
《用80行Haskell击败C:wc》一文在互联网是引起热议,掀起了一场用不用语言尝试打败wc的游戏。
下面我们就来看看GO语言如何用70行代码击败C语言。
基准和比较
我们将使用GNU time实用程序来比较经过时间和最大居民集大小。
$ /usr/bin/time -f "%es %MKB" wc test.txt
版本:go 1.13.4
所有测试都是在以下配置上进行的:
Intel Core i5-6200U @ 2.30 GHz (2 physical cores, 4 threads)
4+4 GB RAM @ 2133 MHz
240 GB M.2 SSD
Fedora 31
为了公平对比,所有的实现都会使用一个 16 KB 的 buffer 读取两个 us-ascii 编码的文本文件(一个 100 MB,一个 1 GB)的输入。
天真的办法
解析参数很容易,因为我们只需要文件路径:
if len(os.Args) < 2 {
panic("no file path specified")
}
filePath := os.Args[1]
file, err := os.Open(filePath)
if err != nil {
panic(err)
}
defer file.Close()
我们将按字节顺序遍历文本,以跟踪状态。幸运的是,在这种情况下,我们只需要2个状态:
前一个字节是空格
前一个字节不是空格
从空白字符变为非空白字符时,我们增加字计数器。这种方法使我们可以直接从字节流读取数据,从而保持较低的内存消耗。
const bufferSize = 16 * 1024
reader := bufio.NewReaderSize(file, bufferSize)
lineCount := 0
wordCount := 0
byteCount := 0
prevByteIsSpace := true
for {
b, err := reader.ReadByte()
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
byteCount++
switch b {
case '\n':
lineCount++
prevByteIsSpace = true
case ' ', '\t', '\r', '\v', '\f':
prevByteIsSpace = true
default:
if prevByteIsSpace {
wordCount++
prevByteIsSpace = false
}
}
}
为了显示结果,我们将使用本机println()函数-在我的测试中,导入fmt库导致可执行文件大小增加了约400 KB!
println(lineCount, wordCount, byteCount, file.Name())
让我们运行这个:
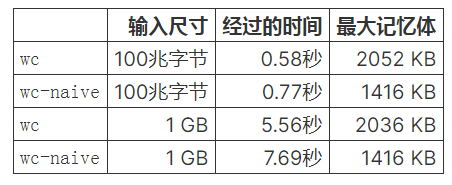
我们的第一次尝试已经使我们在性能上接近C。实际上,在内存使用方面,我们实际上做得更好!
分割输入
虽说缓存 I/O 的读取对于提高性能至关重要,但调用 ReadByte() 并在循环中查找错误会带来很多不必要的开销。为了避免这种情况的发生,我们可以手动缓存我们的读取调用,而不是依赖 bufio.Reader。
为了做到这点,我们将输入分割到可以分别处理的多个缓冲 chunk 中。幸运的是,我们只需要知道前一 chunk 中的最后一个字符是否是空格,就可以处理当前 chunk。
接下来是一些功能函数:
type Chunk struct {
PrevCharIsSpace bool
Buffer []byte
}
type Count struct {
LineCount int
WordCount int
}
func GetCount(chunk Chunk) Count {
count := Count{}
prevCharIsSpace := chunk.PrevCharIsSpace
for _, b := range chunk.Buffer {
switch b {
case '\n':
count.LineCount++
prevCharIsSpace = true
case ' ', '\t', '\r', '\v', '\f':
prevCharIsSpace = true
default:
if prevCharIsSpace {
prevCharIsSpace = false
count.WordCount++
}
}
}
return count
}
func IsSpace(b byte) bool {
return b == ' ' || b == '\t' || b == '\n' || b == '\r' || b == '\v' || b == '\f'
}
现在,我们可以将输入拆分为Chunks并将它们提供给GetCount函数。
totalCount := Count{}
lastCharIsSpace := true
const bufferSize = 16 * 1024
buffer := make([]byte, bufferSize)
for {
bytes, err := file.Read(buffer)
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
count := GetCount(Chunk{lastCharIsSpace, buffer[:bytes]})
lastCharIsSpace = IsSpace(buffer[bytes-1])
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
为了获得字节数,我们可以进行一个系统调用来查询文件大小:
fileStat, err := file.Stat()
if err != nil {
panic(err)
}
byteCount := fileStat.Size()
现在我们完成了,让我们看看它是如何执行的:
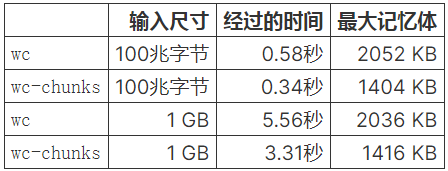
看起来我们在这两个方面都超过了 wc,而且这还是没有并行化程序的情况下。 tokei 的报告显示该程序只有 70 行代码!
并行化
无可否认,并行化的 wc 是多余的但是让我们看看我们能走多远。原始文章从输入文件中并行读取数据,尽管它改善了运行时间,但作者确实承认由于并行读取而导致的性能提升可能仅限于某些类型的存储,而在其他地方则是有害的。
对于我们的实现,我们希望我们的代码在所有设备上都具有高性能,因此我们不会这样做。我们将建立2个频道,chunks并counts。每个工作人员将读取并处理chunks直到关闭通道为止的数据,然后将结果写入counts。
func ChunkCounter(chunks <-chan Chunk, counts chan<- Count) {
totalCount := Count{}
for {
chunk, ok := <-chunks
if !ok {
break
}
count := GetCount(chunk)
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
counts <- totalCount
}
我们将为每个逻辑CPU内核产生一个工作线程:
numWorkers := runtime.NumCPU()
chunks := make(chan Chunk)
counts := make(chan Count)
for i := 0; i < numWorkers; i++ {
go ChunkCounter(chunks, counts)
}
现在,我们循环运行,从磁盘读取数据并将作业分配给每个工作程序:
const bufferSize = 16 * 1024
lastCharIsSpace := true
for {
buffer := make([]byte, bufferSize)
bytes, err := file.Read(buffer)
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
chunks <- Chunk{lastCharIsSpace, buffer[:bytes]}
lastCharIsSpace = IsSpace(buffer[bytes-1])
}
close(chunks)
完成此操作后,我们可以简单地汇总每个工人的计数:
totalCount := Count{}
for i := 0; i < numWorkers; i++ {
count := <-counts
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
close(counts)
让我们运行它,看看它与以前的结果如何比较:
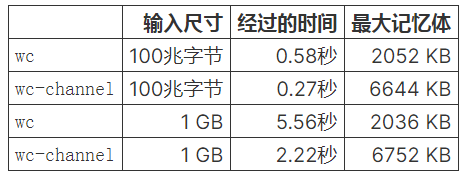
现在wc的速度要快了很多,但是内存使用率已经大大降低了。特别要注意的是,我们的输入循环如何在每次迭代中分配内存!通道是共享内存的绝佳抽象,但是对于某些用例,简单地不使用通道可以极大地提高性能。
更好的并行化
将允许每个工作程序读取文件,并使用sync.Mutex来确保不会同时发生读取。我们可以创建一个新的东西struct来为我们处理:
type FileReader struct {
File *os.File
LastCharIsSpace bool
mutex sync.Mutex
}
func (fileReader *FileReader) ReadChunk(buffer []byte) (Chunk, error) {
fileReader.mutex.Lock()
defer fileReader.mutex.Unlock()
bytes, err := fileReader.File.Read(buffer)
if err != nil {
return Chunk{}, err
}
chunk := Chunk{fileReader.LastCharIsSpace, buffer[:bytes]}
fileReader.LastCharIsSpace = IsSpace(buffer[bytes-1])
return chunk, nil
}
然后,我们重写工作函数以直接从文件读取:
func FileReaderCounter(fileReader *FileReader, counts chan Count) {
const bufferSize = 16 * 1024
buffer := make([]byte, bufferSize)
totalCount := Count{}
for {
chunk, err := fileReader.ReadChunk(buffer)
if err != nil {
if err == io.EOF {
break
} else {
panic(err)
}
}
count := GetCount(chunk)
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
counts <- totalCount
}
像之前一样,我们现在可以生成这些工作线程,每个CPU内核一个:
fileReader := &FileReader{
File: file,
LastCharIsSpace: true,
}
counts := make(chan Count)
for i := 0; i < numWorkers; i++ {
go FileReaderCounter(fileReader, counts)
}
totalCount := Count{}
for i := 0; i < numWorkers; i++ {
count := <-counts
totalCount.LineCount += count.LineCount
totalCount.WordCount += count.WordCount
}
close(counts)
让我们看看它如何执行:
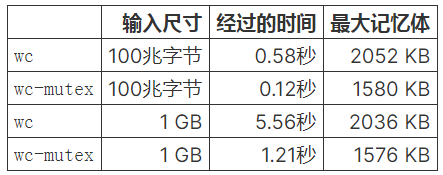
我们的并行化实现的运行速度是的4.5倍以上wc,并且内存消耗更低!这非常重要,特别是如果您认为Go是一种垃圾收集语言。
结论
并分暗示Go> C,但我希望它证明Go可以替代C作为系统编程语言。
加入阿里云钉钉群享福利:每周技术直播,定期群内有奖活动、大咖问答

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
