

为了从大数据中挖掘出有价值的信息,需要有针对大数据的数据处理系统。目前,一些大型的互联网企业,例如谷歌、Facebook 等企业都研发了针对大数据的数据处理系统。
1)批量数据处理系统:
这种系统是对互联网中产生的海量的静态的数据进行处理。例如对客户在网站中的点击量和网页的浏览量等数据进行处理,从而或者客户对哪些商品比较偏爱。谷歌公司研发的 GFS(Google File System,即大规模分散文件系统)和 Map Reduce(大规模分散 Frame Work)系统就是典型的批量数据处理系统。

2)流式数据处理系统:
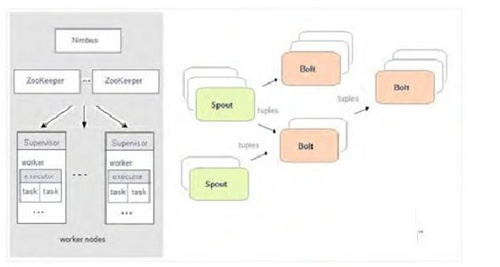
这种系统是对互联网中大量的在线数据进行实时处理。这些在线数据具有复杂的格式,并且数据是连续不断地来源于众多的渠道,该种系统需要对这些实时的数据进行实时的、快速的处理。例如生物体中传感器的数据、商场人流量数据、定位系统的数据都需要高效地实时处理。Storm系统是典型的流式数据处理系统,Twitter、Spotify、雅虎等公司都使用该系统。
3)交互式数据处理:
这种数据处理系统可以用人机交互的方式实现数据的处理。例如互联网搜索引擎。Dremel 系统是典型的交互式数据处理系统。
4)图数据处理系统:
该种系统用于处理大数据中的图数据。例如社交网络中人与人之间的社会关系图数据。Spark系统是典型的图数据处理系统。

随着社交网络的发展、传感器的广泛应用、物联网的不断扩展,大数据已经深入我们生活的方方面面,针对大数据的处理也越来越深入,如何更高效的挖掘大数据中蕴藏的价值需要不断地研究和改进。
本文作者:佚名
来源:51CTO
