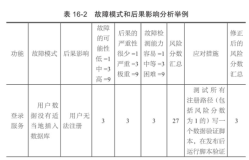
年初去某公司面试时,对方的项目经理问如果数据库现在很慢,你该怎么办,我问慢的现象是什么,数据库是被调用的不会莫名其妙就慢了,对方说什么都没有,就是慢了,你该怎么办?我说既然是这样,那就按老办法处理了:
1. 登陆机器用topas 、svmon -G、sar 1 100、ps aux 等,查看cpu、内存、交换区、磁盘的繁忙程度,看下是否有占系统资源特别大的进程。
2. 查 v$session_event、v$session_wait 看是否有大量的 latch free、enqueue、 free buffer waits等等待事件,看下归档日志的文件系统是否满了。
3. 如有占系统资源特别大的进程,通过v$process和v$session两个视图找到 Oracle进程的sid,serial#,把它用 Alter system kill session ‘sid,serial#’;杀掉;如果是归档日志满了,就清理日志。
4. 通过上面操作,表面现象基本会消除,下来再慢慢分析是什么原因引起的慢,是应用服务引起的、还是业务逻辑引起的、还是sql的性能引起的,找不到本质它还会慢的。
写上面那段话,想要说明什么目的呢?其实很简单,就是想说明,任何故障都是有原因的,都是有表面现象的,说没有任何现象那是扯蛋,而且这一类的信息系统也就那么几类故障,绝对不会发生像动车追尾的事故,所以在发生故障时,观察现象是很重要的,对于一个有经验的人来说,从现象上就能基本判定是哪里的问题,
所以我们一定要提醒和引导报障人,报告故障时:
1. 要详细的说出故障的现象,说不清时就截图,图片更加一目了然。
2. 故障的时间点,通过时间点可以找到相关日志,还能了解到相关的人员在此时间做了什么操作,必定能操作系统的也就那几个人。
3. 故障的影响范围,是几个人用不了,还是很多人或者全用不了。如果影响了几个人,那肯定不是服务的问题,就不用去查服务了,直接去检查终端(有时也不能全凭经验,也要谨慎点);如果是影响范围很大,那就直接查看监控服务(如F5,每台服务的运行状态一目了然)。
4. 通过上面的几步已经基本确定故障了,下来尽快恢复系统正常运行,然后再慢慢分析故障原因。
5. 通过查找上面时间点的系统故障日志,基本会看到相关的错误信息的,如调用了那个数据库对象、返回了什么oracle的错误、写了什么java异常信息;如果没找到或者几百M的日志不好找,那只能模拟测试看故障能否再重现,一般有详细的操作步骤,故障大多能重现的。
6. 如果是Java 问题就去分析相关的jap、java文件、配置文件(或web服务的配置文件)等。
7. 如果日志记录了数据库对象的信息,那更简单,直接去test下相应的数据库对象,不是逻辑问题就是sql性能问题。
8. 修改找到的问题,形成案例集,避免类似故障下次再次发生。
上面提到的只是日常故障的基本处理思路,不说处理方法,很多时候思路比方法更加重要,好多时候不是我们不会处理,而是我们没有处理的思路,不知道下一步该朝那走,这样就麻烦了。
根据多年系统的故障来看,60%都是人为造成的,40%才是系统自身产生的故障,在系统产生的故障中大部分都是业务逻辑、sql性能引起的,还有一小部分是网络、硬件引起的。sql性能方面的主要有以下:
1. 没有使用正确的索引,如语句中写的是组合索引、函数索引,但表上没有建立相应的索引,或着是没把组合索引字段放在最前面。
2. 分区表没建立本地索引,或者是建了本地索引但没有用到分区字段。
3. 多表连接时基表没有选好,或者是where条件没有明确指定各表的连接条件,或者是过滤最大数据的条件没有放在后面。
4. 使用了不必要的类型转换,特别是字符型与数值型的比较,这点很容易疏忽。
5. 对列进行了不必要的操作,包括数据库函数、计算表达式等。
例:
select * from record where substrb(CardNo,1,4)='0757'
select * from record where amount/30< 1000
select * from record where to_char(begintime,'yyyymmdd')='20101201'
6. 使用了 in 、not in 、exists、 not exists 等,应使用外连接outer joins 。
7. 使用了不必要的索引,应该用 +0 或 || '' 使索引失效。
8. 使用了复杂的group by分组计算条件。
9. 大数据量时,增加查询的范围限制,避免全范围的搜索。
10. 条件中用到or 、null、not null、<>、like 等操作符。
11. 中间表、临时表数据不及时truncate,历史表数据没有及时清理,索引没有定期重建等都会引起sql性能的低下。
上面写的只是日常故障的基本处理思路和影响sql性能的一些可能点,随着系统运行的时间加长,还会有其它的问题出现,还会挖掘更多的隐患,只有那样才能触进系统更加健康良好的运行。
1. 登陆机器用topas 、svmon -G、sar 1 100、ps aux 等,查看cpu、内存、交换区、磁盘的繁忙程度,看下是否有占系统资源特别大的进程。
2. 查 v$session_event、v$session_wait 看是否有大量的 latch free、enqueue、 free buffer waits等等待事件,看下归档日志的文件系统是否满了。
3. 如有占系统资源特别大的进程,通过v$process和v$session两个视图找到 Oracle进程的sid,serial#,把它用 Alter system kill session ‘sid,serial#’;杀掉;如果是归档日志满了,就清理日志。
4. 通过上面操作,表面现象基本会消除,下来再慢慢分析是什么原因引起的慢,是应用服务引起的、还是业务逻辑引起的、还是sql的性能引起的,找不到本质它还会慢的。
写上面那段话,想要说明什么目的呢?其实很简单,就是想说明,任何故障都是有原因的,都是有表面现象的,说没有任何现象那是扯蛋,而且这一类的信息系统也就那么几类故障,绝对不会发生像动车追尾的事故,所以在发生故障时,观察现象是很重要的,对于一个有经验的人来说,从现象上就能基本判定是哪里的问题,
所以我们一定要提醒和引导报障人,报告故障时:
1. 要详细的说出故障的现象,说不清时就截图,图片更加一目了然。
2. 故障的时间点,通过时间点可以找到相关日志,还能了解到相关的人员在此时间做了什么操作,必定能操作系统的也就那几个人。
3. 故障的影响范围,是几个人用不了,还是很多人或者全用不了。如果影响了几个人,那肯定不是服务的问题,就不用去查服务了,直接去检查终端(有时也不能全凭经验,也要谨慎点);如果是影响范围很大,那就直接查看监控服务(如F5,每台服务的运行状态一目了然)。
4. 通过上面的几步已经基本确定故障了,下来尽快恢复系统正常运行,然后再慢慢分析故障原因。
5. 通过查找上面时间点的系统故障日志,基本会看到相关的错误信息的,如调用了那个数据库对象、返回了什么oracle的错误、写了什么java异常信息;如果没找到或者几百M的日志不好找,那只能模拟测试看故障能否再重现,一般有详细的操作步骤,故障大多能重现的。
6. 如果是Java 问题就去分析相关的jap、java文件、配置文件(或web服务的配置文件)等。
7. 如果日志记录了数据库对象的信息,那更简单,直接去test下相应的数据库对象,不是逻辑问题就是sql性能问题。
8. 修改找到的问题,形成案例集,避免类似故障下次再次发生。
上面提到的只是日常故障的基本处理思路,不说处理方法,很多时候思路比方法更加重要,好多时候不是我们不会处理,而是我们没有处理的思路,不知道下一步该朝那走,这样就麻烦了。
根据多年系统的故障来看,60%都是人为造成的,40%才是系统自身产生的故障,在系统产生的故障中大部分都是业务逻辑、sql性能引起的,还有一小部分是网络、硬件引起的。sql性能方面的主要有以下:
1. 没有使用正确的索引,如语句中写的是组合索引、函数索引,但表上没有建立相应的索引,或着是没把组合索引字段放在最前面。
2. 分区表没建立本地索引,或者是建了本地索引但没有用到分区字段。
3. 多表连接时基表没有选好,或者是where条件没有明确指定各表的连接条件,或者是过滤最大数据的条件没有放在后面。
4. 使用了不必要的类型转换,特别是字符型与数值型的比较,这点很容易疏忽。
5. 对列进行了不必要的操作,包括数据库函数、计算表达式等。
例:
select * from record where substrb(CardNo,1,4)='0757'
select * from record where amount/30< 1000
select * from record where to_char(begintime,'yyyymmdd')='20101201'
6. 使用了 in 、not in 、exists、 not exists 等,应使用外连接outer joins 。
7. 使用了不必要的索引,应该用 +0 或 || '' 使索引失效。
8. 使用了复杂的group by分组计算条件。
9. 大数据量时,增加查询的范围限制,避免全范围的搜索。
10. 条件中用到or 、null、not null、<>、like 等操作符。
11. 中间表、临时表数据不及时truncate,历史表数据没有及时清理,索引没有定期重建等都会引起sql性能的低下。
上面写的只是日常故障的基本处理思路和影响sql性能的一些可能点,随着系统运行的时间加长,还会有其它的问题出现,还会挖掘更多的隐患,只有那样才能触进系统更加健康良好的运行。
本文转自 149banzhang 51CTO博客,原文链接:http://blog.51cto.com/149banzhang/1007193,如需转载请自行联系原作者