概览
因为长期在做跟阿里云飞天大数据平台相关的前端工作,也一直在思考一个问题:“大数据的前端跟其他业务的前端有什么不一样”,具体来说就是,在大数据和人工智能的浪潮下,到底对前端技术的发展带来了什么影响。
以团队在负责在做的阿里云飞天大数据平台为例,从在 2009 年写下第一行代码,现在已经是阿里大数据发展的第 11 个年头。我是 2011 年加入阿里的,之后就一直在负责做大数据相关的前端工作,基本上参与了阿里绝大部分大数据发展的历史进程。现在回头看,很庆幸自己在一个历史的变革时期入行,更有幸见证了一些划时代意义的数据产品的诞生,以及它们对前端技术带来的变革。
如果我们把 2010 年当做大数据 Web 产品应用的元年,会发现它是一个有趣的年份,为什么这样讲?
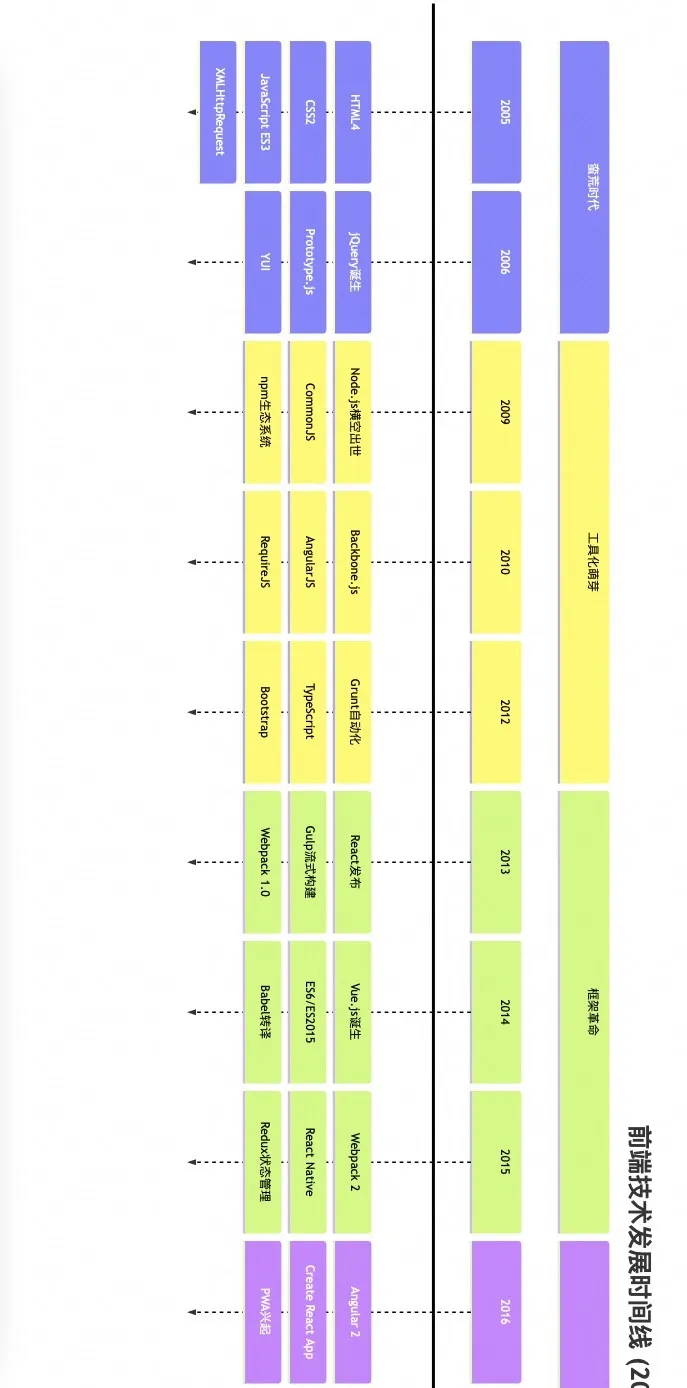
回看前端的发展历史,在 2005 年前后有一波大的技术变革,就是从 Web1.0 到 Web2.0 的过渡。
在此之前,前端更多地是做纯内容的静态展示,比如下图中的那个时期的苹果和雅虎的官网。

之后前端开始逐渐做成复交互的动态网页,这其中一个重要的历史性标志就是 Gmail 对 Ajax 等新技术的应用。

而在 2010 年前后,各种大数据应用进入一个爆发期间,阿里很多知名的应用基本都在那段时间展露头角,现在回头再来看那段历史,这其中很大的一个原因,随着互联网的大发展,特别是 Web2.0 之后,数据的有了大爆发的增长。
下图就很好地展现了这个趋势,如果说之前的 Web 应用更多在“产生”数据阶段,那在 2010 年之后如何更好的“展现”数据被提上了新的高度,很多前端技术也因之打开了新的篇章。

后面会结合自己的实践,以三条主线来讲讲数据智能浪潮对前端技术发展的影响,分别是数据可视化,软件泛 Web 化和交互多样化。
数据可视化
大数据浪潮下,最明显的一个特征就是数据的指数型增长,从上图中就能看到这个趋势,随之而来的挑战就是如何更形象地展现数据并进行交互展示,也就是我们通常讲的“数据可视化”。
回到技术本身,那数据可视化对前端最大的影响应该是大大促进了 SVG,Canvas 和 WebGL 的发展。

而这当中,除了浏览器底层技术的升级,在上层可视化库和可视化应用也涌现了大量优秀的作品,其中佼佼者包括:
- 开源技术组件层面
-
- AntV
-
- Echarts
-
- HighLights
-
- ...

- 重数据可视化的产品
-
- 阿里云大屏可视化产品 DataV
-
- 阿里云的 Quick BI
-
- BI 分析工具 Tebleau
-
- 特色领域的分析产品,比如 Plantir

在专业的细分领域,比如地理,安防,新零售,等领域中不同场景就有很多机会。具体比如在我们阿里云的一站式大数据开发治理平台的 DataWorks[1] 产品就有用于做流程编排的 DAG,图分析[2],数据的血缘分析等有意思的可视化。

软件 Web 化
大家最近应该注意到一个现象那就是:Web 系统做得越来越复杂,很多原先桌面端的复交互应用逐渐 “泛 Web 化”,甚至很多应用一上来就是 Web 的技术做第一版。
这里说的泛 Web,从表现中又可以分为两种:
一是直接用前端技术去做桌面软件,其中标志性事件就是 NW.js 和 Electron 在 2013 起步后的蓬勃发展;大家熟悉的 IDE VSCode 就是这当中的典型代表;阿里的桌面版钉钉 UI 层大量用到的 Web 的技术。

另外一种就是直接在 Web 上实现,比如 大家最近能看到各种 Web'X' 系统( Google Docs )。
这背后推动力,一是随着浏览器相关逐渐走向统一,用它的技术可以更便捷地实现跨端,另一个就是云计算大数据的兴起,特别云端的存储和算力逐渐突破了原先的本地 PC 的性能边界,因而重塑了原先人机交互的入口。
关于跨端的好处自不用多讲,我想想重点讲讲第二点。要讲这个逻辑,我又得简单讲讲计算机的发展,从占地 170 平方米的世界上第一台通用计算机 “ENIAC”,到苹果和微软时代的个人 PC,移动时代的 iPhone 和 Andriod,再到云计算时代的大型计算集群。

对开发者工具而言,之前前很多软件很多都是本地,因为它往往用本地 PC 的计算力就够了,但大数据的场景下计算本地算力肯定是不够的,它是依赖云端的计算集群(以我们阿里飞天大数据平台而言,我们已经 10 万台计算集群的规模),如何在用户侧用上更方便和灵活地使用这些算力就是我们前端重点要做的,而这是原先软件的架构要不不能让你做定制,要不定制的成本很高(有时候甚至超过了重新做一套的成本),因此很多系统会选择重新起航做一版。
这其中,我们负责阿里云的 Dataworks 中的两大件:WebIDE 和 WebExcel ,就非常典型的例子。

Dataworks 从一开始就是根据云原生的思路设计开发的,后端需要通过云计算提供强大的算力替换原先的本地算力,前端需要实现更精巧的架构设计来对应日益复杂的交互能力;具体到我们的应用,它包括但不限于:
- 架构层面
-
- 状态管理
-
- 插件化
-
- ...
- 复交互的组件
-
- Editor
-
- Form/Excel
-
- Tree
-
- Logivew
-
- ...
交互多样化
最近今年在以数据驱动的人工智能的大力发展下,特别在图像识别,语音识别,自然语言处理方面获得了很大的突破,让前端的新交互也获得了长足的进步。
UX
在面向使用者(UX)产品由 GUI(Graphical User Interface)变成 XUI,用户不仅可以用通过鼠标键盘方式操作图形界面,更可以通过面部表情,身体动作,语音交互等形式提供新的交互形态。
下图就是在 2016 年左右,我们在阿里云ET中一些人机对话,互动游戏中的一些实践,具体可以看这里[3]。

这一轮的技术变革,有两个大的宏观的背景。
AI 技术的第三波潮起
随着 2010 年前后,深度学习技术的成熟,计算力的提升,以及互联网时代积累的大数据财富,人工智能技术开始一段与以往大为不同的复兴之路;分别在语音识别,图像识别,自然语言处理等相关技术上获得根本的突破。
例如, 2012 年到 2015 年,在代表计算机智能图像识别最前沿发展水平的 ImageNet 竞赛(ILSVRC)中,参赛的人工智能算法在识别准确率上突飞猛进。2014 年,在识别图片中的人、动物、车辆或其他常见对象时,基于深度学习的计算机程序超过了普通人类的肉眼识别准确率。
下图就摘自李开复老师的《人工智能》就体现了这个趋势:

WebRTC
对于前端来讲,另一个必备条件就是 WebRTC (Web Real-Time Communication)技术的成熟,它于 2011 年 6 月 1 日开源并在 Google、Mozilla、Opera 支持下被纳入万维网联盟的 W3C 推荐标准。通过它,前端可以便捷地处理图像,视频,语音等内容。大家目前看到很多有意思的交互底层就是依赖他。

DX
在面向前端开发者(DX):智能化手段可以提升我们的研发效率和体验,以我们阿里和蚂蚁自身的实现看,Imgcook(D2C:Desgin to Code),代码智能提示[4],智能可视化 AVA[5],前端机器学习 pipcook[6] 都是挺有意思的尝试。
总结
以上就是我在实践中关于数据浪潮下前端技术发展的一些思考。当然前端技术技术这几年能获得这么长足进步,除了数据智能,其他大趋势(比如移动互联,5G,IoT)也深刻影响了前端技术的走向,但这些就不在本文讨论的范围内,有机会再跟大家讨论。
一直很喜欢吴军在《智能时代》一书中提到的一个观点:“2% 的人将控制未来,成为他们或者被淘汰”。期望各位前端同学都能在这波数据智能化的浪潮中找到自己的定位。
写在最后
如果大家对这块感兴趣,也希望来阿里巴巴一起做大数据和人工智能相关的工作,随时欢迎私信或者发简历给我:jifeng.zjd@taobao.com。大家一起合作,做件有意义的事情,团队长期招人。
相关链接
[1]https://www.aliyun.com/product/bigdata/ide
[2]https://zhuanlan.zhihu.com/p/132393588
[3]https://www.zhihu.com/question/56560321/answer/203249193
[4]https://zhuanlan.zhihu.com/p/115377444
[5]https://github.com/antvis/AVA
[6]https://github.com/alibaba/pipcook