更多精彩内容参见云栖社区大数据频道https://yq.aliyun.com/big-data;此外,通过Maxcompute及其配套产品,低廉的大数据分析仅需几步,详情访问https://www.aliyun.com/product/odps。
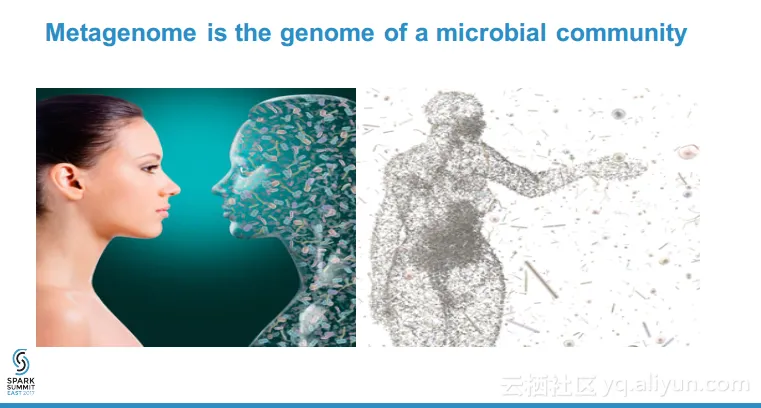
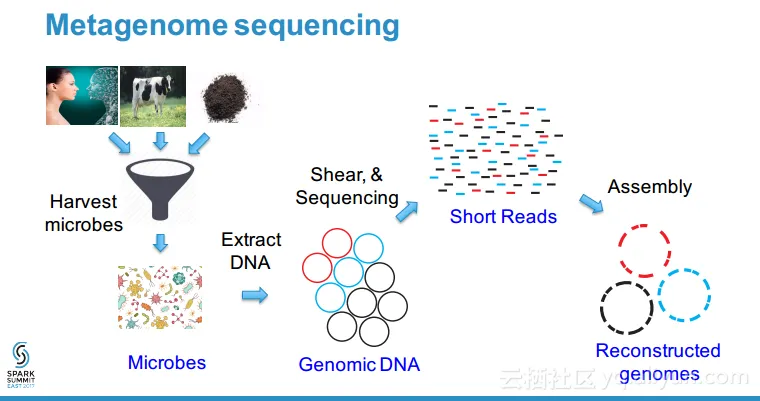
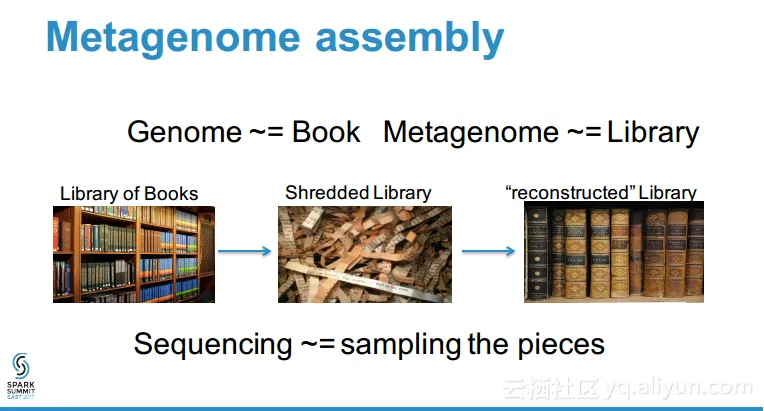
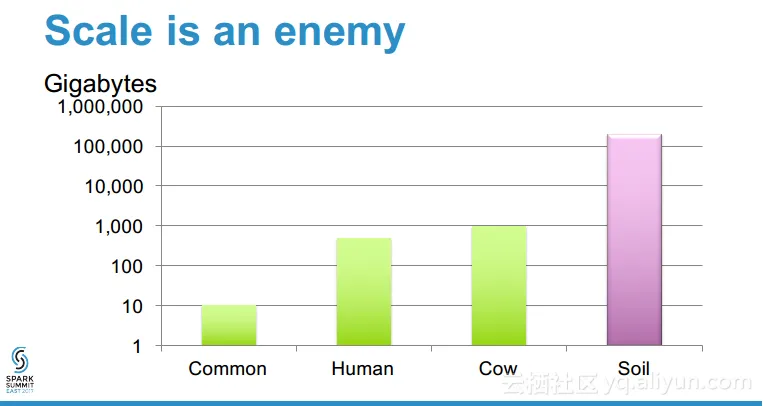
本讲义出自Zhong Wang在Spark Summit East 2017上的演讲,主要介绍了元基因组分析的相关概念以及目前面临的计算上的挑战,实验表明,使用Spark进行元基因组数据分析的速度、可扩展性、健壮性都非常不错,并且最重要的一点十分容易编程实现,对于元基因组分析来说,Spark是一个具成本效益比较高的解决方案并且能够快速开发和部署的方案。