc-num-pending-splits:当前等待分片的数量。mongodb-cdc-num-pending-oplog-records:当前等待处理的 oplog 记录数量。mongodb-cdc-last-offset:最近一条已处理的 oplog 记录的 offset。
通过这些指标,可以了解当前采集任务的堆积和延时情况,并及时发出报警。
Flink CDC for MongoDB 还支持将采集任务的状态信息输出到外部系统,如 InfluxDB、Prometheus 等,以便更方便地进行监控和报警。具体可以参考 Flink 的 Metrics 系统和 Flink CDC 的文档进行配置。
 2023-08-17 16:43:58赞同 展开评论
2023-08-17 16:43:58赞同 展开评论 -
Flink CDC 对于监控采集的堆积和延迟情况提供了一些可用的指标和度量信息。您可以使用 Flink 的内置 Metrics 系统来获取这些指标,并根据需要进行报警或监控。
以下是一些与延迟相关的指标,您可以在 Flink CDC 中收集和使用:
cdc-consumer-delay:表示消费者(即 Flink CDC 作业)处理数据时的延迟情况。该指标可以告诉您当前数据流程的处理速度是否跟得上数据产生的速度。cdc-max-event-time-lag:表示事件时间与最新到达的事件之间的延迟。通过比较事件时间字段与当前时间的差值,可以判断数据的处理是否有延迟。
您可以使用 Flink 的 Metrics 系统将这些指标公开给外部监控系统,如 Prometheus、Grafana 等。借助这些监控工具,您可以设置阈值和警报规则,以便及时发现和处理延迟问题。
另外,在 Flink CDC 中,您也可以自定义度量器(Metric),根据您的需求添加任意指标。通过实现自定义度量器接口,您可以收集更多特定的监控数据,以满足您对延迟和堆积情况的监控要求。
2023-08-16 22:45:22赞同 展开评论 -
北京阿里云ACE会长
在 Flink CDC 中,可以使用 Flink 的度量指标(metrics)来监控采集的堆积和延迟情况。Flink 提供了丰富的度量指标来衡量作业执行的各个方面,包括源(source)的延迟和堆积情况。
对于 Flink CDC 集成的 MongoDB Connector,你可以使用以下度量指标来监控采集的延迟和堆积情况:
mongodb-cdc--last-offset: 这个度量指标表示源的最后一个读取的偏移量(offset),可以用于衡量当前已采集的进度。通过比较当前偏移量和实际数据事件时间的差距,可以估计采集任务的延迟情况。
mongodb-cdc--num-pending-splits: 这个度量指标表示当前正在等待处理的分片数量,可以用于衡量采集任务的堆积情况。如果分片堆积数量较大,则可能表示采集任务的处理能力不足或存在其他问题。
这些度量指标可以通过 Flink 的监控界面(如 Flink Web Dashboard)或者通过 Flink 的 REST API 获取。你可以定期监控这些指标,并设置警报机制来及时发现延迟或堆积超过预期的情况。
请注意,具体的度量指标名称可能会根据你的 Flink CDC 和 MongoDB Connector 版本略有不同。建议查阅相关版本的文档以获取准确的度量指标名称和用法。
2023-08-14 19:12:58赞同 展开评论 -
Flink CDC for MongoDB本身并没有直接提供监控延时的功能。但是,我们可以通过一些方法来间接地监控延时情况。以下是一些建议:
使用MongoDB的延时分析工具:MongoDB提供了一个名为“延时分析”的功能,可以在一个特定的端口上暴露延迟情况。这个端口是一个HTTP服务,可以返回一个包含所有慢查询的列表。你可以在Flink CDC的MongoDB连接器中配置这个端口,然后定期检查这个端口上的输出,以了解是否有任何慢查询。
使用Prometheus和Grafana:你可以使用Prometheus和Grafana这样的开源工具来监控Flink CDC的性能。这些工具可以收集各种性能指标,包括延时。你可以设置一个阈值,一旦延时超过这个阈值,就发送报警通知。
编写自定义的监控逻辑:你可以编写自己的监控逻辑,用于检查Flink CDC的延时情况。例如,你可以每隔一段时间执行一次批处理操作,然后比较实际的开始时间和预期的开始时间。如果延时超过某个阈值,就可以发出警报。
2023-08-14 15:40:37赞同 展开评论 -
全栈JAVA领域创作者
是的,Flink CDC-mongo支持监控采集的堆积/延时情况。您可以使用Flink CDC-mongo提供的MongoSink类,将采集的数据写入MongoDB中。在MongoSink类中,您可以设置writeDelay参数,指定数据写入MongoDB的延时时间。如果数据写入MongoDB的延时时间超过了writeDelay参数指定的时间,那么就可以认为Flink CDC-mongo采集任务阻塞了一段时间。
同时,您还可以使用Flink提供的Checkpoint机制,定期对Flink CDC-mongo的状态进行检查点,以便在出现问题时可以快速恢复。在Flink中,您可以使用Checkpoint机制,将Flink CDC-mongo的状态保存到文件中,以便在重启Flink时可以恢复到最近的检查点状态。
需要注意的是,不同的情况可能需要不同的解决方案,因此需要根据具体情况进行调整和优化。同时,您可以使用Flink CDC-mongo提供的MongoSink类,自定义一个MongoSink实现类,对写入MongoDB的数据进行特殊处理,以避免出现延时/堆积的情况。2023-08-14 13:09:17赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
