

本节书摘来自华章出版社《Arduino计算机视觉编程》一书中的第3章,第3.1节,作者[土耳其] 欧森·奥兹卡亚(zen zkaya),吉拉伊·伊利茨(Giray Yilliki),更多章节内容可以访问云栖社区“华章计算机”公众号查看。
第3章
用OpenCV和Arduino进行数据采集
在本章中,你将了解计算机视觉系统的数据采集部分。相机和传感器的数据都会被处理。本章将讲授如何给视觉系统选择相机和传感器以及如何正确使用它们。因此,本章有两个主要部分:一个部分是关于用OpenCV进行图像和视频采集,另外一个部分是用Arduino进行传感器数据采集。
3.1 图像和视频采集
人们通过眼睛来获取周围环境的视觉信息。当涉及机器如何获取视觉数据时,各种各样的相机被用于这个目的。因为视觉数据会用数字来表示,有效的相机处理会得到一个更好的表示。这是你可以从本章中学到的知识。
在第2章中,你已经安装了OpenCV并且运行了一个典型的hello world应用。在此基础上,我们通过手头实际案例的讲解来学习OpenCV的数据采集功能。
OpenCV支持各种各样的相机,这样开发者有很大的选择范围。学习如何针对你的应用选择一个合适的相机也是本章的一个主题。你会在本章的相机选择部分找到答案。
选择相机之后,我们将研究如何使用OpenCV进行图像和视频的采集。在此过程中,我们将会学习如何读写图像、捕捉视频等。现在让我们开始吧!
3.1.1 相机选择
相机的选择是和需求紧密相关的。所以,在开始的时候多花点时间仔细考虑你需要的系统。这个简单的步骤会在后面的开发过程中帮你节省时间和金钱。除了需求以外,相机本身的性能也是需要考虑的。所以应该联系项目需求和相机性能来做出最佳选择。这正是本节要讲的内容!
3.1.1.1 分辨率
为了给应用程序选择合适的相机,分辨率和相关的相机传感器属性非常重要,先解释一下分辨率这个术语代表的意思。
当我们谈论一台200万像素相机的时候,这是什么意思?这是指图像(或者一个视频帧)上像素的数目。如果相机产生的图片有1200像素高、1800像素宽,那么图像包括1200×1800 = 2?160?000个像素大概是两百万像素。尽管这个属性被称为相机的分辨率,但是现实中的视觉应用程序往往需要不同的信息比如物体的分辨率,它与相机分辨率紧密相关但是需要更多的细节。
在实际使用中,分辨率意味着可用来区分两点的最小距离。因为照相的目的是获取一个物体或者事件的细节,能够获取的最小细节就显得非常重要。对于视频也是一样的,它不过是一系列连续的图像。
物体分辨率这个重要术语意味着可以通过相机察觉的物体最小粒度。因此物体和最小粒度都是非常重要的。下式展示了一个特定物体的大小和可以获取的最小粒度之间的关系:

让我们举个现实生活中的例子。想象一下你正在看一辆车的车牌。假设你的相机能看到车的全景。车在全视图里面的高度和宽度都是2m。假设为了能看到车牌,你需要的最小粒度是高0.2cm、宽0.2cm。
为了理解所需的物体分辨率,我们把值代入上面的公式可以得到:
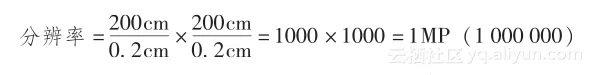
所以针对这个情况我们需要的分辨率为100万像素。但是需要注意的是这个计算依赖于物体和相机之间的距离。如果我们是从比较远的地方照相,图像中的物体会更小,因此为了识别车牌需要一个更高的分辨率。反之亦然,如果车离相机更近,那么车牌在图像中就会更大,因此一个更低分辨率的相机就能满足需求。
距离和分辨率之间的关系有一点复杂,但是可以用一种实用的方法来简化它。下图很好地展示了相机到物体的距离的重要性。

在这种情况下,我们可以很容易看出图片的宽度是车宽度的三倍,高度是车高度的两倍,所以总的分辨率是最初计算的6倍,就是600万像素,见以下计算:
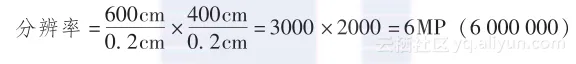
你越是经常在实际例子中实践,就能越准确地猜出特定应用所需相机的分辨率。
3.1.1.2 颜色
从颜色的角度区分,相机有两种类型:单色或者彩色。选择单色相机还是彩色相机仅仅取决于应用的要求。如果应用需要彩色信息,那么必须用彩色相机。如果颜色不重要,重要的是形状,最好选择一个单色(灰度)相机。单色相机通常比彩色相机更敏感并能提供更清晰的图片。在某些情况下将这两种相机一起使用也是有可能并且是必要的。
大部分网络摄像头是彩色的。此外你可以用OpenCV从彩色相机里面捕获一个灰度图像。一般来说,考虑未来的扩展性,彩色相机是首选。通过这种方式,你可以同时获取颜色和形状信息。
3.1.1.3 帧率
帧率是用每秒的帧数(FPS)来衡量的。帧率这个术语描述了相机每秒能够捕获和传输的图像的数量。一般来说,网络摄像头最高可以达到30FPS。有一些相机允许你动态调整帧率。
帧率越高,传感器运行得更快。此外,更高的帧率也会导致更多数据的存储。需要注意的是,如果你的应用程序不够快,也许无法充分利用相机的最高FPS。如果要在工厂每分钟生产6000个产品的生产线上找到产品缺陷,你可能需要一个高FPS相机。每分钟6000个产品意味着每秒100个,假设你需要为每个产品花10帧来找到缺陷,那么在这个应用中你需要一个10×100 = 1000FPS的相机。
FPS越高的相机,价格也越高。针对工厂这个例子做一个启发性计算并用帧速率来定义平均速度。比如一个普通的网络摄像机的FPS可能是50,而上文讨论的工厂的例子至少需要一个1000FPS的相机来检测缺陷,如果做一个粗略估计,1000FPS相机的价格可能是普通相机的20倍。
3.1.1.4 2D还是3D
从原理上来说,相机获取的图像是对场景的2D投影。如果你熟悉网络摄像头,它们都是2D网络摄像头。
3D相机加了第三个维度——到数据的距离。3D相机这个词指的是广角相机或者立体相机。广角相机会生成一个每个像素带着到特定点距离信息的图像。立体相机是用2个平行相机模仿人类的视觉来捕获三维图像。通过两张图片对应点的偏移量,可以计算出图像中任意点的深度。
如果你的应用需要3D功能,那么你需要一个3D相机比如Kinect或者Asus Xtion Pro Live。当然,还有很多其他3D相机!
再次提醒,3D相机需要更多的存储空间。所以如果你不需要3D信息,请使用2D相机。
3.1.1.5 通信接口
通信接口影响相机系统的很多属性。流行的接口有USB、FireWire、GigE和CameraLink。有很多变量可以进行比较,见下表:
通信接口 最大距离 最大带宽 支持多相机 实时性 即插即用
USB 2.0 5m 40MB/s 中等 低 高
USB 3.0 8m 350MB/s 中等 高 高
FireWire 4.5m 65MB/s 中等 高 高
CameraLink 10m 850MB/s 低 高 低
GigE 100m 100MB/s 高 中等 中等
从表中可以看到,通信接口对控制器到相机的距离、带宽、FPS甚至可用性会产生巨大影响!所以,请评估你的需求并且给应用选择合适的接口。
网络摄像头有一个USB接口。所以它们有不错的控制器到相机距离、带宽、FPS和可用性。这使得绝大多数计算机视觉应用可以使用网络摄像头。
3.1.2 图像采集
到现在为止,我们已经对如何选择相机有了一个比较清楚的认识。现在是时候更进一步了,让我们从相机中读取数据。
大道至简,最好让一切事情保持简单并且易于使用。正因如此,我们的例子将使用一个标准的网络摄像头。这个例子将选用罗技C120作为网络摄像头。请注意安装网络摄像头的驱动以便可以与OpenCV一起工作。
我们使用了OpenCV C++ API来从相机中读取数据,此外,OpenCV提供了很棒的文档,可以用C、Python和Java API轻松实现这个例子。如果需要更多信息,可以访问opencv.org。
3.1.2.1 读取静态图片
在设计的概念验证阶段,使用静态图片进行工作是有好处的。例如,假设你想开发一个人脸识别的应用程序。首先,你应该在一组人脸图像的样本上工作,所以,从数据存储中读取静态数据将是这个过程的第一步。
OpenCV使计算机视觉系统的开发变得简单!让我们用OpenCV从存储中读取静态数据。现在编写代码来读取静态图片并将它展现在窗口中。请把下面的代码输入到OpenCV开发环境中并将其保存为read_static_image.cpp:


当你编译这段代码时,它将生成一个可执行文件。在Windows环境下,我们姑且认为它是read_static_image.exe。你可以把计算机视觉里面著名的lena.jpg图片作为输入。在Windows环境下,把这个图片复制到C:/cv_book/目录下。在cmd.exe窗口中,导航到包含read_static_image.exe的目录下。该指令如下:
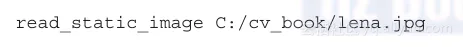
在其他平台上,指令也类似。比如你的可执行文件是read_static_image.exe并且与lena.jpg在同一个目录下,你可以执行下面的指令来运行程序:

现在让我们解释这段代码。引入头文件这样的基础部分已经在前面讲过。让我们从新的部分开始,如下代码片段所示:

首先检查参数的数目是否正确。在前面的命令行中看到应该有两个参数:第一个参数是程序本身,第二个参数是图片路径。如果参数的数量不是两个,那么程序将打印一行帮助信息然后报错退出。
下一步创建了一个Mat对象用来存储图像数据。图片数据以RGB格式读取,如下代码所示:

然后判断是否成功读取图片,并确认图片数据不为空。创建一个名为Read Static Image的窗口,图片会显示在该窗口中。
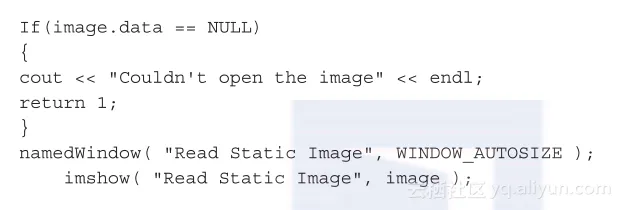
我们想要图片持续显示直到用户按键退出,所以我们使用waitKey函数,它只有一个用来表示等待用户输入多久(单位是毫秒)的参数。零意味着永远等待:

程序的输出如下:

你可以使用CV_LOAD_IMAGE_GRAYSCALE属性来以灰度图的格式加载图片!
3.1.2.2 在网络摄像头里面做快照
有时候需要用相机做快照并且保存下来以便进一步分析。这个过程通常通过一个触发器启动。
回想一下基于人脸识别的门锁例子。当访客按门铃时,系统需要对脸部做一个快照并且对它进行人脸识别。这个应用是快照的一个很好的例子,我们还能找到其他需要做快照的相似情形。使用以下代码创建一个项目并且保存为take_snapshot.cpp。

前面的代码和read_static_image.cpp的代码相似。但它只是从相机中读取一帧的图像并用命令行传进来的名字对这一帧进行保存。命令行如下所示:
如果应用的名字不是take_snapshot,那么想要运行这段命令应把take_snapshot替换成应用的名字。现在让我们来解释代码!
首先,我们创建了一个视频捕捉对象用来从连接的相机中捕获数据。通常情况下CV_CAP_ANY的值是0。如果你使用多台相机,需要手动增加索引,比如cap(1):

下一步创建了一个用来保存帧的矩阵对象,并把帧数据从相机对象读到矩阵对象中:

在检查帧不为空之后,就开始读取数据,然后用imwrite函数来保存图片。图片的名字是命令行的第一个参数。

3.1.2.3 从网络摄像头获取视频流
视频处理应用程序通常需要一个视频流作为输入数据。通过分析帧间数据,就可以完成一些更高级的任务,比如运动识别等。
视频流的FPS值和分辨率在这一过程中就变得非常重要,因为它们直接影响实时行为。越高的FPS意味着用来进行处理的时间越少。同样,越高的分辨率也让计算变得更加复杂和耗时。
基于手势的运动识别是一个非常好的视频流应用例子。同样,寻线机器人也需要捕获一个实时视频流来持续地沿线行走。所以我们要理解这一部分的重要性,让我们用下述代码来捕获实时视频流:


这段代码和快照代码非常相似,除了帧数据的读取过程是在一个无限while循环中。有一个可选的ProcessFrame函数来把视频帧转成灰度帧。如果你想要一个彩色的帧,那么注释掉ProcessFrame函数。
在运行这段代码时,你能看到相机里面的实时视频流!
如果要改变视频流的FPS,你可以使用函数bool VideoCapture::set(int propId, double value),propId的值为CV_CAP_PROP_FPS。如果你要把FPS设为10,你可以输入:

别忘了先检查你的相机是否支持不同的帧率。
3.1.2.4 与Kinect交互
Kinect是一个革命性的3D图像设备,由微软研发并被广泛应用于计算机视觉应用中。Kinect的第一个版本是与大受欢迎的游戏主机Xbox 360一起发布的,Xbox的新版本名为Xbox One。尽管它最初是为游戏创造的,但是Kinect对计算机视觉应用产生了巨大的促进作用。
Kinect的默认连接器是为Xbox专门设计的,电源线和数据线是一根线。如果电脑或者微机要使用Kinect,你需要一根USB转换线(见下图)。
现在让我们开始与Kinect进行交互并通过OpenCV来访问它。然后你将开始学习3D视觉应用程序!

3.1.2.5 将OpenCV与Kinect集成
安装点云库(Point Clond Library,PCL)将安装所有Kinect需要的软件和驱动。PCL是一个多平台库。你可以从 http://pointclouds.org/得到PCL的安装包。在Mac上你无需安装PCL来使用Kinect。只要执行这一章的步骤就可以让Kinect工作起来。
你需要安装libfreenect驱动来让Kinect与OpenCV通信。现在我们进入主题!我们将在Mac示范这个例子,在其他平台上也同样有效。
在Mac上安装
最好安装一个诸如Homebrew、Macports或者Fink这样的包管理器。正如我们之前的选择,我们将用Homebrew进行安装。
让我们按照以下步骤安装libfreenect:
1.?如果你还没有安装Homebrew,你可以看下2.2.2节中的指令。不管你是否安装了Homebrew,运行下列程序来更新Homebrew:

2.?要安装libfreenect,请在终端输入如下指令:
3.?这就完成了,现在你可以把Kinect插到电脑上并执行下面的命令来体验下带深度信息的图像:

Xcode集成
与OpenCV和Xcode的集成一样,我们将使用相同的步骤来集成libfreenect以便在OpenCV中使用Kinect的功能。
1.按照之前创建OpenCV_Template项目的步骤来创建一个新的项目。命名为OpeCV_Kinect。
2.在OpeCV_Kinect项目上依次单击Build Settings | Search Paths | Header Search Paths并单击加号来添加如下的两个路径:

3.然后,依次单击Build Phases | Link Binary with Libraries并单击加号来添加两个需要的框架:

4.加完框架以后,需要添加libfreenect库和libusb库。然后,再次单击加号,再单击Add Other…。
5.按cmd+Shift+g组合键然后在弹出窗口中输入/usr/local/lib。之后选择ibfreenect_*.dylibs。在选择的同时持续按下cmd键。
6.现在让我们执行相同的步骤来加入libusb库。按cmd+Shift+g组合键然后在弹出窗口输入/usr/local。之后选择libusb*.dylibs。
这样就集成好了!现在按照以下步骤开始编码。
1.?下载libfreenect-master得到我们需要的源代码。你可以从 https://github.com/OpenKinect/libfreenect下载。
2.?复制粘贴libfreenect-master/wrappers/opencv/cvdemo.c到OpenCV_Kinect项目的main.cpp文件里。
3.?最后,我们需要把libfreenect_cv.h和libfreenect_cv.c拖到OpenCV_Kinect项目的文件夹中(与main.cpp在一个文件夹中)并构建!以下是main.cpp的代码:
?x-oss-process=image/resize,w_1400/format,webp)


现在,让我们通过代码来解释它是如何工作的,以及如何从Kinect中获取带深度信息的图像:
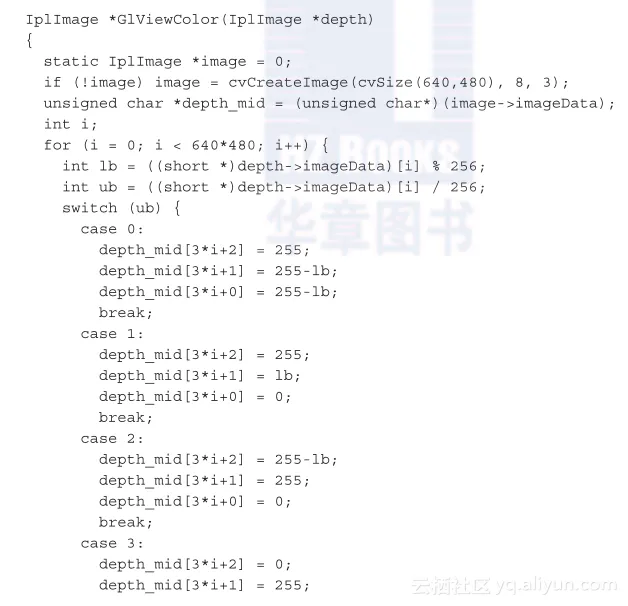

来自Kinect的数据需要转换成合适的格式以便存储深度信息。在IplImage *
GlViewColor(IplImage *depth)函数的for循环里,深度信息被转换成颜色。这个函数返回了一个缩放过的图像来进行表示。这是main函数里面的代码部分:

在main函数中,有一个while循环会一直循环直到有按键输入。While循环会每10ms检测一次,这是因为调用了cvWaitKey(10),所以会等待10ms就检测一次:

代码中使用Libfreenect库的freenect_sync_get_rgb_cv函数接收RGB相机的图像并把其加载到IplImage*这个图像指针指向的内存地址,如上述代码所示。代码段中的if语句会检测图像是否正确加载,如果没有正确加载会返回-1来中止程序。在cvCvtColor函数的帮助下,图像会从RGB格式转换为BGR格式。

对于图像的深度信息会执行一个类似的过程。freenect_sync_get_depth_cv函数会去获取带深度信息的原始图像并把它放到IplImage *depth指针指向的内存地址。然后,会检测深度图像是否正确加载。下面是if循环之后的代码:

现在是时候用RGB信息和深度信息把图像展示出来了。如果仔细看前面代码片段的第二行,会注意到原始的深度图像使用了GlViewColor函数进行缩放。
运行代码后,你会看到下图:

在深度信息图中,可以看到靠近摄像机的物体会更红一点,而远离摄像机的物体会更绿一点。




