免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector

即行人重识别中经常用来提升检索MAP与CMC指标的经典re-ranking方法。
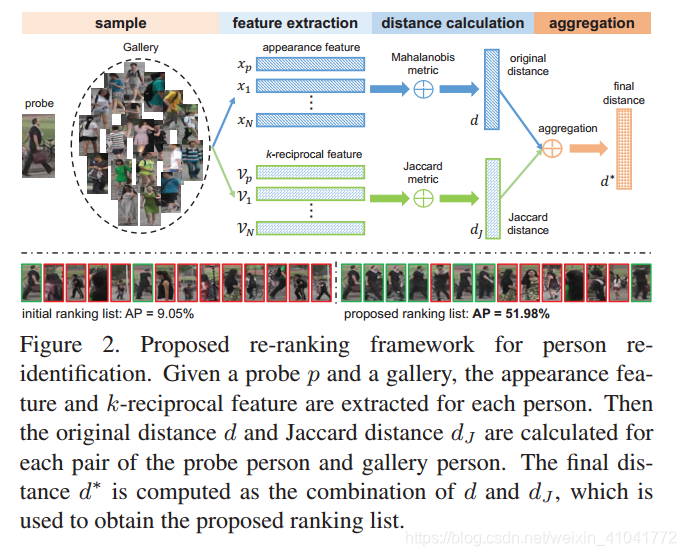
下图为重排序架构图:
Abstract
行人重识别作为图像检索的子问题, 重排序能够在后期很大程度上提高检索准确率。本文的假设是如果检索库中的图像与检索图像特征很相似,并且在检索图像的K-倒排最近邻集合中,其有很大的概率是真实的匹配。具体就是给定义检索图像,先将其K-倒排最近邻匹配图像集合编码成一个基于全局的称为K-倒排特征的N维向量,然后使用检索图像的K-倒排特征与其最近邻基于杰卡德距离进行距离矩阵重拍序。本文的方法是自动执行的方法,无需人工介入。
Introduction
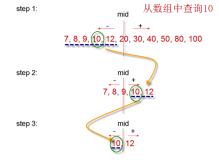
重排序通常应用在通用实例检索应用中,其优势就是无需额外的训练样本,直接对模型的检索排序结果进行优化重排。而且重排序的效率依赖于有高准确率的初始排序。传统的重排序认为原始排序的top-k结果具有很好的匹配程度,并利用其关系进行结果重排 。然而如下图所示,真实的匹配P1, P2, P3 与P4没有全部在top-4中,而假匹配N1-N6具有较高的排序分数,所以直接使用top-k图像会给重排系统引进噪声并会使重排结果打折扣。
K-倒排最近邻方法,可以解决诸如假匹配图像对Top-K匹配的不利影响。

如果两图像被称为K-倒排最近邻,那么无论两者谁做为检索图像另一张都是Top-K结果,即两者互相检索都是排名靠前的。从图中可以看出,检索图像是真实匹配的K-倒排最近邻,而不是假匹配的K-倒排最近邻,此方法可以识别出真实的最近邻匹配,从而提高重排序结果。
本文的方法有3步:(本部分可能概念抽象)
1、将加权的K-倒排邻居集合编码成向量来组成K-倒排特征,然后通过K-倒排特征计算两张图像间的用杰卡德距离;
2、为了获取更加鲁棒的K-倒排特征,本文提出了一种局部检索扩展方法来提高整体检索性能。
3、最后的度量距离就是原始的距离与杰卡德距离的加权和,然后用于重排序列表生成。
本文方法
1、问题定义 :
给定一张检索图像p与N张检索库图像,检索图像与与任意库图像之间的原始距离可以用马氏距离表示。本文的重排序主要就是对初始排序列表进行优化重排,使得更多的真实匹配在列表的Top-k中。
2、K-倒排最近邻居 :

本文定义N(p,k)为检索图p最近邻居(原始排序列表中的Top-K样本),K倒排最近邻公式定义如下:

上式描述了检索图像的K-倒排最近邻就是其K最近邻图像中能够满足互搜都是K-最近邻的要求的图像集合。
但是由于现实中,光线,视角,姿态以及遮挡变化的存在,使得正样本匹配可能,么有包含在K-最近邻中,也就使得无法包含在K-倒排最近邻中。为了解决这一问题,本文将检索图像的K倒排最近邻中每一候选图像的1/2k倒排最近邻加入检索倒排集合中形成一更加鲁棒的K倒排最近邻集合。
公式条件如下:候选图像的K倒排最近邻与检索图像的K倒排最近邻要有2/3的交集,通过此操作可以将更多的相似于候选图像的正样本加入检索图像的K-倒排最近邻中。
本部分需要知道每一个候选图像也都要计算其各自的K倒排最近邻。(应该是先根据马氏距离计算出N个被检索图像的K最近邻,其复杂度为N*N然后根据K最近邻分别计算出所有N张图像的K倒排最近邻,用于后续使用。)

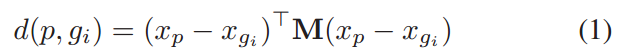
下图展示了具体的匹配扩展过程。开始时,难正样本G没包含在R(Q,20)中而被忽略,但是G包含在RC(C,10)中,通过上述公式操作,可以将G召唤回来。
此外,本文没有将得到的R*(p,k)直接作为最后的Top排序结果,而是考虑将其作为上下文知识来重新计算检索图像与库图像的距离。

3、杰卡德距离
本文部分主要介绍如何通过两图像的K倒排最近邻集合来重新计算图像对之间的距离。原理就是如果 两图像的K倒排近邻集合具有较好的重叠,那么两个集合就很相似,图像距离就越近。两个集合的杰卡德距离度量公式如下:

此距离就是先使用两集合的交并比计算杰卡德系数,然后用1减去即是距离,越大越好。
尽管上式可以获取两图像的相似关系,但仍存在较多的不足。
1、由于需要计算所有图像对的集合交并比,并且每个R*(p,k)与R*(gi,k)交并比需要大量的耗时(主要就是两个集合中相同图像的检索,作者采用N维向量进行热点编码结合中存在的图像。),一种方法就是讲近邻集合编码成简单的等价向量,可以很大程度减少计算复杂度。
2、距离计算过程将所有邻居平等看待,使得判别性不够好,事实上,与检索图像越近的候选就越可能是真实的匹配,所以可以通过原始距离重新计算它们的权重。
3、如果单纯地使用上下文信息作为距离度量就会存在一些限制,因此作者考虑使用原始距离与杰卡德距离的组合作为最终的距离度量。
上述3个问题的解决方法:
针对前两个问题,将检索图像的K倒排最近邻集合编码成N维向量Vp=[Vp,g1 Vp,g2 ... Vp,gn]。Vp,gi定义如下:

这样,N维向量的每一维表示相应的图像是与否是检索图像的K倒排最近邻(即属于R*(p,k)) ,然而此方法仍没有解决等价对待所有候选图像的问题,下面公式引入了不同候选图像的权重,表示其与检索的相似程度。

基于上述定义,交并集中的候选图像数量可以用下式表示。

其中的最大最小操作是对Vp与Vgi两个N维特征向量进行对应元素的操作。交集通过最小操作将两个特征向量对应维度上的最小的那个值作为两者共同包含gi的程度。并集的最大操作就是为了统计两个集合中的匹配候选的总集合。
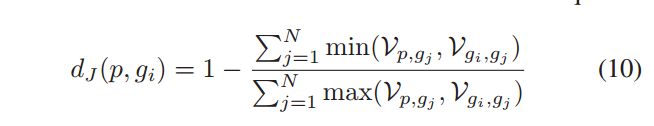
4、局部检索扩展
本部分主要是通过检索图像的最近邻对检索图像的K倒排最近邻特征向量进行扩展,其扩展公式如下,就是取其最近邻候选的特征向量的均值。文中将此方法应用到了检索p与所有gi上,并且考虑到噪声的存在,对最近邻的个数进行了限制。此处的N(p,k)中的k用k2表示,R*(gi,k)中的k用k1表示,k2<k1。文中采用k2=6,k1=20

5、度量距离
本文主要通过结合杰卡德距离与原始的马氏距离对原始的排序列表进行重新修正,其距离为两者的加权和,加权参数主要用来权衡两个距离的重要程度,文中采用了λ等于0.3。

免费体验阿里云高性能向量检索服务:https://www.aliyun.com/product/ai/dashvector