前言
随着云存储的广泛使用,文档数量与日俱增,越来越多的同学提出了这样的疑问:如何在众多文档中,快速定位到自己想找的文档呢?如何能快速搭建起基于存储服务的全文搜索系统呢?如何让搜索服务及时反映文档的增删改呢?
这一切,函数计算都可以轻松帮你实现。
本文以OSS作为云存储服务的例子,OpenSearch作为搜索服务的例子,通过阿里云函数计算,实现一个简单高效的针对文本文档的全文检索系统。
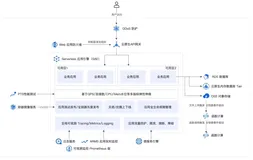
技术方案

具体实现
1.开通阿里云对象存储(Object Storage Service,简称OSS)
阿里云对象存储服务(OSS)为用户提供基于网络的数据存取服务,用户可以通过网络随时存储和调用包括文本,图片,音频和视频等在内的各种非结构化数据文件。具体开通方式请参考阿里云OSS快速入门。
本示例中,开通OSS之后在“华北2”区域新建名为“fc-search-demo”的bucket,类型为标准存储,如下图所示。更多配置选项,请参考创建存储空间以及具体需求选择。

2.开通阿里云开放搜索(OpenSearch)
阿里云开放搜索(OpenSearch)是一款结构化数据搜索托管服务,为用户提供简单,高效,稳定,低成本和可扩展的搜索解决方案。具体开通方式请参考[开放搜索快速入门]。
本示例中,开通OpenSearch之后在“华北2”区域新建了名为“oss_fc_search”的应用,类型为高级版,如下图所示。更多配置选项,请参考[应用类型]以及具体需求选择。

应用创建成功后,根据业务场景编辑您的应用结构,包括定义数据表,字段以及分词类型。详细配置说明请参考[字段类型和分词类型]
本示例是针对文本文档创建索引,创建了一个main数据表,采用常规的字段,如title,author,content等等,并使用中文基础分词。如下图所示:

3.开通函数计算(Function Compute)
函数计算是一个事件驱动的全托管计算服务,用户编写代码上传到函数计算,然后通过SDK或者RESTful API来触发执行函数,也可以通过云产品的事件来触发执行函数。具体开通方式请参考函数计算快速入门。
本示例开通函数服务后,在“华北2”区域新建名为“oss-fc-search”的服务,如下图所示:
服务创建成功后,开始创建函数。将本文提供的java代码,pom文件build成jar包上传。

package SearchDemo;
import com.aliyun.fc.runtime.*;
import com.aliyun.opensearch.DocumentClient;
import com.aliyun.opensearch.OpenSearchClient;
import com.aliyun.opensearch.sdk.dependencies.com.google.common.collect.Maps;
import com.aliyun.opensearch.sdk.generated.OpenSearch;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchClientException;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchException;
import com.aliyun.opensearch.sdk.generated.commons.OpenSearchResult;
import com.aliyun.oss.OSSClient;
import com.aliyun.oss.model.OSSObject;
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import java.io.*;
import java.util.*;
public class EventHandler implements StreamRequestHandler {
private static final String OSS_ENDPOINT = "YourOSSEndpoint";
private static final String OPENSEARCH_APP_NAME = "YourOpenSearchAppName";
private static final String OPENSEARCH_HOST = "YourOpenSearchHost";
private static final String OPENSEARCH_TABLE_NAME = "YourOpenSearchTableName";
private static final String ACCESS_KEY_ID = "YourAccessKeyId";
private static final String ACCESS_KEY_SECRET = "YourAccessSecretId";
private static final String DOC_URL_FORMAT = "http://%s.%s/%s";
private static final List<String> addEventList = Arrays.asList(
"ObjectCreated:PutObject", "ObjectCreated:PostObject");
private static final List<String> updateEventList = Arrays.asList(
"ObjectCreated:AppendObject");
private static final List<String> deleteEventList = Arrays.asList(
"ObjectRemoved:DeleteObject", "ObjectRemoved:DeleteObjects");
@Override
public void handleRequest(
InputStream inputStream, OutputStream outputStream, Context context) throws IOException {
/*
* Preparation
* Init logger, oss client, open search document client.
*/
FunctionComputeLogger fcLogger = context.getLogger();
OSSClient ossClient = getOSSClient(context);
DocumentClient documentClient = getDocumentClient();
/*
* Step 1
* Read oss event from input stream.
*/
JSONObject ossEvent;
StringBuilder inputBuilder = new StringBuilder();
BufferedReader streamReader = null;
try {
streamReader = new BufferedReader(new InputStreamReader(inputStream));
String line;
while ((line = streamReader.readLine()) != null) {
inputBuilder.append(line);
}
fcLogger.info("Read object event success.");
} catch(Exception ex) {
fcLogger.error(ex.getMessage());
return;
} finally{
closeQuietly(streamReader, fcLogger);
}
ossEvent = JSONObject.fromObject(inputBuilder.toString());
fcLogger.info("Getting event: " + ossEvent.toString());
/*
* Step 2
* Loop every events in oss event, and generate structured docs in json format.
*/
JSONArray events = ossEvent.getJSONArray("events");
for(int i = 0; i < events.size(); i++) {
// Get event name, source, oss object.
JSONObject event = events.getJSONObject(i);
String eventName = event.getString("eventName");
JSONObject oss = event.getJSONObject("oss");
// Get bucket name and file name for file identifier.
JSONObject bucket = oss.getJSONObject("bucket");
String bucketName = bucket.getString("name");
JSONObject object = oss.getJSONObject("object");
String fileName = object.getString("key");
// Prepare fields for commit to open search
Map<String, Object> structuredDoc = Maps.newLinkedHashMap();
BufferedReader objectReader = null;
UUID uuid = new UUID(bucketName.hashCode(), fileName.hashCode());
structuredDoc.put("identifier", uuid);
try {
// For delete event, delete by identifier
if (deleteEventList.contains(eventName)) {
documentClient.remove(structuredDoc);
} else {
OSSObject ossObject = ossClient.getObject(bucketName, fileName);
// Non delete event, read file content and more field you need
StringBuilder fileContentBuilder = new StringBuilder();
objectReader = new BufferedReader(
new InputStreamReader(ossObject.getObjectContent()));
String contentLine;
while ((contentLine = objectReader.readLine()) != null) {
fileContentBuilder.append('\n' + contentLine);
}
fcLogger.info("Read object content success.");
// You can put more fields according to your scenario
structuredDoc.put("title", fileName);
structuredDoc.put("content", fileContentBuilder.toString());
structuredDoc.put("subject", String.format(DOC_URL_FORMAT, bucketName, OSS_ENDPOINT, fileName));
if (addEventList.contains(eventName)) {
documentClient.add(structuredDoc);
} else if (updateEventList.contains(eventName)) {
documentClient.update(structuredDoc);
}
}
} catch (Exception ex) {
fcLogger.error(ex.getMessage());
return;
} finally {
closeQuietly(objectReader, fcLogger);
}
}
/*
* Step 3
* Commit json docs string to open search
*/
try {
OpenSearchResult osr = documentClient.commit(OPENSEARCH_APP_NAME, OPENSEARCH_TABLE_NAME);
if(osr.getResult().equalsIgnoreCase("true")) {
fcLogger.info("OSS Object commit to OpenSearch success.");
} else {
fcLogger.info("Fail to commit to OpenSearch.");
}
} catch (OpenSearchException ex) {
fcLogger.error(ex.getMessage());
return;
} catch (OpenSearchClientException ex) {
fcLogger.error(ex.getMessage());
return;
}
}
protected OSSClient getOSSClient(Context context) {
Credentials creds = context.getExecutionCredentials();
return new OSSClient(
OSS_ENDPOINT, creds.getAccessKeyId(), creds.getAccessKeySecret(), creds.getSecurityToken());
}
protected DocumentClient getDocumentClient() {
OpenSearch openSearch = new OpenSearch(ACCESS_KEY_ID, ACCESS_KEY_SECRET, OPENSEARCH_HOST);
OpenSearchClient serviceClient = new OpenSearchClient(openSearch);
return new DocumentClient(serviceClient);
}
protected void closeQuietly(BufferedReader reader, FunctionComputeLogger fcLogger) {
try {
if (reader != null) {
reader.close();
}
} catch (Exception ex) {
fcLogger.error(ex.getMessage());
}
}
}
pom.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>YourGroupId</groupId>
<artifactId>YourArtifactid</artifactId>
<version>1.0-SNAPSHOT</version>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.aliyun.fc.runtime</groupId>
<artifactId>fc-java-core</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>com.aliyun.fc.runtime</groupId>
<artifactId>fc-java-event</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>com.aliyun.oss</groupId>
<artifactId>aliyun-sdk-oss</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>com.aliyun.opensearch</groupId>
<artifactId>aliyun-sdk-opensearch</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
</project>
4.新建触发器并授权,参考创建触发器并授权

使用效果
1.在所有的服务、触发器都创建好后,我们来看使用效果。首先准备两个文本文档(文档内容如下),并上传到OSS:



2.进入开放搜索控制台,搜索测试:
搜索“杭州”,西湖.txt和阿里巴巴.txt都出现在搜索结果中,因为两个文档的内容中都包含“杭州”这个关键词。

搜索“电子商务”, 返回一个结果,只有阿里巴巴.txt中包含“电子商务”

3.在OSS删除文档后,OpenSearch中的数据也全部删除。

搜索“杭州”关键词,没有文档返回。