作为早期时间序列基础模型之一,Salesforce 开发的 MOIRAI 凭借其出色的基准测试性能以及开源的大规模预训练数据集 LOTSA 在业界获得了广泛关注。
本文在此前对 MOIRAI 架构原理的深入分析基础上,重点探讨其最新升级版本 MOIRAI-MOE。该版本通过引入混合专家模型(Mixture of Experts, MOE) 机制,在模型性能方面实现了显著提升。这一改进也与大语言模型模型采用的多专家机制形成了技术共鸣。
本文将系统性地分析以下核心内容:
- MOIRAI-MOE 的技术架构与实现机制
- MOIRAI 与 MOIRAI-MOE 的架构差异对比
- 混合专家模型在提升预测准确率方面的作用机理
- MOE 架构对解决时间序列建模中频率变化问题的技术贡献
MOIRAI 与 MOIRAI-MOE 的技术对比
MOIRAI-MOE 采用纯解码器架构,通过混合专家模型实现了频率无关的通用预测能力,同时显著降低了模型参数规模。
图 1 展示了 MOIRAI 原始版本与 MOIRAI-MOE 的架构对比:
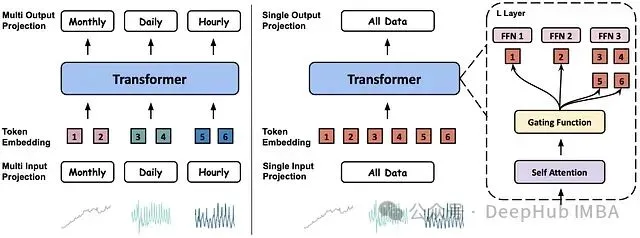
下面详细分析这些技术差异:
纯解码器架构的优化
MOIRAI-MOE 摒弃了 MOIRAI 最初采用的掩码编码器架构,转而采用纯解码器配置。
纯解码器的 Transformer 架构具有以下技术优势:
- 支持高效的并行训练
- 能够在单次更新中处理不同上下文长度的多个训练样本
虽然在推理方面,编码器架构通过单次前向传播即可完成多步预测,而纯解码器 Transformer 和 RNN 需要采用自回归方式逐步生成预测结果,但对 MOIRAI-MOE 而言,这一点并不构成性能瓶颈。这得益于其采用的稀疏混合专家模型(Sparse MOE)架构,该架构通过激活较少的参数,在推理效率上优于密集参数的 MOIRAI 模型。
在一项针对 MOIRAI、MOIRAI-MOE 和 Chronos 的对照实验中,在相同上下文长度条件下,MOIRAI-MOE 展现出更优的推理速度:

图 2:*不同模型变体的性能对比。括号内数值表示参数规模,对 MOIRAI-MOE 而言分别代表实际激活参数量和总参数量。*
实验数据显示,尽管 MOIRAI-MOE-Base 的总参数量是 MOIRAI-Large 的 3 倍,但由于 MOE 机制的作用,其实际仅激活 86M 参数,使得运行时间明显优于 MOIRAI-Large (370s vs. 537s)。
从技术实现角度看,MOIRAI-MOE 使用稀疏混合专家层替代了传统的全连接层。该层包含一个门控函数,用于计算路由分数并将输入分配给得分最高的 K 个专家。
MOIRAI-MOE 总共部署了 32 个专家,每个输入会激活其中得分最高的 2 个(TopK=2):
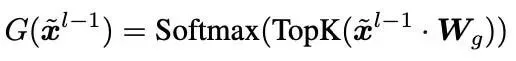
方程 1: 传统 MOE 模型中常用的基础门控函数
MOIRAI-MOE 对门控机制进行了创新性改进,用更精细的机制替代了简单的线性投影 W:
- 研究团队首先对预训练的 MOIRAI 模型的自注意力权重进行 K-Means 聚类,其中聚类数 M 等于专家总数
- 获得 M 个聚类中心点,每个专家对应一个聚类中心
- 在训练过程中,MOIRAI-MOE 不是从零开始学习门控函数(即方程 1 中的线性投影 W),而是基于输入与专家对应聚类中心的欧氏距离进行专家分配
由此,门控方程优化为:
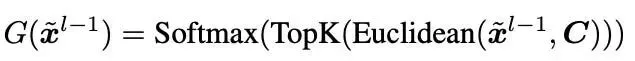
方程 2: MOIRAI-MOE 采用的基于 token 聚类的改进门控函数
其中 x 表示 MOE 层的输入向量,C 表示聚类中心集合。
基准测试结果表明,这种基于 token 聚类的策略具有显著优势:
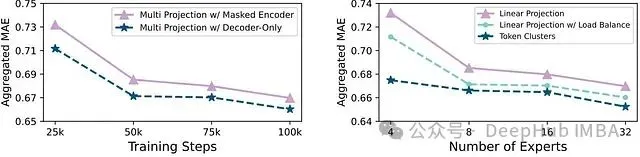
图 3:*两种关键设计的实验对比: (左)编码器与解码器架构在 10 万训练步后的 MAE 对比;(右)token 聚类策略的性能优势。*
研究发现,聚类中心能够有效捕获结构化数据模式,从而提升路由准确性和整体性能。此外图 6** 也验证了纯解码器架构相比 MOIRAI 原始编码器架构的优势。
需要注意的是,编码器架构更适合整合未来已知变量,这是原始 MOIRAI 的一个重要特性。目前尚需通过代码验证纯解码器架构是否能够保持这一功能。不过 MOIRAI-MOE 仍然保留了使用历史协变量的能力。
MOE 层对多 Patch 层的替代优化
原始 MOIRAI 模型采用多 Patch 层设计,通过学习不同粒度的特定 patch 尺寸来处理多频率问题。
对任何时间序列基础模型而言,多频率处理都是一个关键挑战。MOIRAI 通过多 Patch 层解决这一问题,该层根据用户指定的数据集频率将输入映射到不同的 patch 长度。
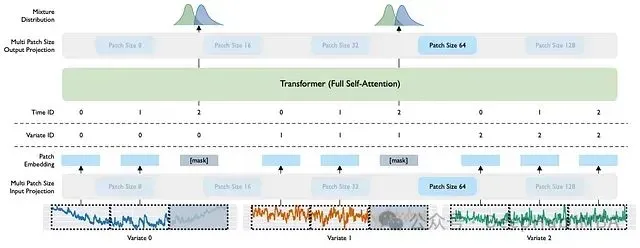
图 4:*MOIRAI 的架构示意图,采用 64 大小的 patch 处理小时或分钟级数据。*
之前的分析也指出,多 Patch 层在某种程度上模拟了混合专家系统的行为。现在 MOIRAI-MOE 直接使用单一投影层代替多 Patch 层,并利用 MOE 机制处理不同频率的数据。
为什么原始的多 Patch 层方案存在局限性?混合专家模型为什么能更好地处理频率问题?
这是因为时间序列数据通常包含多个子频率。此外,不同频率的序列可能共享相似模式,而相同频率的序列却可能表现迥异。因此,简单地通过频率标记来区分数据并不总是准确的:
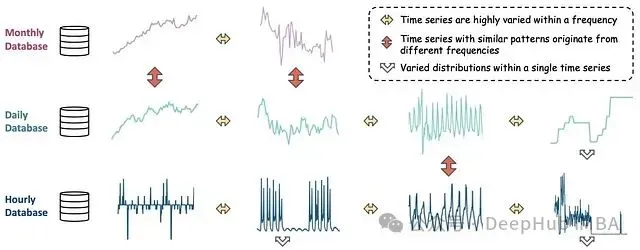
图 5:*不同频率的时间序列可能表现出相似模式,而同频率序列可能有显著差异。*
混合专家模型通过以下方式优化了 MOIRAI:
- 无需用户手动指定频率参数
- 采用数据驱动的路由机制,将时间序列自动分配给最适合的专家模型
通过引入混合专家模型,MOIRAI-MOE 摆脱了人工设定的频率启发式方法,实现了自动化的专家分配机制。
事实上,MOIRAI-MOE 专门为时间序列预测设计了增强型的 MOE 机制,这将在下一节详细讨论。
3. 注意力机制的改进
基于纯解码器架构,MOIRAI-MOE 将任意变量注意力机制替换为类 GPT 的因果自注意力机制。
目前尚无法确认新模型是否保留了类似 ROPE、SwiGLU 激活函数或 RMSNorm 等 LLM 特性,这些细节需要等待代码发布后验证。
但模型的输出形式保持不变:MOIRAI-MOE 不直接预测时间点值,而是预测混合分布的参数,再通过采样生成预测结果。训练目标仍然是最小化混合分布的负对数似然。
因此,MOIRAI-MOE 本质上是一个概率模型。可以通过保形分位数回归等技术增强其不确定性量化能力,实现预测区间的生成(因为模型可以输出分位数预测)。
MOIRAI-MOE 架构详解
研究提出了两种 MOIRAI-MOE 变体,如图 6所示:

图 6:*MOIRAI 与 MOIRAI-MOE 的架构细节对比*
MOE 机制为 MOIRAI 带来了显著提升。那么,各个专家究竟学习到了什么? 它们如何协同处理不同频率的数据?
研究团队分析了不同层级专家激活的分布情况,特别关注了不同频率数据的处理模式。图 7 展示了分析结果:
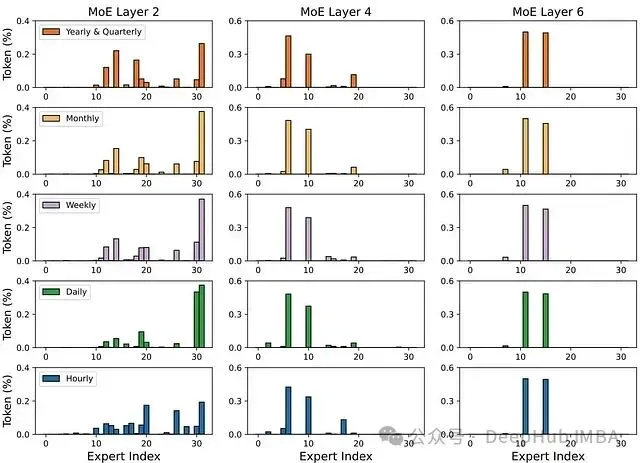
图 7:*第 2、4、6(最后)层中专家分配的频率分布可视化。*
对分析结果的深入解读:
x 轴代表专家编号(1-32),y 轴表示路由到各专家的数据比例。在浅层网络中,专家分配呈现多样化特征,不同频率的数据被分配给不同的专家处理。
随着网络层次加深,模型的关注点逐渐从频率特征转向时间序列的普适特征(如趋势性和季节性模式)。
这与语言模型中的 MOE 表现出明显差异:语言模型在浅层倾向于激活少量专家,而深层则呈现更大的多样性。这种差异可能源于时间序列数据本身的特性 - 相比于来自固定词表的 NLP tokens,时间序列数据通常包含更多噪声且具有动态特性。
值得注意的是,部分专家的激活频率较低,这提示在未来的优化中可考虑对这些专家进行剪枝处理。
基于以上分析可以得出结论:
在时间序列基础模型中,混合专家系统实现了一个分层的降噪过程 - 浅层专家主要处理频率相关特征,深层专家则关注更普适的模式(如长期趋势和季节性)。
MOIRAI-MOE 性能评估
MOIRAI-MOE 在与原始 MOIRAI 相同的 LOTSA 数据集上进行了预训练,该数据集包含来自 9 个领域的 270 亿个观测值。
研究采用了实验确定的
patch_size = 16
。Small 和 Base 版本分别训练了 5 万轮和 25 万轮。考虑到 MOIRAI-MOE-Base 已达到 MOIRAI-Large 的性能水平,因此未训练 Large 版本。
评估分为两个场景:
- 分布外预测(零样本): 模型对 LOTSA 中未见过的数据集进行零样本预测,与在这些数据集上专门训练的 SOTA 模型进行对比。
- 分布内预测: 模型在 LOTSA 训练子集上微调,在测试子集上评估。
评估过程采用严格的标准:
- 对照组模型均经过充分调优,采用滚动预测方案。测试集包含最后 h×r 个时间点(h 为预测范围,r 为滚动窗口数)。
- 验证集取自紧邻测试集的预测范围,展示具有最低 CRPS 的最优模型。
- 分布内数据集包含不同频率的数据,确保测试的全面性。
零样本和分布内基准测试结果如图 8、图 9所示:
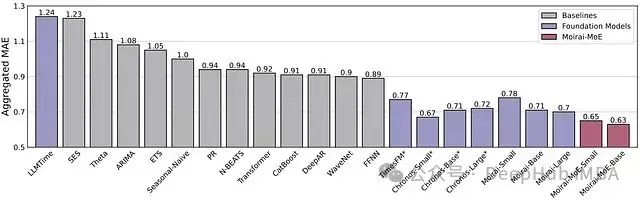
图 8:*分布内预测基准测试结果。LLTIME(粉色)基于 GPT-3.5 和 LLaMA-2。基础模型以紫色标示。*
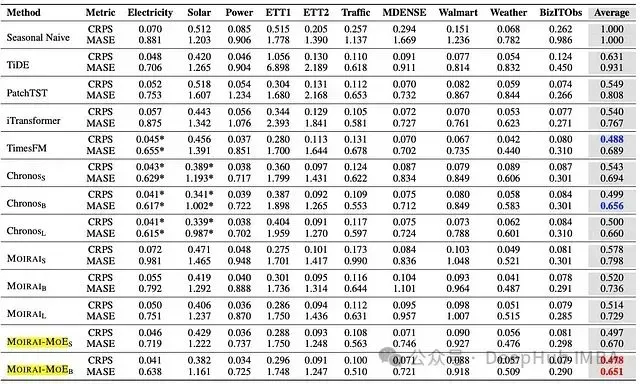
图 9:*MOIRAI-MOE 与其他基础模型及深度学习模型在分布外零样本预测的对比。 最优结果以红色突出显示,次优结果以蓝色标示。*平均列经过 Seasonal Naive 归一化。
零样本测试中,MOIRAI-MOE-Base 取得最优综合成绩,超越其他基础模型和全参数模型。结果表明基础模型普遍优于传统统计、机器学习和深度学习模型。
分布内测试中,MOIRAI-MOE-Base 同样位居榜首,TimesFM (CRPS) 和 Chronos (MASE) 分列二三位。
在两项测试中,MOIRAI-MOE 均超越原始 MOIRAI,以 1/65 的激活参数量实现了 17% 的性能提升。部分基础模型的数据集标注星号,表示这些数据集包含在其预训练语料中。
值得一提的是,本次基准测试未包含基于 MLP 的强大基础预测模型 Tiny Time Mixers。但总体而言,实验结果令人振奋。尽管许多基础模型倾向于回避与全参数模型的直接对比,MOIRAI-MOE 展现出超越它们的实力。
总结
MOIRAI-MOE 标志着基础模型发展的重要里程碑,它在前代模型的基础上实现了显著突破。
更值得关注的是基础模型的迭代速度,特别是在模型及其预训练数据集开源的背景下。相比两年前 Monash 作为唯一的开放时间序列数据集仓库,如今的格局已发生显著改变。最后,作为一项成熟的机器学习技术,混合专家模型在时间序列基础领域的应用为未来发展开辟了新的方向,我们期待看到更多模型采用 MOE 架构。
论文链接:https://avoid.overfit.cn/post/e971572417b44af8b1f046cb471b6a21
作者: Nikos Kafritsas