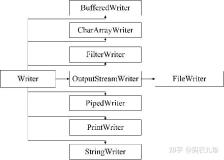
7.3. Consensus(共识性)与 Volatile

最后终于来到我们所熟悉的 Volatile 了,Volatile 其实就是在 Release/Acquire 的基础上,进一步保证了 Consensus;Consensus 即所有线程看到的内存更新顺序是一致的,即所有线程看到的内存顺序全局一致,举个例子:假设某个对象字段 int x 初始为 0,int y 也初始为 0,这两个字段不在同一个缓存行中(后面的 jcstress 框架会自动帮我们进行缓存行填充),一个线程执行:

另一个执行:

在 Java 内存模型下,同样可能有4种结果:
r1 = 1, r2 = 1r1 = 0, r2 = 1r1 = 1, r2 = 0r1 = 0, r2 = 0
第四个结果比较有意思,他是不符合 Consensus 的,因为两个线程看到的更新顺序不一样(第一个线程看到 0 代表他认为 x 的更新是在 y 的更新之前执行的,第二个线程看到 0 代表他认为 y 的更新是在 x 的更新之前执行的)。如果没有乱序,那么肯定不会看到 x, y 都是 0,因为线程 1 和线程 2 都是先更新后读取的。但是也正如前面所有的讲述一样,各种乱序造成了我们可以看大第三个这样的结果。那么 Release/Acquire 能否保证不会出现这样的结果呢?我们来简单分析下,如果对于 x,y 的访问都是 Release/Acquire 模式的,那么线程 1 实际执行的就是:

这里我们就可以看出来,x = 1 与 int r1 = y 之间没有任何内存屏障,所以实际可能执行的是:

同理,线程 2 可能执行的是:

或者:

这样,就会造成我们可能看到第四种结果。我们通过代码测试下:

测试结果是:

如果要保证 Consensus,我们只要保证线程 1 的代码与线程 2 的代码不乱序即可,即在原本的内存屏障的基础上,添加 StoreLoad 内存屏障,即线程 1 执行:

线程 2 执行:

这样就能保证不会乱序,这其实就是 volatile 访问了。Volatile 访问即在 Release/Acquire 的基础上增加 StoreLoad 屏障,我们来测试下:

结果是:

那么引出另一个问题,这个 StoreLoad 屏障是 Volatile Store 之后添加,还是 Volatile Load 之前添加呢?我们来做下这个实验:
首先保留 Volatile Store,将 Volatile Load 改成 Plain Load,即:

测试结果:

从结果中可以看出,仍然保持了 Consensus。再来看保留 Volatile Load,将 Volatile Store 改成 Plain Store:

测试结果:

发现又乱序了。
所以,可以得出结论,这个 StoreLoad 是加在 Volatile 写之后的,在后面的 JVM 底层源码分析我们也能看出来。
7.4 Final 的作用
Java 中,创建对象通过调用类的构造函数实现,我们还可能在构造函数中放一些初始化一些字段的值,例如:

我们可以这样调用构造器创建一个对象:

我们合并这些步骤,用伪代码表示底层实际执行的是:

他们之间,没有任何内存屏障,同时根据语义分析,1 和 5 之间有依赖关系,所以 1 和 5 的前后顺序不能变。1,2,3,4 之间有依赖,所以 1,2,3,4 的前后顺序也不能变。2,3,4 与 5 之间,没有任何关系,他们之间的执行顺序是可能乱序的。如果 5 在 2,3,4 中的任一一步之前执行,那么就会造成我们可能看到构造器还未执行完,x,y,z 还是初始值的情况。测试下:

在 x86 平台的测试结果,你只会看到两个结果,即 -1, -1, -1(代表没看到对象初始化)和 1, 2, 3(看到对象初始化,并且没有乱序),结果如下图所示(AMD64 是一种 x86 的实现):

这是因为,前文我们也提到过类似的, x86 CPU 是比较强一致性的 CPU,这里不会乱序。至于由于 x86 哪种不乱序性质这里才不乱序,我们后面会看到。
还是和前文一样,我们换到不那么强一致性的 CPU (ARM)上执行,这里看到的结果就比较热闹了,如下图所示(aarch64 是一种 ARM 实现):

那我们如何保证看到构造器执行完的结果呢?
用前面的内存屏障设计,我们可以把伪代码的第五步改成 setRelease,即:

前面我们提到过 setRelease 会在前面加上 LoadStore 和 StoreStore 屏障,StoreStore 屏障会防止 2,3,4 与 5 乱序,所以可以避免这个问题,我们来试试看:

再到前面的 aarch64 机器上试一下,结果是:

从结果可以看出,只能看到要么没初始化,要么完整的构造器执行后的结果了。
我们再进一步,其实我们这里只需要 StoreStore 屏障就够了,由此引出了 Java 的 final 关键字:final 其实就是在更新后面紧接着加入 StoreStore 屏障,这样也相当于在构造器结束之前加入 StoreStore 屏障,保证了只要我们能看到对象,对象的构造器一定是执行完了的。测试代码:

我们再进一步,由于伪代码中 2,3,4 是互相依赖的,所以这里我们只要保证 4 先于 5 执行,那么2,3,一定先于 5 执行,也就是我们只需要对 z 设置为 final,从而加 StoreStore 内存屏障,而不是每个都声明为 final,从而多加内存屏障:

然后,我们继续用 aarch64 测试,测试结果依然是对的:

最后我们需要注意,final 仅仅是在更新后面加上 StoreStore 屏障,如果你在构造器过程中,将 this 暴露了出去,那么还是会看到 final 的值没有初始化,我们测试下:

这次我们在 x86 的机器上就能看到 final 没有初始化:

最后,为何这里的示例中 x86 不需要内存屏障就能实现,参考前面的 CPU 图:

x86 本身 Store 与 Store 之间就不会乱序,天然就有保证。
最后给上表格:

8. 底层 JVM 实现分析
8.1. JVM 中的 OrderAccess 定义
JVM 中有各种用到内存屏障的地方:
- 实现 Java 的各种语法元素(volatile,final,synchronized,等等)
- 实现 JDK 的各种 API(VarHandle,Unsafe,Thread,等等)
- GC 需要的内存屏障:因为要考虑 GC 多线程与应用线程(在 GC 算法中叫做 Mutator)的工作方式,究竟是停止世界(Stop-the-world, STW)的方式,还是并发的方式
- 对象引用屏障:例如分代 GC,复制算法,年轻代 GC 的时候我们一般是从一个 S 区复制存活对象到另一个 S 区,如果复制的过程,我们不想停止世界(Stop-the-world, STW),而是和应用线程同时进行,那么我们就需要内存屏障,例如;
- 维护屏障:例如分区 GC 算法,我们需要维护每个区的跨区引用表以及使用情况表,例如 Card Table。这个如果我们想要应用线程与 GC 线程并发修改访问,而不是停止世界,那么也需要内存屏障。
- JIT 也需要内存屏障:同样地,应用线程究竟是解释执行代码还是执行 JIT 优化后的代码,这里也是需要内存屏障的。
这些内存屏障,不同的 CPU,不同的操作系统,底层需要不同的代码实现,统一的接口设计是:
f="https://github.com/openjdk/jdk/blob/master/src/hotspot/share/runtime/orderAccess.hpp">源代码地址:orderAccess.hpp

不同的 CPU,不同的操作系统实现是不一样的,结合前面 CPU 乱序表格:

我们来看下 linux + x86 的实现:
f="https://github.com/openjdk/jdk/blob/master/src/hotspot/os_cpu/linux_x86/orderAccess_linux_x86.hpp">源代码地址:orderAccess_linux_x86.hpp

对于 x86,由于 Load 与 Load,Load 与 Store,Store 与 Store 本来有一致性保证,所以只要没有编译器乱序,那么就天生有 StoreStore,LoadLoad,LoadStore 屏障,所以这里我们看到 StoreStore,LoadLoad,LoadStore 屏障的实现都只是加了编译器屏障。同时,前文中我们分析过,acquire 其实就是相当于在 Load 后面加上 LoadLoad,LoadStore 屏障,对于 x86 还是需要编译器屏障就够了。release 我们前文中也分析过,其实相当于在 Store 前面加上 LoadStore 和 StoreStore,对于 x86 还是需要编译器屏障就够了。于是,我们有如下表格:
我们再看下前面我们经常使用的 Linux aarch64 下的实现:
f="https://github.com/openjdk/jdk/blob/master/src/hotspot/os_cpu/linux_aarch64/orderAccess_linux_aarch64.hpp">源代码地址:orderAccess_linux_aarch64.hpp

如前面表格里面说,ARM 的 CPU Load 与 Load,Load 与 Store,Store 与 Store,Store 与 Load 都会乱序。JVM 针对 aarch64 没有直接使用 CPU 指令,而是使用了 C++ 封装好的内存屏障实现。C++ 封装好的很像我们前面讲的简易 CPU 模型的内存屏障,即读内存屏障(__atomic_thread_fence(__ATOMIC_ACQUIRE)),写内存屏障(__atomic_thread_fence(__ATOMIC_RELEASE)),读写内存屏障(全内存屏障,__sync_synchronize())。acquire 的作用是作为接收点解包让后面的都看到包里面的内容,类比简易 CPU 模型,其实就是阻塞等待 invalidate queue 完全处理完保证 CPU 缓存没有脏数据。release 的作用是作为发射点将前面的更新打包发出去,类比简易 CPU 模型,其实就是阻塞等待 store buffer 完全刷入 CPU 缓存。所以,acquire,release 分别使用读内存屏障和写内存屏障实现。
LoadLoad 保证第一个 Load 先于第二个,那么其实就是在第一个 Load 后面加入读内存屏障,阻塞等待 invalidate queue 完全处理完;LoadStore 同理,保证第一个 Load 先于第二个 Store,只要 invalidate queue 处理完,那么当前 CPU 中就没有对应的脏数据了,就不需要等待当前的 CPU 的 store buffer 也清空。
StoreStore 保证第一个 Store 先于第二个,那么其实就是在第一个写入后面放读内存屏障,阻塞等待 store buffer 完全刷入 CPU 缓存;对于 StoreLoad,比较特殊,由于第二个 Load 需要看到 Store 的最新值,也就是更新不能只到 store buffer,同时过期不能存在于 invalidate queue 未处理,所以需要读写内存屏障,即全屏障。
8.2. volatile 与 final 的内存屏障源码
我们接下来看一下 volatile 的内存屏障插入的相关代码,以 arm 为例子. 我们其实通过跟踪 iload 这个字节码就可以看出来如果 load 的是 volatile 关键字或者 final 关键字修饰的字段会怎么样,以及 istore就可以看出来如果 store的是 volatile 关键字或者 final 关键字修饰的字段会怎么样
对于字段访问,JVM 中也有快速路径和慢速路径,我们这里只看快速路径的代码:
对应源码:
f="https://github.com/openjdk/jdk/blob/master/src/hotspot/cpu/arm/templateTable_arm.cpp">源代码地址:templateTable_arm.cpp


9. 一些 QA
9.1. 为什么看到某些地方在方法本地变量使用 final
对于本地变量中的 final(和前面提到的修饰字段的 final 不是一回事),这个单纯从语义上讲,其实并没有什么性能方面的考虑,仅仅是作为一种标记。即:你可能在方法本地声明很多变量,但是为了语义清晰,就将肯定不会改的声明为 final。
JDK 的开发者一般用 final 本地变量来做这样一件事,假设有如下代码:

假设编译器不会做任何优化,那么 1,2,4 我们都各做了一次对于字段的访问。如果有编译器优化参与进来,那么是有可能优化成下面的代码的:

这样,只会读取 1 次 x 字段。这样造成的问题是,代码在被解释器执行,不同的 JIT 优化执行的时候,如果 x 有并发的更新,那么看到的可能的结果集是不一样的。为了避免这种歧义,如果我们确定我们这里的函数只想读取一次 x,那么就直接写成:

为了标记 lx 是不会变的(同时也为了表达我们只想读一次 x),加上 final,就变成: