
面试题
分库分表之后,id 主键如何处理?
面试官心理分析
其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个全局唯一的 id 来支持。所以这都是你实际生产环境中必须考虑的问题。
面试题剖析
基于数据库的实现方案
数据库自增 id
这个就是说你的系统里每次得到一个 id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个 id。拿到这个 id 之后再往对应的分库分表里去写入。
这个方案的好处就是方便简单,谁都会用;缺点就是单库生成自增 id,要是高并发的话,就会有瓶颈的;如果你硬是要改进一下,那么就专门开一个服务出来,这个服务每次就拿到当前 id 最大值,然后自己递增几个 id,一次性返回一批 id,然后再把当前最大 id 值修改成递增几个 id 之后的一个值;但是无论如何都是基于单个数据库。
适合的场景:你分库分表就俩原因,要不就是单库并发太高,要不就是单库数据量太大;除非是你并发不高,但是数据量太大导致的分库分表扩容,你可以用这个方案,因为可能每秒最高并发最多就几百,那么就走单独的一个库和表生成自增主键即可。
设置数据库 sequence 或者表自增字段步长
可以通过设置数据库 sequence 或者表的自增字段步长来进行水平伸缩。
比如说,现在有 8 个服务节点,每个服务节点使用一个 sequence 功能来产生 ID,每个 sequence 的起始 ID 不同,并且依次递增,步长都是 8。
适合的场景:在用户防止产生的 ID 重复时,这种方案实现起来比较简单,也能达到性能目标。但是服务节点固定,步长也固定,将来如果还要增加服务节点,就不好搞了。
UUID
好处就是本地生成,不要基于数据库来了;不好之处就是,UUID 太长了、占用空间大,作为主键性能太差了;更重要的是,UUID 不具有有序性,会导致 B+ 树索引在写的时候有过多的随机写操作(连续的 ID 可以产生部分顺序写),还有,由于在写的时候不能产生有顺序的 append 操作,而需要进行 insert 操作,将会读取整个 B+ 树节点到内存,在插入这条记录后会将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显。
适合的场景:如果你是要随机生成个什么文件名、编号之类的,你可以用 UUID,但是作为主键是不能用 UUID 的。
UUID.randomUUID().toString().replace("-", "") -> sfsdf23423rr234sfdaf
获取系统当前时间
这个就是获取当前时间即可,但是问题是,并发很高的时候,比如一秒并发几千,会有重复的情况,这个是肯定不合适的。基本就不用考虑了。
适合的场景:一般如果用这个方案,是将当前时间跟很多其他的业务字段拼接起来,作为一个 id,如果业务上你觉得可以接受,那么也是可以的。你可以将别的业务字段值跟当前时间拼接起来,组成一个全局唯一的编号。
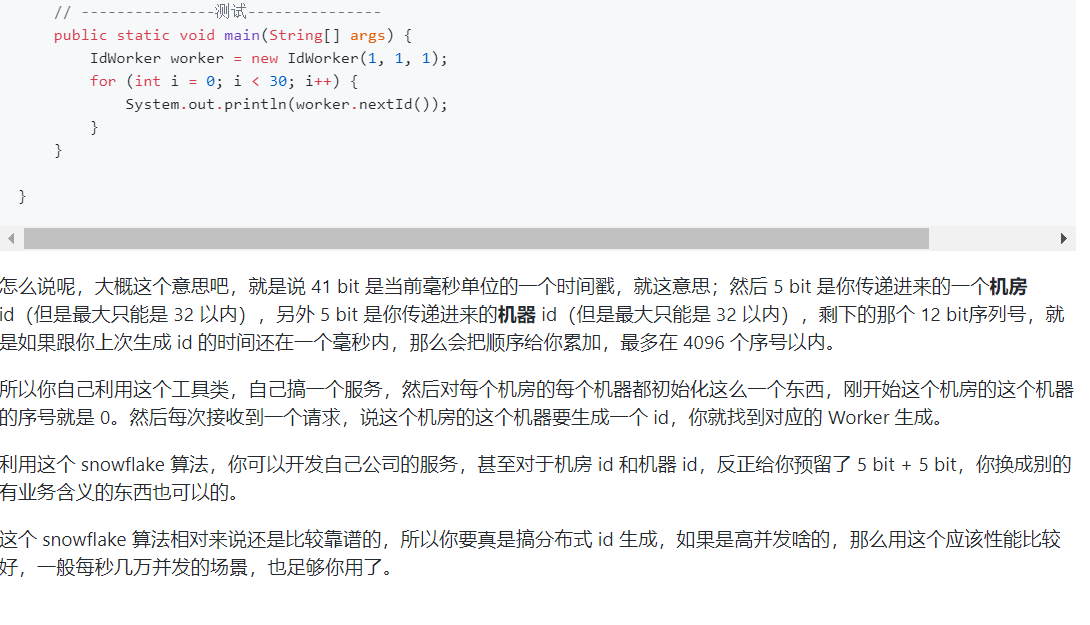
snowflake 算法
snowflake 算法是 twitter 开源的分布式 id 生成算法,采用 Scala 语言实现,是把一个 64 位的 long 型的 id,1 个 bit 是不用的,用其中的 41 bits 作为毫秒数,用 10 bits 作为工作机器 id,12 bits 作为序列号。
1 bit:不用,为啥呢?因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0。
41 bits:表示的是时间戳,单位是毫秒。41 bits 可以表示的数字多达 2^41 - 1 ,也就是可以标识 2^41 - 1 个毫秒值,换算成年就是表示69年的时间。
10 bits:记录工作机器 id,代表的是这个服务最多可以部署在 2^10 台机器上,也就是 1024 台机器。但是 10 bits 里 5 个 bits 代表机房 id,5 个 bits 代表机器 id。意思就是最多代表 2^5 个机房(32 个机房),每个机房里可以代表 2^5 个机器(32台机器)。
12 bits:这个是用来记录同一个毫秒内产生的不同 id,12 bits 可以代表的最大正整数是 2^12 - 1 = 4096 ,也就是说可以用这个 12 bits 代表的数字来区分同一个毫秒内的 4096 个不同的 id。
0 | 0001100 10100010 10111110 10001001 01011100 00 | 10001 | 1 1001 | 0000 00000000


往期回顾:
【Java问答学堂】1期 为什么使用消息队列?消息队列有什么优点和缺点?Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么区别,以及适合哪些场景?
【Java问答学堂】3期 如何保证消息不被重复消费?或者说,如何保证消息消费的幂等性?
【Java问答学堂】4期 如何保证消息的可靠性传输?(如何处理消息丢失的问题?)
【Java问答学堂】6期 如何解决消息队列的延时以及过期失效问题?
【Java问答学堂】7期 如果让你写一个消息队列,该如何进行架构设计?
【Java问答学堂】8期 es 的分布式架构原理能说一下么(es 是如何实现分布式的啊)?
【Java问答学堂】9期 es 写入数据的工作原理是什么啊?es 查询数据的工作原理是什么啊?
【Java问答学堂】10期 es 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
【Java问答学堂】11期 es 生产集群的部署架构是什么?每个索引的数据量大概有多少?
【Java问答学堂】12期 项目中缓存是如何使用的?为什么要用缓存?缓存使用不当会造成什么后果?
【Java问答学堂】13期 redis 和 memcached 有什么区别?
【Java问答学堂】14期 redis 都有哪些数据类型?分别在哪些场景下使用比较合适?
【Java问答学堂】15期redis 的过期策略都有哪些?内存淘汰机制都有哪些?
【Java问答学堂】16期如何保证 redis 的高并发和高可用?redis 的主从复制原理能介绍
Kafka、ActiveMQ、RabbitMQ、RocketMQ的区别?【Java问答学堂】19期
如何保证消息不被重复消费?或者说,如何保证消息消费的幂等性?【Java问答学堂】21期
如何保证消息的可靠性传输?或者说,如何处理消息丢失的问题?【Java问答学堂】22期
如何解决消息队列的延时以及过期失效问题?【Java问答学堂】24期
如果让你写一个消息队列,该如何进行架构设计?【Java问答学堂】25期
ES 的分布式架构原理能说一下么(ES 是如何实现分布式的啊)?【Java问答学堂】26期
ES 写入数据的工作原理是什么啊?ES 查询数据的工作原理是什么啊?【Java问答学堂】27期
ES 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?【Java问答学堂】28期
ES 生产集群的部署架构是什么?每个索引的数据量大概有多少?【Java问答学堂】29期
项目中缓存是如何使用的?为什么要用缓存?缓存使用不当会造成什么后果?【Java问答学堂】30期
Redis 和 Memcached 的区别?Redis 的线程模型是什么?【Java问答学堂】31期
Redis 都有哪些数据类型?分别在哪些场景下使用比较合适?【Java问答学堂】32期
Redis 的过期策略都有哪些?内存淘汰机制都有哪些?手写一下 LRU 代码实现?【Java问答】33期
如何保证 redis 的高并发和高可用?【Java问答】34期
Redis 集群模式的工作原理能说一下么?【Java问答】36期
了解什么是 Redis 的雪崩、穿透和击穿?Redis 崩溃之后会怎么样?【Java问答】37期
Redis 的并发竞争问题是什么?如何解决这个问题?【Java问答】39期
生产环境中的 Redis 是怎么部署的?【Java问答】40期
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

