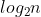小叽导语:正如Google的高级搜索副总裁Amit Singhal在介绍知识图谱时提到的:“The world is not made of strings , but is made of things.” 大千世界,万物相联,借助知识图谱,实现了搜索领域的things, not strings。保险领域的知识图谱之路,何去何从呢?
背景


随着互联网和AI智能的发展,近年来我国的健康险业务迎来了飞速发展和变革。健康险,即健康保险,是保险业务的一个重要分支,有着广阔的发展前景,是本财年保险领域排兵布阵的重要战场。健康险是以被保险人的身体为保险标的,依据合同约定当被保险人遭遇疾病或意外伤害时,对被保险人的医疗费用或财产损失进行补偿或给付的一种保险。
为了支撑日益剧增的理赔单量的挑战,在不增加客服小二工作量的前提下,健康险理赔需要做到智能化、自动化和低风险化。因此,理赔天平团队在智能理赔、理赔机器智能问答和反骗赔等方面做出了相应尝试,而健康险知识图谱是以上各种尝试所依赖的底层基础技术。
本文首先介绍了健康知识图谱构建流程、整体框架和遇到的问题,然后总结了健康知识图谱在保险理赔领域应用场景和对应的玩法。
健康知识图谱和Schema示例

图1 健康知识图谱样例
健康知识图谱样例如图1所示,其中存储着用户、险种、疾病、医院等各类节点信息以及它们之间的关联信息。比如,用户张三投保了门诊保险金,当该用户患慢性肺炎申请理赔时,我们可以根据图谱来判断购买的险种对慢性肺炎时免责的,进行智能拒赔即可。
健康知识图谱的具体节点和边属性如下:

健康知识图谱整体框架

图2 健康知识图谱整体技术框架
健康知识图谱整体框架如图2所示,主要由信息源、实体抽取、数据源、更新框架和数据存储和质量控制等部分组成,具体如下:
1、信息源

保单类:用户购买的保单信息,包含用户、险种、时间、保障疾病范围等信息。
外部网站数据:通过爬虫,可以获取各种渠道的信息,包括医院信息、科室信息等。
2、实体/关系抽取
信息源有很多形式,包括图片、文字、语音、视频等类型,需要从中提取有用的实体信息和实体关系。这部分可以通过机器学习(包括深度学习、规则引擎等)或者人工方式实现。
3、数据源
数据源包括各种类型的数据,包括上传的文件、ODPS中的用户画像信息、关系型数据库中的数据、事件或日志等。
4、更新框架
一般通过三种方式将提取的数据导入到Geabase中,如下图所示:

初始化方式,将全量数据写入ODPS表某个分区中,全量初始化导入Geabase。
T+1批量更新方式,通过MR Job定时任务将更新数据写入最新分区中,每天批量新增、更新和删除Geabase中数据。
实时更新,将更新的数据发送到事件系统或者日志搜集系统,然后实时消费,将数据更新到Geabase数据库中。
5、数据存储
Geabase为了实现对数据进行分布式存储和计算,将整个图按节点分割为多个子图,每个子图存放在同一个shard中,每个shard都有自己的备份。Geabase数据库线上存储的都是有向边,如果需要存储无向边,则需要存储两份,即正向和反向都要进行存储。

Geabase在分块过程中,对于交界处的边,Geabase会同时生成2条边,即一条出边和一条入边,分别属于相邻的两个Shard。
6、保障机制
数据抽样/校验:对更新数据(批量或者实时)进行随机抽取特定比例的样本,进行校验,来验证数据导入准确性。
日志监控:对Geabase更新异常、查询性能等进行实时监控。
开关:可以利用开关控制数据版本,来决定采用哪个版本的稳定数据。另外,对接口或者流程中的某些环节进行开关切换控制。
应用场景
智能系统理赔
将险种和疾病之间的免责/非免责关系,作为理赔因子,加入到系统智能核赔规则中,完善智能理赔。

比如,用户张三购买了门诊报销金险种,进行理赔慢性肺炎时,会从图谱中查看门诊报销金和慢性肺炎的关系-免责,因此会在理赔系统审核阶段的规则引擎中直接拒掉,无需进入人工审核,实现快赔快拒。
智能问答
在热线工作台或者机器人端应用时,当用户咨询某种疾病是否可以理赔或者投保时,可以将图谱和知识库、模版库相结合,实现智能问答,提升小二工作效率或者减少小二工作量。


机器人端
反骗赔
场景1:

利用知识推理算法,比如用户1的周边用户(用户10-用户14)都是灰度骗赔用户,则用户1骗赔的概率就很大,存在骗赔风险。
场景2:

比如用户1的一代和二代直系亲属都没有多指症(属于先天性遗传病),那么用户1患这种先天性疾病的概率就比较小,存在骗赔风险。
另外,还可以通过用户的报案位置和医院位置就行判断骗赔的风险。
个性化推荐

可以根据张三的一度(甚至可以扩展到二度、三度)关系中,查找和张三用户画像比较类似的朋友,将他们购买的险种推荐给张三。
未来展望
下一步,我们主要从以下几个方面提升知识图谱价值:
提高数据覆盖率,存储更加丰富的海量数据。
利用知识推理算法,挖掘健康图谱数据价值。
将图谱进行平台化,扩展到其他领域。
References:
[1] Ehrlinger L, W W. Towards a Definition of Knowledge Graphs[C]// JointProceedings of the Posters and Demos Track of, International Conference onSemantic Systems - Semantics2016 and, International Workshop on Semantic Change& Evolving Semantics. 2016.
[2] Das R, Neelakantan A, Belanger D, et al. Chains of Reasoning over Entities,Relations, and Text using Recurrent Neural Networks[J]. 2016:132-141.
[3] https://docs.antfin.com/geabase/docs
转载