向量检索服务 DashVector 免费试用进行中,玩转大模型搜索,快来试试吧~
了解更多信息,请点击:https://www.aliyun.com/product/ai/dashvector

目前信息检索(Information Retrieval)几乎都是使用深度学习系列的方法,即NeuIR(neural information retrieval)。而随着预训练在深度学习领域的大放光芒,信息检索中也出现了各种预训练策略。这篇文章博主将整理来自清华大学与中科院的信息检索综述,先上路径。
- Title:Pre-training Methods in Information Retrieval
- Link:https://arxiv.org/abs/2111.13853
背景
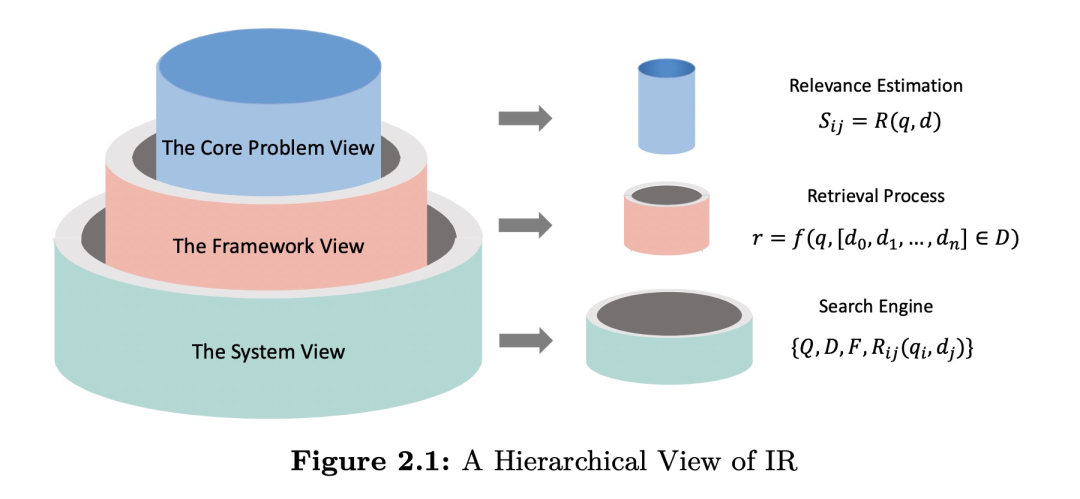
如上图展示的是看待搜索过程的三种角度,分别从注重相关度的核心问题(The core problem view),看重效率的整体框架(The framework view)和完整系统(The system view)的其他内容这三方面来展开。
(1)核心问题
IR系统的目标是提供用户所需的信息,因此它的核心问题是评估一个查询q和一个文档d之间的相关性。主要方法可以分为三类:传统检索模型、Learning to Rank (LTR) 模型和神经网络检索模型。
传统检索模型一般利用精确匹配信号来衡量相关性,如BM25等模型。
LTR模型分为Pointwise,Pairwise,Listwise三种。Pointwise只考虑一个单独的文档,将排序问题视作分类问题或者回归问题。Pairwise会考虑成对的文档,通过构造偏序对来优化模型。Listwise方法则直接考虑排序整个文档列表中所有的文档,如LambdaMart 模型。
神经网络模型也可以被分为基于表示的模型,基于交互的模型和混合模型。基于表示的模型分别给查询和文档学习一个特征表示,然后内积等方式计算两个表示的距离做为相关性得分,如DSSM。基于交互的模型主要刻画文档和查询之间的交互,即先计算一个由相似度组成的交互矩阵,然后从交互矩阵中以不同方式提取出用利于分析相关性的特征。最后是混合模型,即将以上基于表示的模型和基于交互的模型综合在一起。
而对于预训练在IR中的应用,也是基于Transformers等结构上计算相似度,并且可以很好的嵌入到以上各类。如基于表示的这类,使用Transformer-based的模型分别学习文档和查询的表示,然后计算这两个表示的相似度来表示相关性等等。而基于交互的方式,可以将文档和查询一起输入到Transformer-based模型上,以输出的[CLS]经过一个前馈网络获取相关度分数。
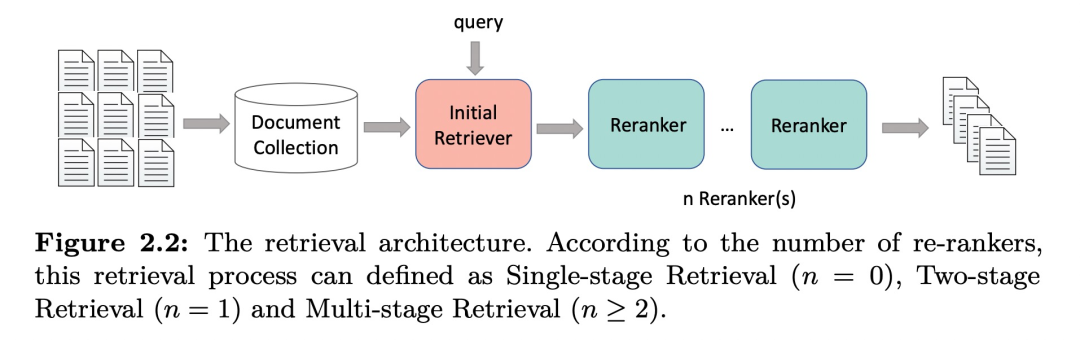
(2)框架
由于需要检索的整个文档集合很大,IR系统除了考虑质量(即相关度)以外还需要考虑效率。因此在框架上往往采取多阶段的结构,如上图所示,IR系统在框架上由多个re-rankers组件组成,即通常所说的召回,重排等等。根据re-rankers的数量,框架可以被定义成以下几种方式:
- Single-stage Retrieval (n=0):即没有多阶段操作,而是直接使用单个retriever返回的列表作为最终结果返回给用户。
- Two-stage Retrieval (n=1):相比于单阶段检索,现有的IR框架会额外使用一个re-ranker来提升排序列表的质量。在这一re-ranker阶段中,通常一会使用一些更精细的特征,如多模态特征,知识图谱特征等。
- Multi-stage Retrieval (n>=2):这种框架采用多个re-ranker,其中不同的re-ranker采用着不同的结构,可以分别利用不同的互补信息。
而将预训练应用到IR中时,也同样需要考虑效率与质量的权衡,这个权衡随着阶段的不同而不同。比如对于更关注效率的第一阶段检索,可以基于BERT的dual-encoder获取文档和查询中融合了上下文的term embeddings。而在后面的多个re-ranking重排阶段,预训练方法可以捕捉到更多细粒度的信息。

(3)系统
除了需要考虑效率和质量外,IR系统还要对用户足够友好,即要能够解决各种用户使用过程中容易出现的问题。比如用户所实际使用的查询query可能很短,很模糊,甚至有拼写错误。因此如上图所示,一般需要配备query parser和doc parser来处理。
对于query来说,parser需要将原始的查询转换成能够反映真实用户意图的查询表示,具体需要做的事情包括重写rewriting, 扩展expansion等。而在doc端,由于不同的网页可能有不同的页面结构和组织形式,因此paser的作用主要是用于处理文档和建立索引,以使文档能够被快速找到。
就发展历史来说,IR系统是从symbolic search system逐渐过渡到neural search system。
symbolic search system。即通过规则来构建parser来构建倒排索引,过滤文档并给文档排序。symbolic search系统的优点是可以快速检索,结果具有可解释性,缺点是只能使用一种语言,且需要很高的维护成本。
neural search system。相比于symbolic search system的精确匹配,neural search system刻画的是语义匹配。它使用文档的低维表示来计算相关性,即向量索引。neural search系统更鲁棒,更易于扩展(增加文档不需要改变已经建好的索引,只需要新增向量),但缺点在于可解释性差,同时需要大量的数据用于训练模型。
从这个角度上,预训练的应用可以为不同的系统而定制,如使用BERT作为backbone来做查询扩充、生成query suggestion,预测词权重并替代倒排索引中用到的原始词权重等等等等。
召回(Retrieval)阶段的具体应用
从表示的类型和索引模式,作者将语义检索模型分成三个类别:
- Sparse Retrieval Models:通过获得刻画语义的稀疏文档表示并建立倒排索引来提升检索效率。
- Dense Retrieval Models:通过将输入文本(查询和文档)映射到独立的稠密表示,并使用近似最近邻算法来做快速检索。
- Hybrid Retrieval Models:结合以上两者。
Sparse Retrieval Models
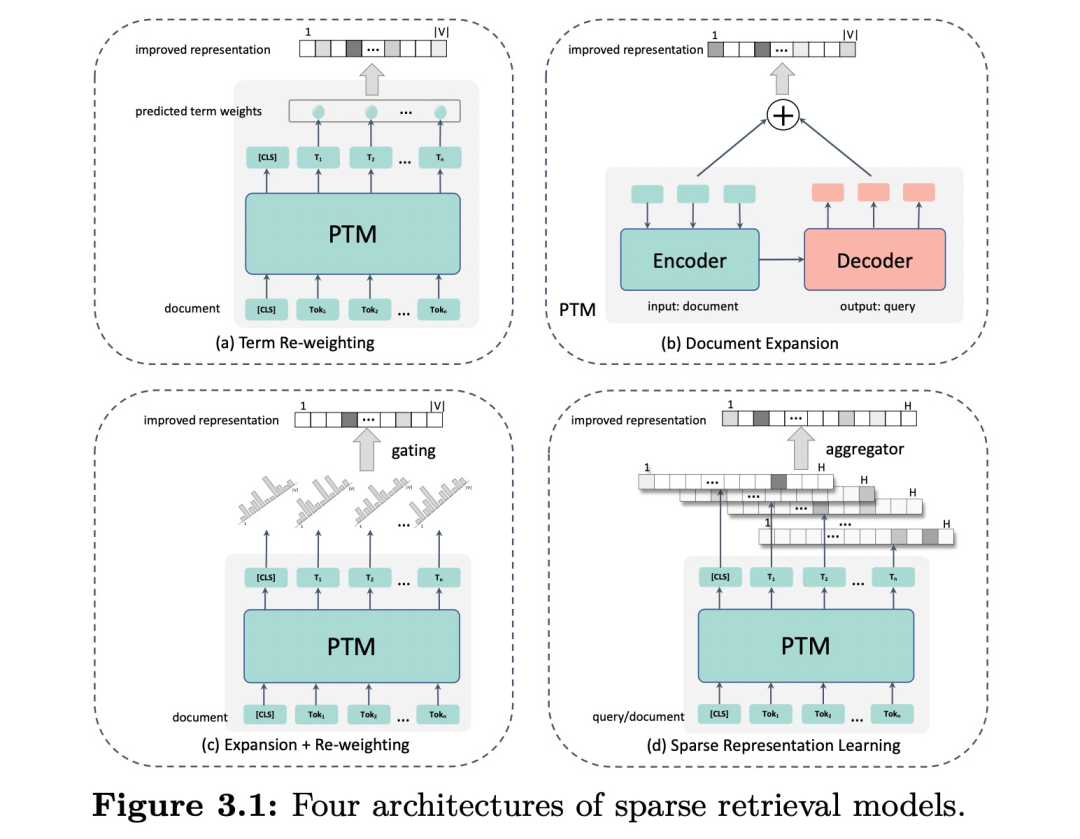
主要通过获得更好的文本表示来提升检索效果,可分为四类,如下图,包括term re-weighting(上下文空间的语义替代固定的词权重), document expansion(增加语义来扩充文档), expansion + re-weighting(结合两者)和sparse representation learning(在隐空间内学习查询和文档的稀疏表示)。
Dense Retrieval Models
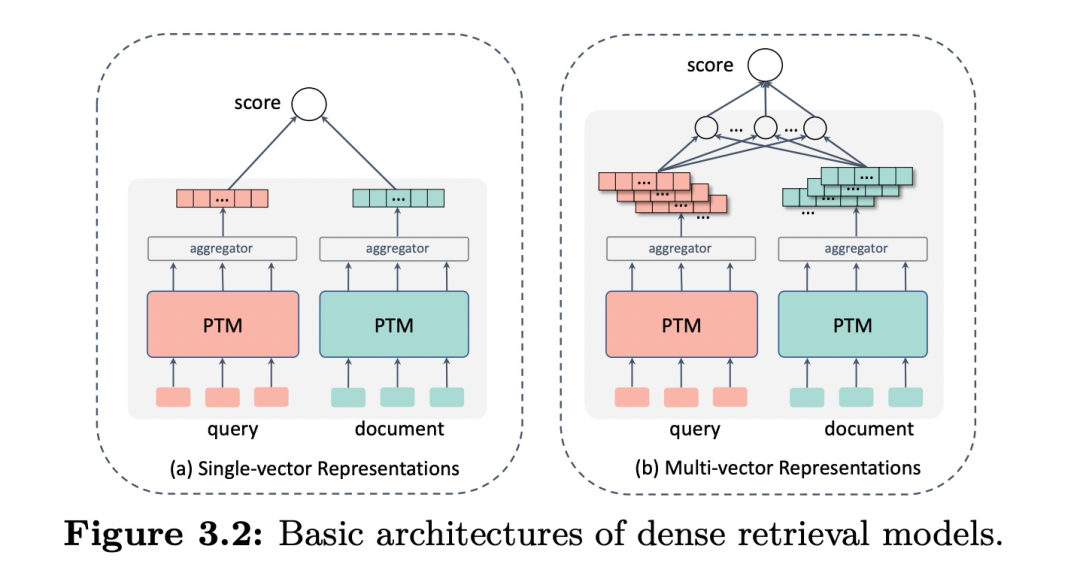
dense一般使用双塔结构来学习查询或文档的低维稠密表示,然后再用这些稠密表示构建索引,并通过近似最邻近算法(ANN)在线上执行检索任务。
具体也分single-vector representations (如下图左),每次只使用一个向量表示;而multi-vector representations (图右),则每次使用多个向量表示。
优化方法主要可以通过
增强预训练表征能力;
设计合适的下游任务来贴合检索;
改进fine-tuning;
大规模和更有效率的学习方式。
Hybrid Retrieval Models
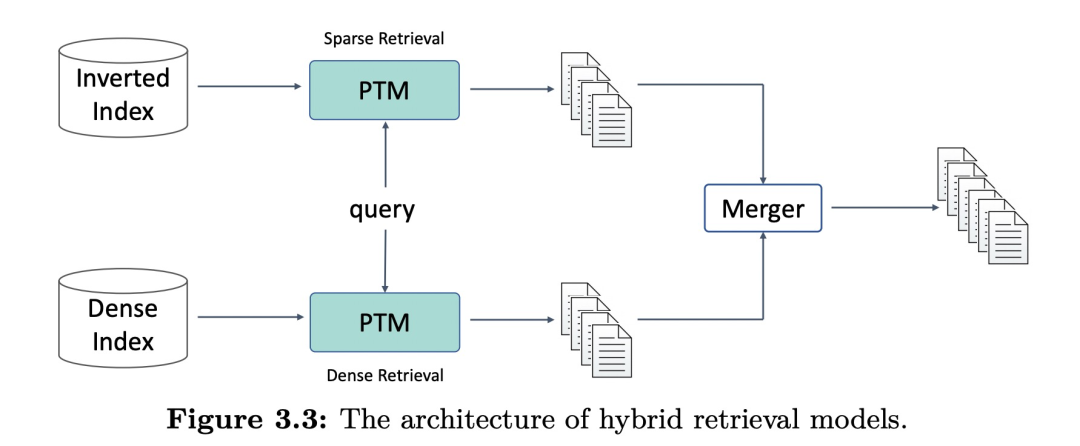
Sparse retrieval模型使用词,可以精确匹配信号且有解释性。另一方面,dense retrieval方法学习embeddings来编码语义,这种基于soft match信号的可以有更好的泛化性。因此综合两种模型构建一个混合检索模型可能是个不错的方向,其架构如下图,混合检索模型同时做sparse和dense,然后通过某种merging策略来综合匹配分数。
召回阶段的应用后,接下来是重排阶段的应用。
重排(Re-ranking)阶段的具体应用
对于搜索领域来说,多阶段级联架构非常普遍,因此考虑到基于Transformers预训练模型的巨大计算开销,它们通常被使用在最后一个阶段的re-ranker重排过程中,在很小的文档集合中学习精细的表示。
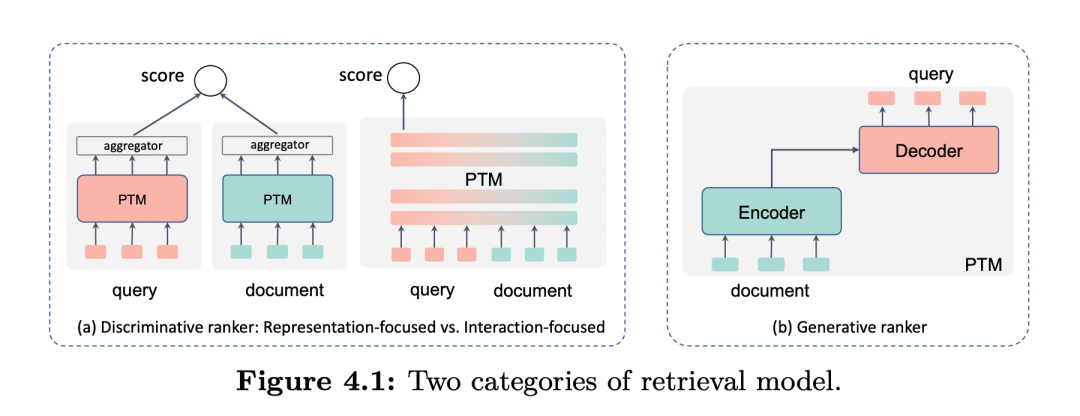
分为两个流派,判别式模型和生成式模型。判别式模型直接学习一个分类器,而生成式模型估计真实的相关性分布,因此预训练模型也可以被分成三类:重点关注判别任务的预训练模型(BERT),重点关注生成任务的预训练模型(GPT),以及同时关注判别和生成任务的预训练模型(T5)。
判别式排序模型
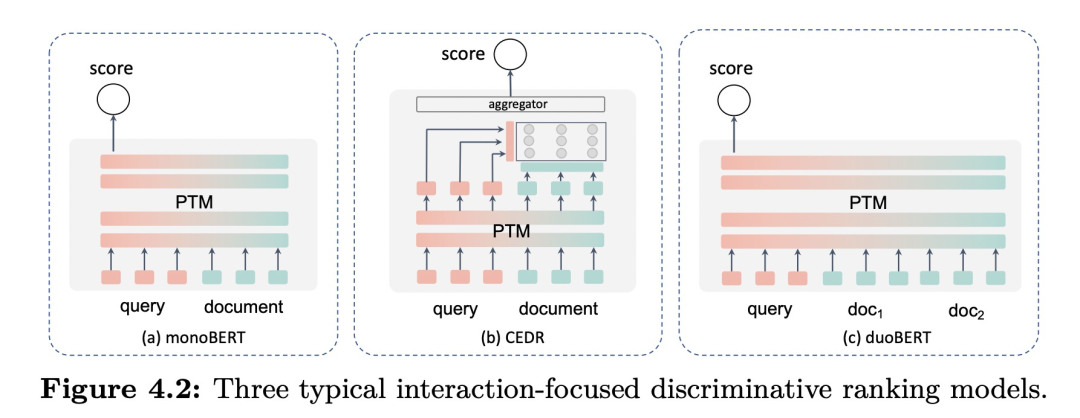
基于排序特征的不同被分成了两个类别:基于表示的框架Representation-focused和基于交互的框架Interaction-focused,如上图左侧是两者的对比。此外,对于长文本的处理,可以使用段落分数聚合(passage score aggregation)与段落表示聚合(passage representation aggregation)来解决。在模型加速方面,也有知识蒸馏和动态建模可以采用。
生成式排序模型
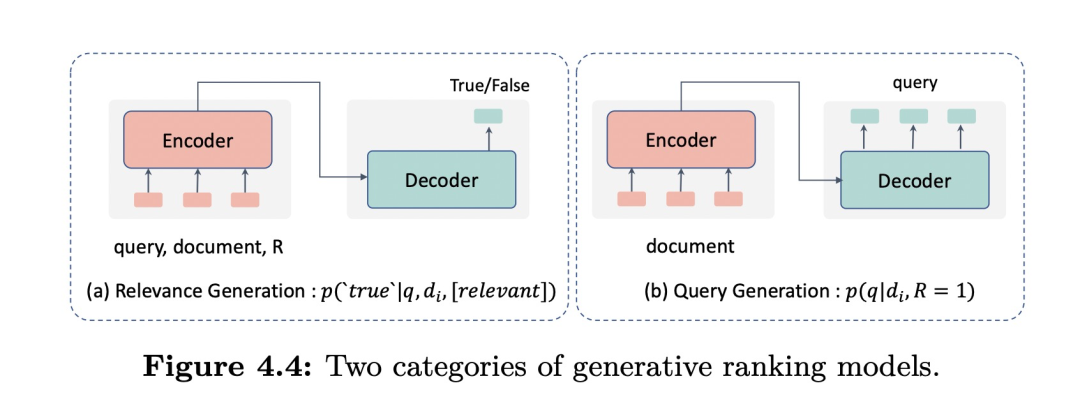
基于不同的生成过程,这些工作可以被分为relevance generation(生成相关度标签)和query generation(由文档生成查询然后完成检索)这两类。
其他组件上的具体应用
在query理解上
query expansion。解决vocabulary mismatch问题或者是用于缓解查询与文档之间语言的差别。可以基于关键词扩充,或者分块扩充。
query rewriting。主要处理长尾和使句子表达清晰。可以使用现有模型如T5直接生成一个更符合语义的句子,也可以结合历史记录进行语言理解。
query suggestion。提供给用户很多可选择的下一个查询,从而帮助用户更轻松地完成他们的搜索任务。主要需要结合历史记录来改装现有预训练模型。
search clarification。主动咨询用户,以在返回结果之前降低不确定性,如对话式检索和对话系统中备受关注。
personalized search。个性化搜索中一个常见的策略是将用户的历史查询进行编码,来刻画用户的长期兴趣和短期兴趣。
在doc理解上:
document summarization。将文档压缩成一段精简的文本,同时保留主要的信息。分为extractive summarization和abstractive summarization,一个直接选择句子,一个生成概括。
snippet generation。snippets只突出文档中与给定查询相关的部分。
keyphrase extraction。从文档中抽取关键词,大部分工作通常会将关键词提取任务视作序列标注任务。
未来工作
1,新的目标和框架。
2,充分利用多资源。特别是多模态、多语言和知识增强。
3,端到端的IR。
4,新的IR设计系统。从索引中心到模型中心。
免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector