在 MySQL 5.6 之前,InnoDB 在索引构建期间会对表进行排它锁定,这意味着其他会话无法读取或修改表中的数据,从而导致长时间阻塞和性能问题。
自 MySQL 5.6 起,InnoDB 开始采用一种名为“Online DDL”的技术,允许在不阻塞其他会话的情况下创建或删除索引。Online DDL 针对不同的操作提供了多种实现方式,包括 COPY、INSTANT 和 INPLACE。
由于 DDL 涉及多种操作,如索引创建、字段增加和外键添加等,因此不同操作的支持方式也各不相同。具体支持方式可参考 MySQL 官方文档(https://dev.mysql.com/doc/refman/5.7/en/innodb-online-ddl-operations.html)。
以索引创建为例:

从上文可见,当我们创建、删除或重命名索引时,会采用“in place”的模式。
需要注意的是,尽管 Online DDL 能够减少锁定时间和对性能的影响,但在索引构建期间仍可能出现锁定和阻塞情况。例如,在添加索引时,如果表中存在大量未提交的事务,则需要等待这些事务提交后才能开始索引构建。因此,建议在非高峰时段进行此类操作,以避免影响用户的正常使用。在执行任何 DDL 操作之前,最好进行充分的测试和规划,并确保有备份和回滚计划,以应对意外情况。
扩展知识
什么是 Online DDL
DDL,即数据定义语言(Data Definition Language),用于定义数据库结构的操作。DDL 操作包括创建、修改和删除数据库中的表、索引、视图、约束等数据库对象,而不涉及实际数据的操作。以下是一些常见的 DDL 操作:
- CREATE(创建)
- ALTER(修改)
- DROP(删除)
- TRUNCATE(截断)
相对应的是 DML,即数据操作语言(Data Manipulation Language),用于操作数据。包括我们常用的 INSERT、DELETE 和 UPDATE 等操作。
在 MySQL 5.6 之前,所有的 ALTER 操作实际上都会阻塞 DML 操作,例如添加或删除字段、添加或删除索引等,都会导致表被锁定。
然而,在 MySQL 5.6 中引入了 Online DDL,它是 MySQL 5.6 提出的一种加速 DDL 的方案,旨在尽可能保证 DDL 期间不会阻塞 DML 操作。但需要注意的是,并非所有的 DDL 语句都会利用 Online DDL 进行加速。
Online DDL 的优点在于可以减少阻塞,它是 MySQL 内置的一种优化手段。但需注意的是,在 DDL 开始和结束阶段,都需要获取 MDL 锁,如果在获取锁时存在未提交的事务,则 DDL 可能因为锁定失败而被阻塞,从而影响性能。
此外,如果 Online DDL 操作失败,其回滚操作可能会造成较高的成本。长时间运行的 Online DDL 操作也可能导致主从同步的延迟。
DDL 算法
在 MySQL 5.6 支持 Online DDL 之前,存在两种 DDL 算法,分别是 COPY 和 INPLACE。
我们可以使用以下 SQL 来指定 DDL 算法:
ALTER TABLE paidaxing_ddl_test ADD PRIMARY KEY (id) ,ALGORITHM=INPLACE,LOCK=NONE
copy 算法原理
- 创建一张临时表。
- 对原表加共享 MDL 锁,阻止对原表的写操作,仅允许查询操作。
- 逐行将原表数据拷贝到临时表中,且无需进行排序。
- 数据拷贝完成后,将原表锁升级为排他 MDL 锁,阻止对原表的读写操作。
- 对临时表进行重命名操作,并创建索引,完成 DDL 操作。
INPLACE 算法原理
INPLACE 算法是在 MySQL 5.5 中引入的,旨在优化索引的创建和删除过程的效率。其原理是尽可能地使用原地算法进行 DDL 操作,而不是重新创建或复制表。
- 创建索引数据字典。
- 对原表加共享 MDL 锁,阻止对原表的写操作,只允许查询操作。
- 根据聚集索引的顺序,查询表中的数据,并提取所需的索引列数据。将提取的索引数据进行排序,并插入到新的索引页中。
- 等待当前表的所有只读事务提交。
- 索引创建完成。
MySQL 中的 INPLACE 算法实际上分为两种:
- inplace-no-rebuild:对二级索引的增删改查、修改变长字段长度(例如:varchar)、重命名列名等操作都不需要重建原表。
- inplace-rebuild:修改主键索引、增加或删除列、修改字符集、创建全文索引等操作需要重建原表。
OnlineDDL 算法
前面提到,ALGORITHM 可以指定 DDL 操作的算法,目前主要支持以下几种:
- COPY 算法
- INPLACE 算法
INSTANT 算法:MySQL 8.0.12 引入的新算法,目前只支持添加列等少量操作。它利用了 8.0 新的表结构设计,可以直接修改表的元数据,省去了重建原表的过程,从而极大地缩短了 DDL 语句的执行时间。对于其他类型的改表语句,默认使用 inplace 算法。关于 INSTANT 支持的场景可参考官方文档 [Online DDL Operations]:https://dev.mysql.com/doc/refman/8.0/en/innodb-online-ddl-operations.html。
DEFAULT:如果不指定 ALGORITHM,MySQL 会自行选择默认算法。它优先考虑 INSTANT,其次是 INPLACE,然后是 COPY。
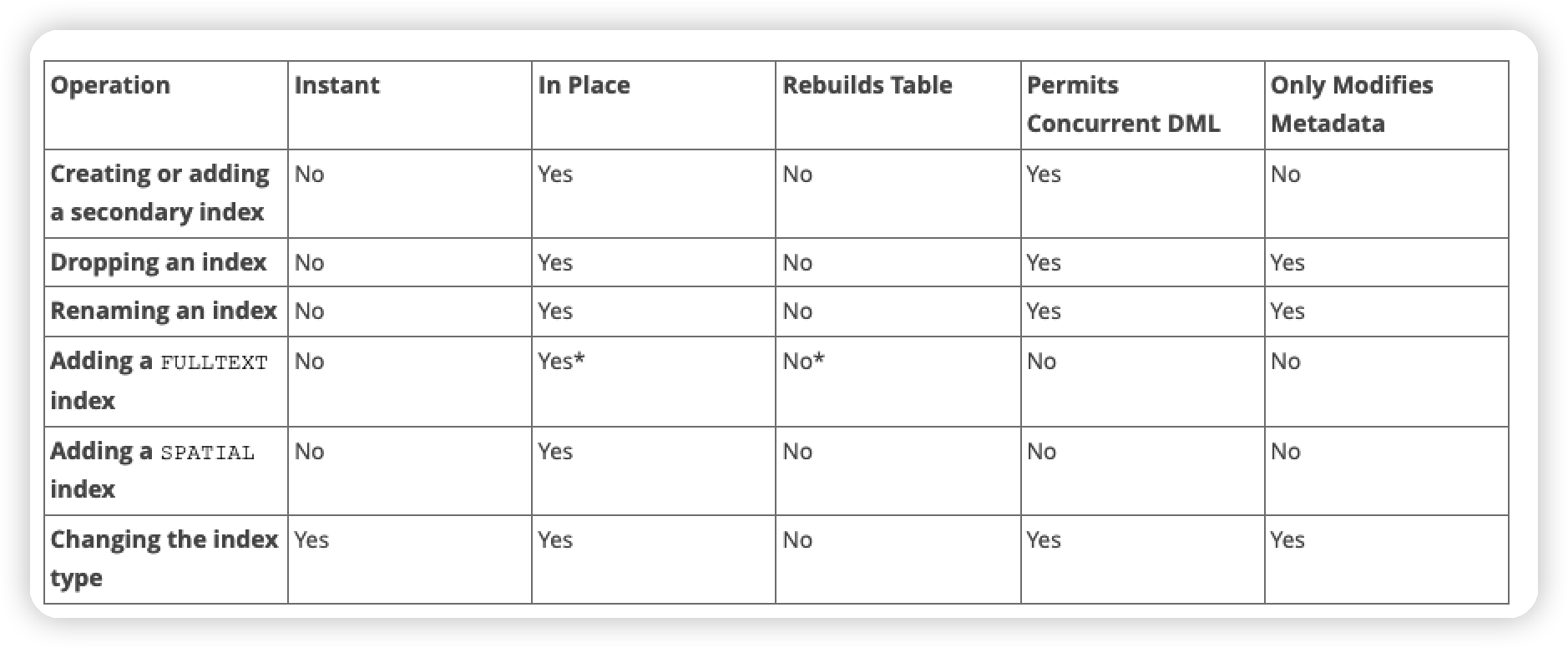
以下是 MySQL 官网上给出的 Online DDL 对索引操作的支持情况:
OnlineDDL 的原理
以下是 Online DDL 的整体步骤,主要分为 Prepare 阶段、DDL 执行阶段以及 Commit 阶段。
Prepare 阶段:
- 创建临时 frm 文件。
- 加 EXCLUSIVE-MDL 锁,阻止读写操作。
- 根据 ALTER 类型,确定执行方式(copy/online-rebuild/online-norebuild)。需要注意,如果使用 copy 算法,则不是 Online DDL。
- 更新数据字典的内存对象。
- 分配 row_log 对象,记录 Online DDL 过程中增量的 DML。
- 生成新的临时 idb 文件。
Execute 阶段:
- 降级 EXCLUSIVE-MDL 锁为 SHARED-MDL 锁,允许读写操作。
- 扫描原表聚集索引的每一条记录。
- 遍历新表的聚集索引和二级索引,逐一处理。
- 根据原表中的记录构造对应的索引项。
- 将构造的索引项插入 sort_buffer 块排序。
- 将 sort_buffer 块更新到新表的索引上。
- 记录 Online DDL 执行过程中产生的增量(online-rebuild)。
- 重放 row_log 中的操作到新表的索引上(online-not-rebuild 数据是在原表上更新)。
- 重放 row_log 中的 DML 操作到新表的数据行上。
Commit 阶段:
- 升级到 EXCLUSIVE-MDL 锁,阻止读写操作。
- 重做 row_log 中最后一部分增量。
- 更新 InnoDB 的数据字典表。
- 提交事务,写 redo log。
- 修改统计信息。
- 重命名临时 ibd 文件,frm 文件。
- 变更完成,释放 EXCLUSIVE-MDL 锁。
尽管 Prepare 阶段和 Commit 阶段也加了 EXCLUSIVE-MDL 锁,但操作非常轻量,因此耗时较低。Execute 阶段允许读写操作,并通过 row_log 记录期间的变更数据记录,最终应用这些变更到新表中,从而实现 Online DDL 的效果。