
clickhouse 是 OLAP 数据库,但其具有独特的索引设计,所以如果拿 MySQL 或者其他 RDB 的优化经验来优化 clickhouse 可能得不到很好的效果,所以特此单独整理一篇文档,用于有 SQL 优化需求的同学,本人接触 clickhouse 时间也不长,难免有不足的地方,如果大家发现错误,还请不吝指正。
快速查询处理的ClickHouse简介
ClickHouse的快速查询速度通常是通过适当利用表的(稀疏)主键索引来实现的,以极大地限制ClickHouse需要从磁盘读取的数据量,并防止在查询时重新排序数据,这也可以在使用LIMIT子句时启用短路实现。
ClickHouse主键索引的设计基于二分查找算法,该算法能够有效地(时间复杂度为O(log2 n))在排序数组中找到目标值的位置。
例如,考虑下面的排序数组,二分查找算法用于查找值42。该算法将目标值42与数组的中间元素进行比较。如果它们不相等,则排除目标不可能存在的半部分,并且在剩余的半部分上继续搜索,再次将中间元素与目标值进行比较,并重复此过程,直到找到目标值:

使用表的主索引在ClickHouse表中查找行的方式与此相同。
表的行按照表的主键列(们)的顺序存储在磁盘上。
根据行的顺序,主索引(像上面的图表一样是排序的数组)存储来自表的第8192行的主键列值。
在下面的图表中,我们假设一个具有列“numbers”的表,它也是主键列:

ClickHouse的主索引不是对个别行进行索引,而是对行的块(称为 granule)进行索引。
有了这样的主索引,可以跳过大量不需要的数据,因此可以在秒级别内进行搜索。
下图显示了ClickHouse通常如何执行查询:

第1步:将涉及表的主索引加载到主内存中。
第2步:通常通过对索引条目进行二分查找,ClickHouse选择可能包含与查询的WHERE子句匹配的行的块。
第3步:选定的行块并行流式读入ClickHouse查询引擎进行进一步处理,并将查询结果流向调用者。
ClickHouse中加速此查询执行工作流程的三个主要调整方向:
ClickHouse需要从磁盘流式传输到主内存的数据越少,查询的执行时间就越快。可以通过(1)适当利用主索引和(2)预先计算聚合来将从磁盘流式传输的数据量最小化。
数据的流式传输和实际处理可以通过(3)提高ClickHouse查询处理引擎内部使用的并行度来加快速度。
(1) 适当利用主索引
首先让我们看看如何确保充分利用主索引以确保最佳的查询性能。
利用索引从而最小化流入ClickHouse的数据量
我们以我们的英国房产价格支付教程中的表为例,该表有2764万行。此数据集可在我们的play.clickhouse.com环境中获得。
我们运行一个查询,列出了三个最高价格的伦敦郡:
SELECT county, price FROM uk_price_paid WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 ┌─county─────────┬─────price─┐ │ GREATER LONDON │ 594300000 │ │ GREATER LONDON │ 569200000 │ │ GREATER LONDON │ 448500000 │ └────────────────┴───────────┘ 3 rows in set. Elapsed: 0.044 sec. Processed 27.64 million rows, 44.21 MB (634.60 million rows/s., 1.01 GB/s.)
ClickHouse正在进行全表扫描!
因为表的主索引无法为查询充分利用。
我们检查表的主键:
SHOW CREATE TABLE uk_price_paid CREATE TABLE default.uk_price_paid ( `price` UInt32, `date` Date, `postcode1` LowCardinality(String), `postcode2` LowCardinality(String), `type` Enum8('other' = 0, 'terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4), `is_new` UInt8, `duration` Enum8('unknown' = 0, 'freehold' = 1, 'leasehold' = 2), `addr1` String, `addr2` String, `street` LowCardinality(String), `locality` LowCardinality(String), `town` LowCardinality(String), `district` LowCardinality(String), `county` LowCardinality(String), `category` UInt8 ) ENGINE = ReplicatedMergeTree('/clickhouse/tables/fb100991-4cae-4a92-995a-1ca11416879e/{shard}', '{replica}') ORDER BY (postcode1, postcode2, addr1, addr2) SETTINGS index_granularity = 8192 1 row in set. Elapsed: 0.001 sec.
表的ORDER BY子句确定数据在磁盘上的排序方式和主索引条目。ORDER BY中的列为postcode1,postcode2,addr1和addr2。
请注意,如果没有明确定义主键,ClickHouse将使用排序键(由ORDER BY子句定义)作为主键,即通过PRIMARY KEY子句。
这对于具有town = 'LONDON'谓词的查询没有帮助。
如果我们想要显著加速我们的示例查询以过滤具有特定城镇的行,则需要使用为该查询优化的主索引。
其中一种选择是创建具有基于不同主键的不同行顺序的第二个表。
由于表只能在磁盘上有一个物理顺序,我们需要将表数据复制到另一个表中。
我们创建了一个与原始表具有相同架构但具有不同主键的第二个表,并在表之间复制数据:
CREATE TABLE uk_price_paid_oby_town_price ( price UInt32, date Date, postcode1 LowCardinality(String), postcode2 LowCardinality(String), type Enum8('terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4, 'other' = 0), is_new UInt8, duration Enum8('freehold' = 1, 'leasehold' = 2, 'unknown' = 0), addr1 String, addr2 String, street LowCardinality(String), locality LowCardinality(String), town LowCardinality(String), district LowCardinality(String), county LowCardinality(String), category UInt8 ) ENGINE = MergeTree ORDER BY (town, price); INSERT INTO uk_price_paid_oby_town_price SELECT * FROM uk_price_paid; 0 rows in set. Elapsed: 13.033 sec. Processed 52.50 million rows, 2.42 GB (4.03 million rows/s., 185.58 MB/s.)
我们在第二个表上运行查询:
SELECT county, price FROM uk_price_paid_oby_town_price WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 ┌─county─────────┬─────price─┐ │ GREATER LONDON │ 594300000 │ │ GREATER LONDON │ 569200000 │ │ GREATER LONDON │ 448500000 │ └────────────────┴───────────┘ 3 rows in set. Elapsed: 0.005 sec. Processed 81.92 thousand rows, 493.76 KB (15.08 million rows/s., 90.87 MB/s.)
好多了!
利用索引来防止重新排序并启用短路
在我们的上一个示例中,ClickHouse不仅从磁盘上流出了更少的数据,还应用了额外的优化。
查询是:
- 过滤town = ‘London’的行
- 按价格降序排序匹配的行
- 获取前3行
为此,通常,ClickHouse:
- 使用主索引选择可能包含‘London’行的块,并从磁盘上流出这些行
- 按价格对这些行进行排序
- 将前3行作为结果流向调用者
但是,因为磁盘上的‘London’行已经按价格排序存储(请参阅表DDL的ORDER BY子句),ClickHouse可以直接跳过在主内存中重新排序。
而且ClickHouse可以进行短路。ClickHouse所需要做的就是以相反的顺序从磁盘上流出所选块的行,并且一旦流出了三个匹配(town = ‘London’)行,查询就完成了。
这正是在这种情况下optimize_read_in_order优化所做的 - 防止行重新排序并启用短路。
这个优化默认启用,当我们通过EXPLAIN检查查询的逻辑查询计划时,我们可以看到计划底部的ReadType:InReverseOrder:
EXPLAIN actions = 1 SELECT county, price FROM uk_price_paid_oby_town_price WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 Expression (Projection) Actions: INPUT :: 0 -> price UInt32 : 0 INPUT :: 1 -> county LowCardinality(String) : 1 Positions: 1 0 Limit (preliminary LIMIT (without OFFSET)) Limit 3 Offset 0 Sorting (Sorting for ORDER BY) Prefix sort description: price DESC Result sort description: price DESC Limit 3 Expression (Before ORDER BY) Actions: INPUT :: 0 -> price UInt32 : 0 INPUT :: 1 -> county LowCardinality(String) : 1 Positions: 0 1 Filter (WHERE) Filter column: equals(town, 'LONDON') (removed) Actions: INPUT :: 0 -> price UInt32 : 0 INPUT : 1 -> town LowCardinality(String) : 1 INPUT :: 2 -> county LowCardinality(String) : 2 COLUMN Const(String) -> 'LONDON' String : 3 FUNCTION equals(town :: 1, 'LONDON' :: 3) -> equals(town, 'LONDON') LowCardinality(UInt8) : 4 Positions: 0 2 4 ReadFromMergeTree (default.uk_price_paid_oby_town_price) ReadType: InReverseOrder Parts: 6 Granules: 267 27 rows in set. Elapsed: 0.002 sec.
optimize_read_in_order设置可以通过查询的SETTINGS子句禁用。这将导致ClickHouse从磁盘上流出217万行而不是8192行(仍然优于全表扫描)。以下图表显示了查询处理步骤的差异:

使用具有不同行顺序的第二个表的一个剩余问题是保持表的同步。在下面,我们将讨论这个问题的一个方便的解决方案。
(2) 预先计算聚合
我们执行一个聚合查询,列出了英国的县,按平均支付价格排序:
SELECT county, avg(price) FROM uk_price_paid GROUP BY county ORDER BY avg(price) DESC LIMIT 3 ┌─county──────────────────────────────┬─────────avg(price)─┐ │ WINDSOR AND MAIDENHEAD │ 383843.17329304793 │ │ BOURNEMOUTH, CHRISTCHURCH AND POOLE │ 383478.9135281004 │ │ GREATER LONDON │ 376911.4824869095 │ └─────────────────────────────────────┴────────────────────┘ 3 rows in set. Elapsed: 0.020 sec. Processed 26.25 million rows, 132.57 MB (1.33 billion rows/s., 6.69 GB/s.)
在这种情况下,ClickHouse 正在进行全表扫描,因为查询聚合了所有现有的表行。因此,无法使用主索引来减少从磁盘流入的数据量。
然而,如果我们可以为所有现有的 130 个英国县预先计算聚合值并在原始表数据更改时更新该单独的表,就可以大大减少从磁盘流入的数据量(通过牺牲额外的磁盘空间)。
以下图表现了这个想法:
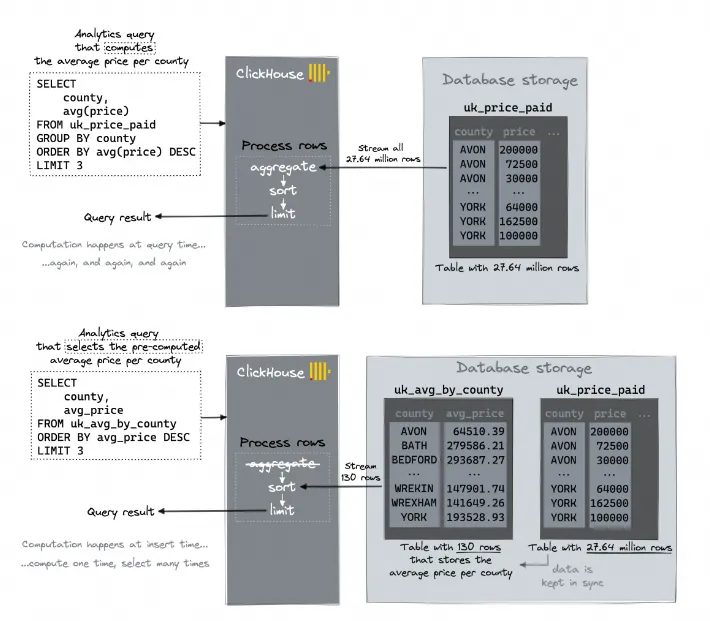
ClickHouse 有一个方便的新的即插即用功能来实现这个想法:投影Projections!
使用投影(Projections)来进行 (1) 和 (2)
ClickHouse 表可以有 (多个) 投影。
投影是一个额外的(隐藏的)表,它与原始表自动保持同步。投影可以具有不同的行顺序(因此具有不同的主索引)和自动和增量地预先计算聚合值。
当一个查询针对原始表时,ClickHouse 会自动选择(通过对主键进行抽样)一个可以生成相同正确结果的表,但需要读取的数据量最少。我们在这里展示了这个概念:

投影与材料化视图有些类似,后者也允许您进行增量聚合和多个行顺序。但与材料化视图不同,投影是原子更新的,并且通过在查询时自动选择最佳版本来保持与主表一致。
对于原始示例表 uk_price_paid,我们将创建(并填充)两个投影。
为了在我们的游乐场中保持事物整洁和简单,我们首先将表 uk_price_paid 复制为 uk_price_paid_with_projections:
CREATE TABLE uk_price_paid_with_projections AS uk_price_paid; INSERT INTO uk_price_paid_with_projections SELECT * FROM uk_price_paid; 0 rows in set. Elapsed: 4.410 sec. Processed 52.50 million rows, 2.42 GB (11.90 million rows/s., 548.46 MB/s.)
我们创建和填充投影 prj_oby_town_price - 一个额外的(隐藏的)表,具有主索引,按城镇和价格排序,以优化查询,该查询列出了特定城镇的县,用于最高的支付价格:
ALTER TABLE uk_price_paid_with_projections ADD PROJECTION prj_oby_town_price ( SELECT * ORDER BY town, price ); ALTER TABLE uk_price_paid_with_projections MATERIALIZE PROJECTION prj_oby_town_price SETTINGS mutations_sync = 1; 0 rows in set. Elapsed: 6.028 sec.
我们创建和填充投影 prj_gby_county - 一个额外的(隐藏的)表,它逐渐预先计算了所有现有的 130 个英国县的 avg(price) 聚合值:
ALTER TABLE uk_price_paid_with_projections ADD PROJECTION prj_gby_county ( SELECT county, avg(price) GROUP BY county ); ALTER TABLE uk_price_paid_with_projections MATERIALIZE PROJECTION prj_gby_county SETTINGS mutations_sync = 1; 0 rows in set. Elapsed: 0.123 sec.
请注意,如果在投影中使用了 GROUP BY 子句(如上面的 prj_gby_county 中),则(隐藏的)表的底层存储引擎将变为 AggregatingMergeTree,并且所有聚合函数都将转换为 AggregateFunction。这确保了适当的增量数据聚合。
此外,请注意强制同步执行的 SETTINGS 子句。
这是主表 uk_price_paid_with_projections 及其两个投影的可视化:

如果我们现在运行该查询,该查询列出了伦敦的县,以最高的支付价格为准,我们会看到性能上的巨大差异:
SELECT county, price FROM uk_price_paid_with_projections WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 ┌─county─────────┬─────price─┐ │ GREATER LONDON │ 594300000 │ │ GREATER LONDON │ 569200000 │ │ GREATER LONDON │ 448500000 │ └────────────────┴───────────┘ 3 rows in set. Elapsed: 0.026 sec. Processed 2.17 million rows, 13.03 MB (83.14 million rows/s., 499.14 MB/s.)
同样,对于列出英国的三个最高平均支付价格的县的查询:
SELECT county, avg(price) FROM uk_price_paid_with_projections GROUP BY county ORDER BY avg(price) DESC LIMIT 3 ┌─county──────────────────────────────┬─────────avg(price)─┐ │ WINDSOR AND MAIDENHEAD │ 398334.9180566017 │ │ GREATER LONDON │ 396401.2740568222 │ │ BOURNEMOUTH, CHRISTCHURCH AND POOLE │ 387441.28323942184 │ └─────────────────────────────────────┴────────────────────┘ 3 rows in set. Elapsed: 0.007 sec.
请注意,两个查询都针对原始表,两个查询在创建两个投影之前都会导致全表扫描(所有 27.64 百万行都会从磁盘流入)。
此外,请注意,列出伦敦的县的最高支付价格的查询正在流式传输 217 万行。当我们直接使用一个为此查询优化的第二个表时,只有 8.192 万行从磁盘流入。
差异的原因是目前上面提到的 optimize_read_in_order 优化不支持投影。
为了查看 ClickHouse 是否自动使用了上面两个查询的两个投影,我们检查 system.query_log 表(请参见下面的投影列):
SELECT tables, query, query_duration_ms::String || ' ms' AS query_duration, formatReadableQuantity(read_rows) AS read_rows, projections FROM clusterAllReplicas(default, system.query_log) WHERE (type = 'QueryFinish') AND (tables = ['default.uk_price_paid_with_projections']) ORDER BY initial_query_start_time DESC LIMIT 2 FORMAT Vertical Row 1: ────── tables: ['default.uk_price_paid_with_projections'] query: SELECT county, avg(price) FROM uk_price_paid GROUP BY county ORDER BY avg(price) DESC LIMIT 3 query_duration: 6 ms read_rows: 597.00 projections: ['default.uk_price_paid.prj_gby_county'] Row 2: ────── tables: ['default.uk_price_paid_with_projections'] query: SELECT county, price FROM uk_price_paid WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 query_duration: 25 ms read_rows: 2.17 million projections: ['default.prj_oby_town_price']
增加查询处理并行性
大多数分析查询都有一个过滤器、聚合器和排序阶段。每个阶段都可以独立并行化,并且默认情况下将使用与 CPU 核心数相同数量的线程,从而充分利用查询的所有机器资源(因此,在 ClickHouse 中,扩大规模优于扩展)。
发送到 ClickHouse 的查询会转换为一个称为查询管道的物理查询计划,该管道由在从磁盘流入的数据上执行的查询处理阶段组成。
如第一段所述,为了执行查询,ClickHouse 首先使用主索引来选择可能包含与查询的 WHERE 子句匹配的行的块。
选定的行块被分成 n 个单独的数据范围。
n 取决于 max_threads 设置,该设置默认设置为 ClickHouse 在运行的机器上看到的 CPU 核心数。
同时,每个数据范围的一个线程将以块方式流式传输从其范围读取的行。大多数查询处理阶段都以流式方式由 n 个线程并行执行。
我们以具有 4 个 CPU 核心的 ClickHouse 节点为例进行可视化:

通过增加查询的 max_threads 设置,可以增加数据处理的并行性。
我们可以通过 EXPLAIN 来检查查询的查询管道:
EXPLAIN PIPELINE SELECT county, price FROM uk_price_paid WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 ┌─explain─────────────────────────────────┐ │ (Expression) │ │ ExpressionTransform │ │ (Limit) │ │ Limit │ │ (Sorting) │ │ MergingSortedTransform 4 → 1 │ │ MergeSortingTransform × 4 │ │ LimitsCheckingTransform × 4 │ │ PartialSortingTransform × 4 │ │ (Expression) │ │ ExpressionTransform × 4 │ │ (ReadFromMergeTree) │ │ MergeTreeThread × 4 0 → 1 │ └─────────────────────────────────────────┘
计划可以从底向上阅读,我们可以看到有 4 个并行线程用于从磁盘读取/流式传输选定的行块,并且查询管道中的大多数查询处理阶段都由 4 个线程并行执行。
4 个线程,因为 EXPLAIN 查询在一个具有 4 个 CPU 核心的 ClickHouse 节点上运行,因此 max_threads 默认设置为 4:
SELECT * FROM system.settings WHERE name = 'max_threads' FORMAT Vertical Row 1: ────── name: max_threads value: 4 changed: 0 description: The maximum number of threads to execute the request. By default, it is determined automatically. min: ᴺᵁᴸᴸ max: ᴺᵁᴸᴸ readonly: 0 type: MaxThreads 1 row in set. Elapsed: 0.009 sec.
我们再次检查相同查询的查询管道,该查询现在具有增加 max_threads 设置为 20 的 SETTINGS 子句:
EXPLAIN PIPELINE SELECT county, price FROM uk_price_paid WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 SETTINGS max_threads = 20 ┌─explain──────────────────────────────────┐ │ (Expression) │ │ ExpressionTransform │ │ (Limit) │ │ Limit │ │ (Sorting) │ │ MergingSortedTransform 20 → 1 │ │ MergeSortingTransform × 20 │ │ LimitsCheckingTransform × 20 │ │ PartialSortingTransform × 20 │ │ (Expression) │ │ ExpressionTransform × 20 │ │ (ReadFromMergeTree) │ │ MergeTreeThread × 20 0 → 1 │ └──────────────────────────────────────────┘
现在有 20 个并行线程用于从磁盘读取/流式传输选定的行块,并且查询管道中的大多数查询处理阶段都由 20 个线程并行执行。
我们使用 4 个线程运行查询(ClickHouse 玩场的默认 max_threads 设置):
SELECT county, price FROM uk_price_paid WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 ┌─county─────────┬─────price─┐ │ GREATER LONDON │ 594300000 │ │ GREATER LONDON │ 569200000 │ │ GREATER LONDON │ 448500000 │ └────────────────┴───────────┘ 3 rows in set. Elapsed: 0.070 sec. Processed 27.64 million rows, 40.53 MB (393.86 million rows/s., 577.50 MB/s.)
我们使用 20 个线程运行查询:
SELECT county, price FROM uk_price_paid WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 SETTINGS max_threads = 20 ┌─county─────────┬─────price─┐ │ GREATER LONDON │ 594300000 │ │ GREATER LONDON │ 569200000 │ │ GREATER LONDON │ 448500000 │ └────────────────┴───────────┘ 3 rows in set. Elapsed: 0.036 sec. Processed 27.64 million rows, 40.00 MB (765.42 million rows/s., 1.11 GB/s.)
使用 20 个线程,查询速度大约加快了一倍,但请注意,这会增加查询执行消耗的峰值内存量,因为会有更多的数据并行流入 ClickHouse。
我们通过检查 system.query_log 表来检查两个查询运行的内存消耗:
SELECT query, query_duration_ms::String || ' ms' as query_duration, formatReadableSize(memory_usage) as memory_usage, formatReadableQuantity(read_rows) AS read_rows, formatReadableSize(read_bytes) as read_data FROM clusterAllReplicas(default, system.query_log) WHERE type = 'QueryFinish' AND tables = ['default.uk_price_paid'] ORDER BY initial_query_start_time DESC LIMIT 2 FORMAT Vertical Row 1: ────── query: SELECT county, price FROM uk_price_paid WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 SETTINGS max_threads = 20 query_duration: 35 ms memory_usage: 49.49 MiB read_rows: 27.64 million read_data: 38.15 MiB Row 2: ────── query: SELECT county, price FROM uk_price_paid WHERE town = 'LONDON' ORDER BY price DESC LIMIT 3 query_duration: 69 ms memory_usage: 31.01 MiB read_rows: 27.64 million read_data: 38.65 MiB 2 rows in set. Elapsed: 0.026 sec. Processed 64.00 thousand rows, 5.98 MB (2.46 million rows/s., 230.17 MB/s.)
使用 20 个线程,查询消耗的峰值主内存约增加了 40%,而使用 4 个线程的相同查询运行。
请注意,对于高 max_threads 设置,资源争用和上下文切换可能会成为瓶颈,因此增加 max_threads 设置不会线性扩展。
总结
加快 ClickHouse 查询的 3 个思路:
- 设置恰当的主键,减少需要读取的数据量。
- 通过 MV 和 projection 预处理数据。
- 通过增加并发来提升数据处理的速度。
定位和跟踪SQL执行方式的手段:
- EXPLAIN indexes =1 actions = 1 查看索引使用情况和具体 stage。
- EXPLAIN PIPELINE 来查看并发度。
- 开启跟踪日志来查看每个步骤执行的真实时间:set send_logs_level = 'trace'。
附
SQL 执行原理

首先通过解析 query 文本生成抽象语法树 AST(abstract syntax tree)。然后重写 AST 得到优化和规范化后的 query 版本。然后生成查询计划和生成queryPipeLine,最后执行具体的 queryPipeLine。每一个步骤,都对应着一个 EXPLAIN 命令。



