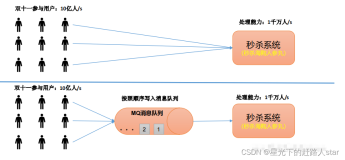
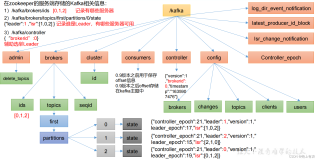
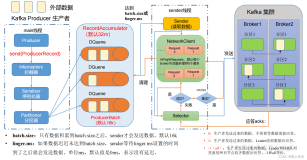
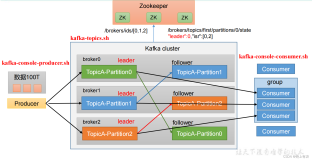
快速入门
- 翻译者:kimmking@163.com
- 原文:kafka.apache.org/quickstart
本教程假设读者完全从零开始,电脑上没有已经存在的Kafka和Zookeeper环境。以下内容需要注意的是:因为在类Unix平台和Windows平台上的Kafka控制脚本不同,在Windows平台上,需要使用路径\bin\windows代替/bin,脚本扩展名改为.bat。
第一步:下载kafka
下载Kafka 0.10.2.0版本 并解压:
>tar -xzf kafka_2.11-0.10.2.0.tgz
>cd kafka_2.11-0.10.2.0
第二步:启动kafka服务端
Kafka中使用了Zookeeper,所以我们需要先启动一个Zookeeper服务端。我们可以使用kafka中已经打包好的脚本方便的完成这个操作,快递启动一个单节点的Zookeeper实例。
>bin/zookeeper-server-start.sh config/zookeeper.properties
[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
…
然后启动kafka服务端:
>bin/kafka-server-start.sh config/server.properties
[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
…
第三步:创建主题
现在我们创建一个单一分区(partition)并且只有单一复制(replica)的主题,名字叫test:
>bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic test
我们可以使用如下命令列出主题列表:
>bin/kafka-topics.sh –list –zookeeper localhost:2181
test
当然,我们也可以通过在服务端(broker)配置自动创建主题的选项,这样当有消息发送到一个不存在的主题时系统会自动创建它。
第四步:发送消息
Kafka自带了一个命令行工具,它可以从一个文件或标准输入流发送消息到Kafka集群。默认情况下,每一行内容将被当做一个单独的消息。 运行以下生产者脚本,然后通过控制台输入一些字符,即可作为消息发送到服务端:
>bin/kafka-console-producer.sh –broker-list localhost:9092 –topic test
This is a message
This is another message
第五步:启动消费者
Kafka同样也提供了一个消费者脚本,它可以消费掉消息并输出到命令行标准输出流(STDOUT):
>bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic test –from-beginning
This is a message
This is another message
如果我们在不同的终端窗口运行如上的两个命令,这时就可以在消息生产者窗口输入内容,然后在消费者窗口看到它。
所有的命令行工具都有额外的参数,运行命令时不带任何参数即可显示出参数信息详情。
第六步:启动一个多broker集群
到目前为止,我们只启动了一个单broker。对于Kafka来说,一个单broker也是一个集群,只不过集群的大小是1。其实我们启动一个多broker集群的话,并不会复杂多少。现在我们来尝试一下,如何在同一个机器上启动3个broker节点的集群。
首先,我们为每一个broker创建一个配置文件(Windows上使用copy命令代替cp)。
>cp config/server.properties config/server-1.properties
>cp config/server.properties config/server-2.properties
按如下内容编辑各个配置文件:
“` config/server-1.properties: broker.id=1 listeners=PLAINTEXT://:9093 log.dir=/tmp/kafka-logs-1
config/server-2.properties: broker.id=2 listeners=PLAINTEXT://:9094 log.dir=/tmp/kafka-logs-2 “`
其中broker.id属性是每个节点在集群中唯一的名字。端口和日志存储目录则由于我们这几个节点都在同一台机器上启动而必须要修改。 前面的步骤里我们已经有了一个启动好的单节点kafka和Zookeeper,现在我们只需要启动这两个新配置的节点:
>bin/kafka-server-start.sh config/server-1.properties &
>bin/kafka-server-start.sh config/server-2.properties &
现在我们创建一个复制因子为3的新主题my-replicated-topic:
>bin/kafka-topics.sh –create –zookeeper localhost:2181 –replication-factor 3 –partitions 1 –topic my-replicated-topic
创建完成,但是怎么才能知道主题被创建在整个集群中的哪个broker上了呢?事实上我们可以使用如下显示主题描述信息的命令:
>bin/kafka-topics.sh –describe –zookeeper localhost:2181 –topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic:my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
此时会输出主题的描述信息:第一行给出了所有分区信息的摘要,接下来的每一行则给出具体的每一个分区信息。因为我们前面创建的这个主题只有一个分区,所以就只展示了一行。
“leader”节点 “leader”节点负责响应给定节点的所有读写操作。每个节点都可能成为所有分区中一个随机选择分区的leader。 “replicas”是复制当前分区的节点列表,无论这些节点是不是leader、是不是可用。 “isr”是目前处于同步状态的replicas集合。它是replicas列表的子集,其中仅包含当前可用并且与leader同步的节点。 注意上述例子中,编号为1的节点是这个只有一个分区的主题的leader。
我们可以在最开始创建的主题上运行同样的命令,看看会发生什么:
>bin/kafka-topics.sh –describe –zookeeper localhost:2181 –topic test
Topic:test PartitionCount:1 ReplicationFactor:1 Configs:
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
结果是很明显的:原来的主题在编号为0的服务端上,它是我们创建的这个集群上唯一的服务端,没有复制节点(replicas)。
现在我们来发布一些消息到新创建的主题:
>bin/kafka-console-producer.sh –broker-list localhost:9092 –topic my-replicated-topic
my test message 1
my test message 2
^C
然后消费这些消息:
>bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –from-beginning –topic my-replicated-topic
my test message 1
my test message 2
^C
接着我们来测试一下容错性。编号为1的broker现在是leader,我们把它kill掉:
>ps aux | grep server-1.properties
7564 ttys002 0:15.91 /System/Library/Frameworks/JavaVM.framework/Versions/1.8/Home/bin/java…
>kill -9 7564
在Windows上使用:
On Windows use:
>wmic process get processid,caption,commandline | find “java.exe” | find “server-1.properties”
java.exe java -Xmx1G -Xms1G -server -XX:+UseG1GC … build\libs\kafka_2.10-0.10.2.0.jar” kafka.Kafka config\server-1.properties 644
taskkill /pid 644 /f
主节点直接切换到其中的一个从节点,并且编号为1的节点不再位于同步复制节点集合了:
>bin/kafka-topics.sh –describe –zookeeper localhost:2181 –topic my-replicated-topic
Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs:
Topic: my-replated-topic Partition: 0 Leader: 2 Replicas: 1,2,0 Isr: 2,0
但是消息现在仍然对消费者可用,尽管负责处理写消息的主节点已经宕掉了:
>bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –from-beginning –topic my-replicated-topic
my test message 1
my test message 2
^C
第七步:使用Kafka连接器(Kafka Connect)导入导出数据
使用控制台读写数据固然方便,但是有时我们还是希望从其他数据源导入数据,或者导出数据到其他系统。很多时候我们可以无需通过编写集成代码,仅仅使用Kafka连接器就可以实现数据导入导出。
Kafka连接器是一个用于从Kafka导入导出数据的工具。它可以通过扩展实现自定义逻辑,或者直接与外部系统交互。在本教程我们将展示如何简单的使用Kafka连接器,实现从一个文件导入数据到Kafka主题,以及从Kafka主题导出数据到一个文件。
首先,我们创建一个测试用的文本文件:
>echo -e “foo\nbar” > test.txt
然后我们在单机模式启动两个连接器,即它们运行在同一个本地进程。这里我们使用3个配置文件作为参数。第一个文件是针对Kafka连接器进程的通用配置,包含连接到的Kafka Broker和数据的序列化格式。后面的每一个文件代表一个连接器。它们每个都包含一个唯一的连接器名称,要实例化的连接器类型和此连接器需要的其他配置。
>bin/connect-standalone.sh config/connect-standalone.properties config/connect-file-source.properties config/connect-file-sink.properties
这些示例配置文件都包含在Kafka中,它们使用前面步骤启动的本地集群配置,创建两个连接器:第一个作为源连接器,从一个文本文件读取数据然后将每一行作为一个消息写入到指定的Kafka主题;第二个作为接收端连接器,从一个Kafka主题读取消息,并将每条消息作为一行写入指定的文本文件。
启动过程中我们可以看到一些日志信息,其中包括哪些连接器被实例化了。一旦Kafka连接器进程启动,源连接器就开始从test.txt文件读取信息,然后把每一行内容作为一个消息发送到名为connect-test的主题;接收端连接器就开始从connect-test主题读取消息,然后把每一个消息内容作为一行写入test.sink.txt文件。我们可以查看这个文件的内容来验证这些经过整个消息管道传递的数据:
>cat test.sink.txt
foo
bar
消息数据被Kafka存储在connect-test主题中,这样我们也可以在控制台启动一个消费者来查看主题里的消息(或者使用自定义的消费代码来处理):
>bin/kafka-console-consumer.sh –bootstrap-server localhost:9092 –topic connect-test –from-beginning
{“schema”:{“type”:”string”,”optional”:false},”payload”:”foo”} {“schema”:{“type”:”string”,”optional”:false},”payload”:”bar”}
…
这些连接器会持续的处理数据,因此我们可以通过添加数据到输入文件,然后看到消息通过整个管道: The connectors continue to process data, so we can add data to the file and see it move through the pipeline:
>echo “Another line” >> test.txt
然后我们可以看到这行数据在消费者所在的控制台以及接收端文件里出现。