


引言
快速排序作为交换排序的一种,在排序界的影响力毋庸置疑,我们C语言中用的qsort,C++中用的sort,底层的排序方式都是快速排序。相比于同为交换排序的冒泡,其效率和性能就要差的多了,本篇博客就是要重点介绍快速排序的实现,以及其代码和效率的优化。

话不多说,开始我们今天的内容。
快速排序的基本逻辑
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,使左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
用通俗的语言讲:
- 从一组元素序列中(称这个序列为A0)随机取出一个数,我们可以称这个数为k
- 将比k元素小的数放在k的左边,比k元素大的数放在k的右边
- 此时分别将K左右两边边的元素,拿出来各成一个序列(称为A1和A2)
- 同样用处理A的方式处理A1,A2序列
最后,序列中所有左边的数都会比右边的小,完成快速排序。
可以先来处理第一步和第二步,也就是快速排序的第一层排序。
快速排序的第一层
这里有一张gif动图,大家可以先预热一下,如果看懂了,可以跳过一部分的讲解。
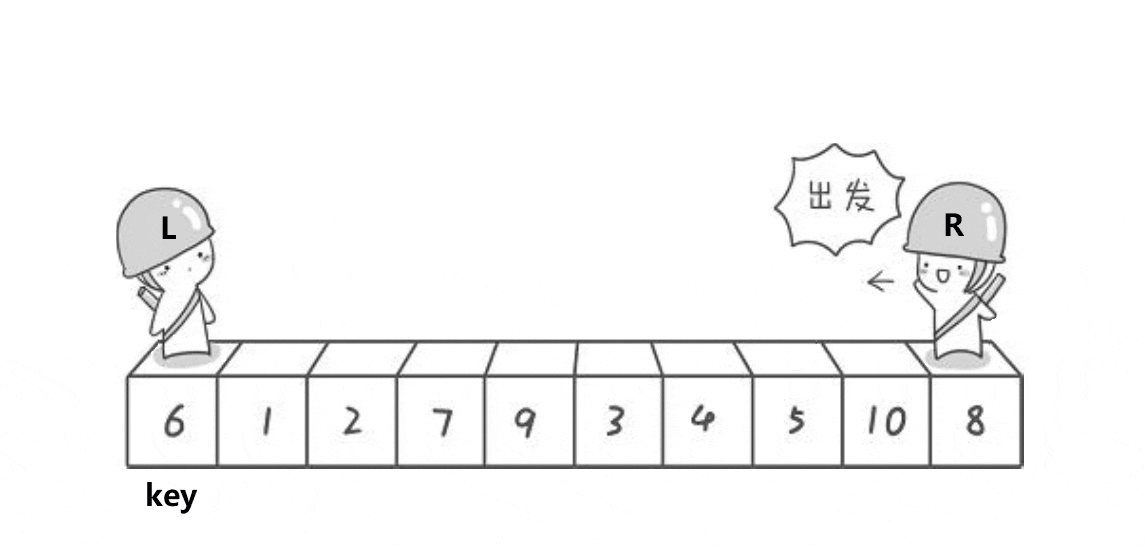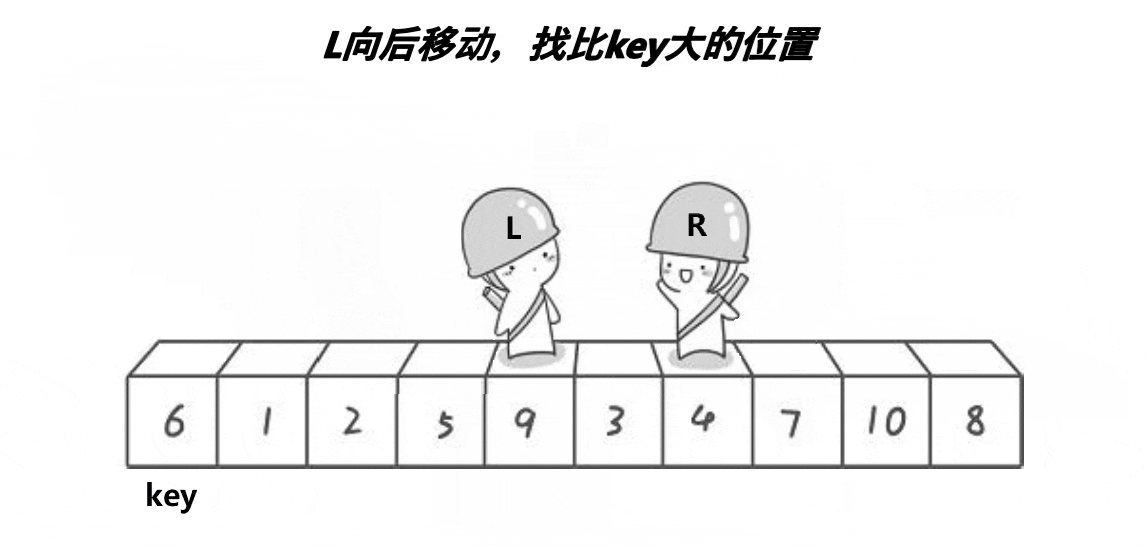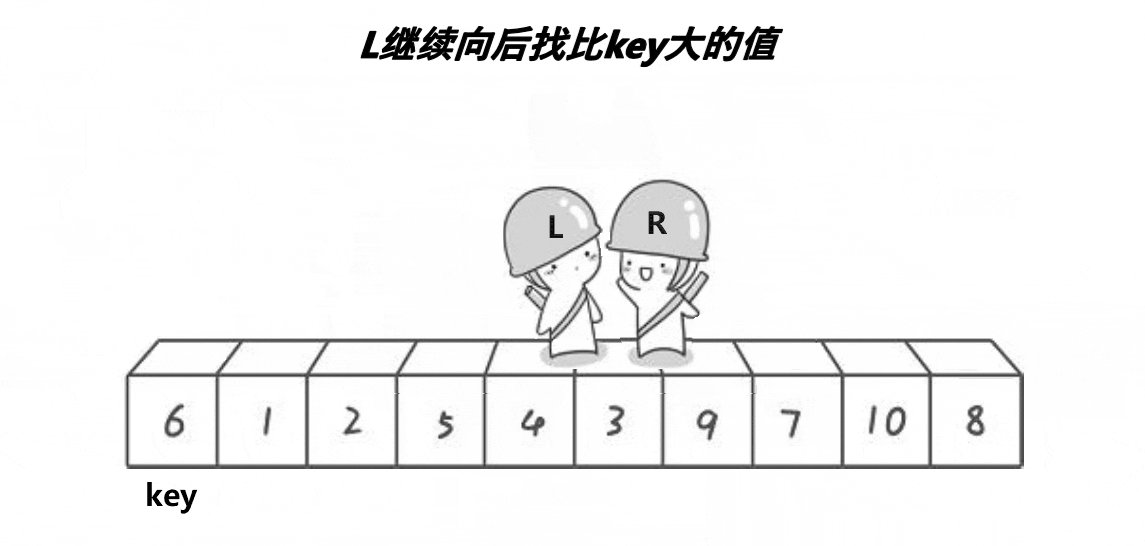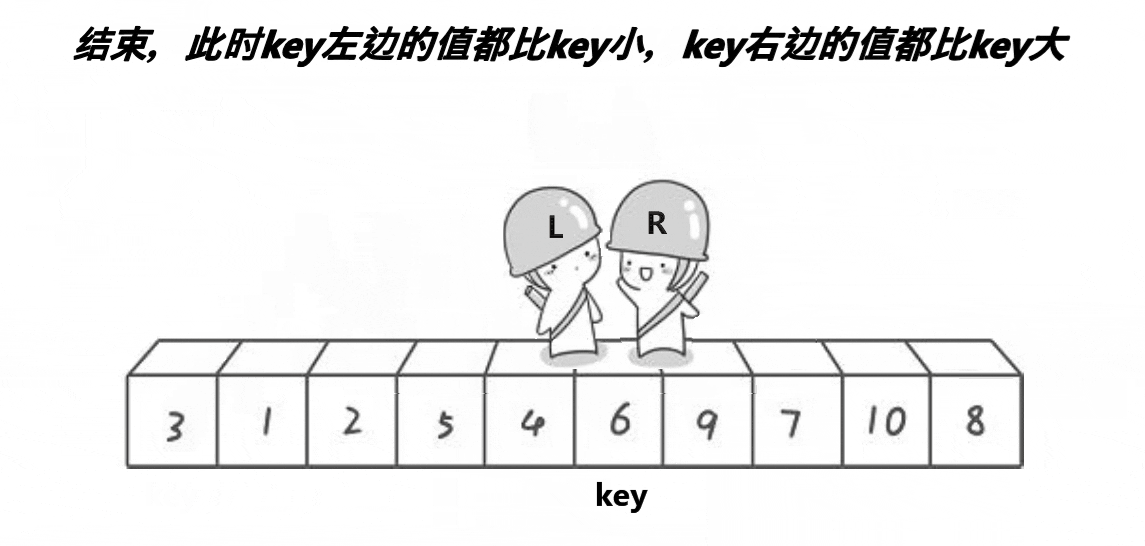
第一步,取第一个元素(下标为key)为基准值,我们的目的是使基准值左边的数都比基准值小,基准值右边的数都比基准值大。
第二步,定义两个下标变量,一个变量从右往左走(R),一个变量左往右走(L)。首先从R开始往左走(走的时候左边的L保持不动),每走一步都与基准值相比较。
让 R 停下来的条件有两个:① R 位置的值比基准值小。 ② R 与 L 相遇。
第三步,如果让R停下来的条件为①,则L开始往右一步步走,每走一步也都与基准值比较。
让 L 停下来的条件也有两个:① L 位置的值比基准值大。 ② R 与 L 相遇。
第四步,如果让 L 停下来的条件为①,则交换 L 和 R 两位置所存的值,回到第二步, R 开始往左移动,重复此过程,直到 L 和 R 相遇。
在整个四步过程中,一旦出现 R 和 L 相遇,则第一层数据遍历结束,交换 L 和基准值key存的值并进入下一层的排序。
注:在第二步的时候要统一由 R 先开始移动,这样可以保证在L和R相遇时一定会是比key小的数。这是因为R先移动,在找到比基准值小的数前是不会停止的;而L移动的前提条件是R找到了比基准值小的数(这一特性使R静止的位置一定会是比基准值key小的数)。
故:L和R静止一方的值必定比基准值key小。
关于L和R相遇时一定会是比key小的数这个问题如果还没搞懂,可以拿张纸来画一画。
上面就是一层快速排序的全过程,在这一层排序过后,可以找到一个基准值的真正位置,也让基准值左边的数都小,右边的数都大。
接下来是这一层排序的代码实现:
void Swap(int* x, int* y) { int tmp = *x; *x = *y; *y = tmp; } int left = 0, right = n - 1; int keyi = 0; while (left < right) { while (right > left && a[right] >= a[keyi]) { right--; } while (right > left && a[left] <= a[keyi]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[keyi], &a[left]);
递归版快速排序的实现
Hoare版快速排序
写完了第一层之后,其他的工作就轻松多了,就是运用递归,每层递归时,需要调整left和right的值。这个过程和二叉树的前序遍历非常相似,以下就是完整的hoare版的快速排序:
void Swap(int* x, int* y) { int tmp = *x; *x = *y; *y = tmp; } void QuickSort1(int* a, int left, int right) { //当left>=right时递归结束 if (left >= right)return; int begin = left, end = right; int keyi = left; while (left < right) { while (right > left && a[right] >= a[keyi]) { right--; } while (right > left && a[left] <= a[keyi]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[keyi], &a[left]); QuickSort1(a, begin, left - 1); QuickSort1(a, left + 1, end); }
在递归的过程中,递归的第一个区间是:[begin , left - 1(left - 1即相遇的前一个位置) ],递归的第二个区间:[left + 1(left + 1即相遇的后一个位置) , end]

在快速排序的递归实现中,除了发明快速排序的大佬hoare的原版排序方式。还有两种方式,虽然底层原理都是一样的,但这两种方式也有各自的特点。
挖坑法快速排序
什么是挖坑法,顾名思义,就是挖一个坑。在理解了hoare版本快速排序的基础上理解这个方式并不困难,下面来看看挖坑法的gif格式动图:
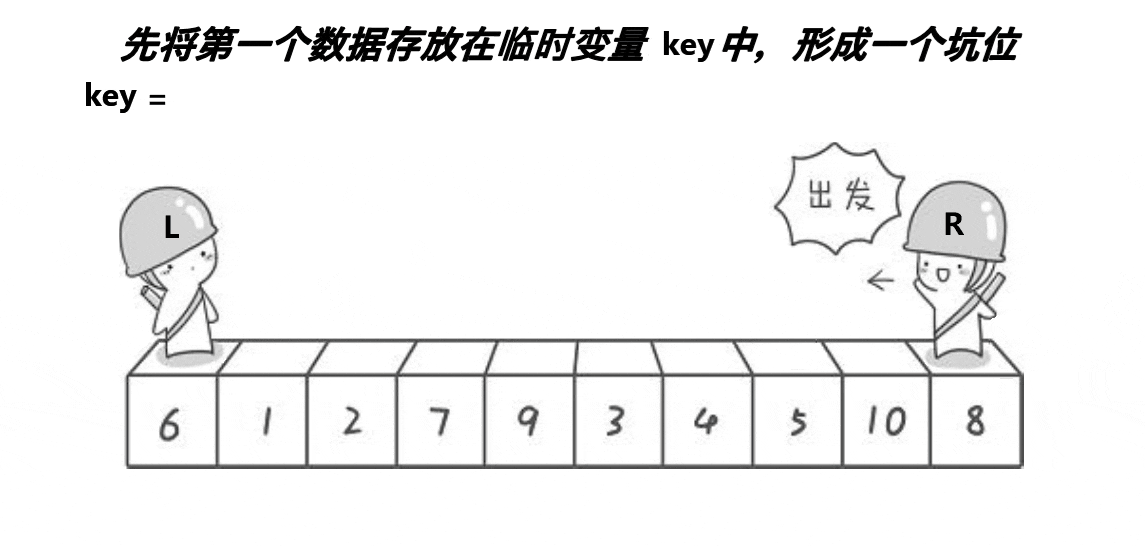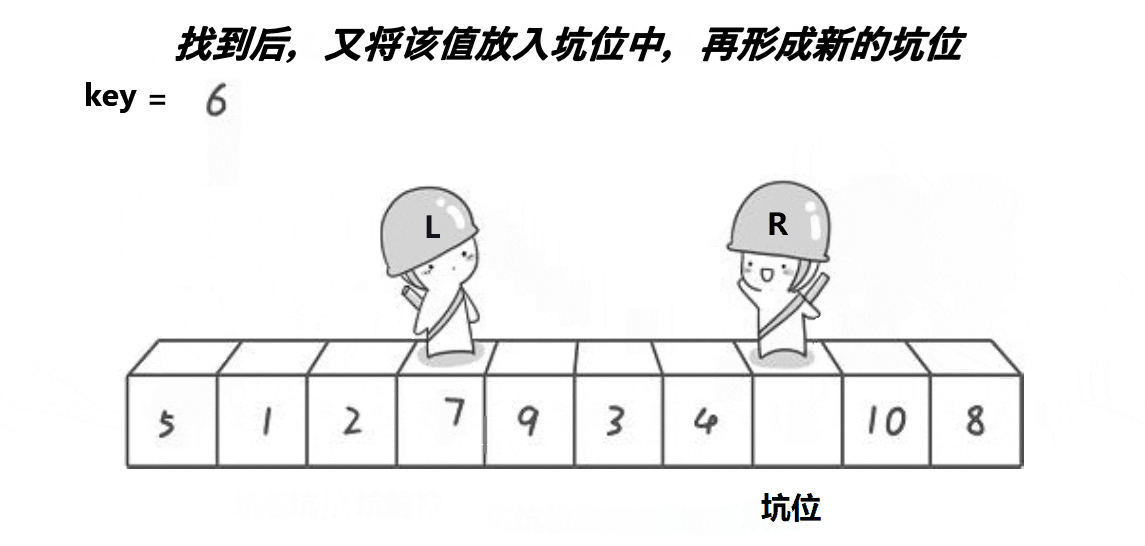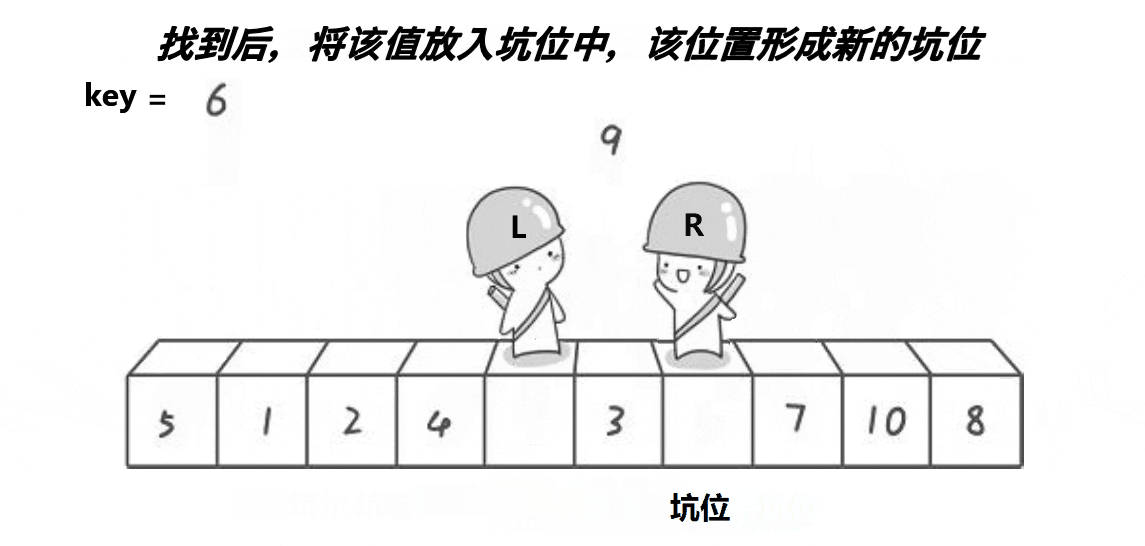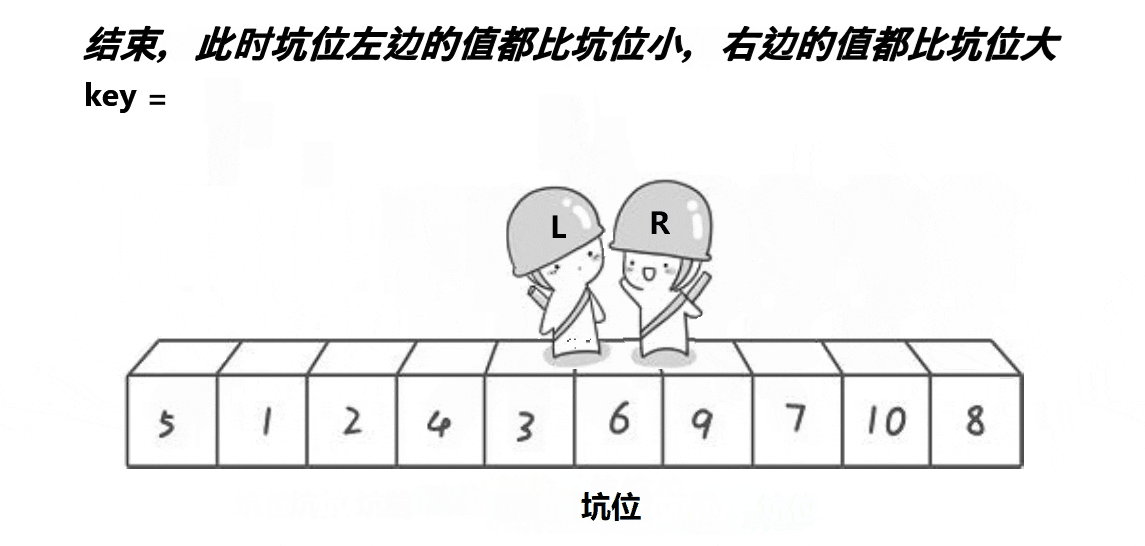
第一步,将基准值挖出存在key中,基准值位置下标用一个变量hole位记录(相当于一个坑位)
第二步,首先从R开始往左走(走的时候左边的L保持不动),每走一步都与基准值相比较。
让 R 停下来的条件有两个:① R 位置的值比基准值小。 ② R 与 L 相遇。
第三步,如果使R停下来的条件为①,则将R下标位置的值放入坑位hole中,同时将R下标赋给hole,这时候坑位变成R的位置。
第四步,如果让R停下来的条件为①,则L开始往右一步步走,每走一步也都与基准值比较。
让 L 停下来的条件也有两个:① L 位置的值比基准值大。 ② R 与 L 相遇。
第五步,如果使L停下来的条件为①,则将L下标的值放入hole中,同时将L下标赋给hole,这时候坑位变成L的位置。
这里遍历停止的标志也同样是L和R相遇,相遇的位置也是一个坑位,直接把key的值放到坑位中,第一层整个数据处理就结束了。
下面是挖坑法的实现代码:
void Swap(int* x, int* y) { int tmp = *x; *x = *y; *y = tmp; } void QuickSort2(int* a, int left, int right) { if (left >= right)return; int begin = left, end = right; int valk = a[left]; int holei = left; while (left < right) { while (right > left && a[right] >= valk) { right--; } a[holei] = a[right]; holei = right; while (right > left && a[left] <= valk) { left++; } a[holei] = a[left]; holei = left; } a[holei] = valk; QuickSort2(a, begin, left - 1); QuickSort2(a, left + 1, end); }
挖坑法的优势在于好理解,就是保持一个坑位,不断往里面填数字然后变换坑位的过程。
前后指针版快速排序
前后指针版本的快速排序不好理解,但是代码量出奇的少,先看一下gif动图了解大致思路:

规则很简单:
- cur >= key ,++cur
- cur < key ,++prev ,交换prev和cur的值
- 结束条件:cur > end
- 结束后,交换prev和key的值
在整个过程中,prev的位置之前的数据都小于基准值key,而prev和cur之间的值都保证大于基准值key,在prev和cur的值交换的过程中,相当于把大的数字往后甩,把cur找到的小的值往前插入。在cur遍历到最后,比基准值小的数字也就成功都插入到了前面,而比基准值大的数字也都被甩到了后面。这时交换prev和key的值也就达到了快速排序第一层遍历后的效果。
下面是前后针法的实现代码:
void Swap(int* x, int* y) { int tmp = *x; *x = *y; *y = tmp; } void QuickSort3(int* a, int left, int right) { if (right <= left)return; int pcur = left + 1, prev = left, keyi = left; while (pcur <= right) { if (a[pcur] < a[keyi] && ++prev != pcur) Swap(&a[pcur], &a[prev]); ++pcur; } Swap(&a[keyi], &a[prev]); QuickSort3(a, left, prev - 1); QuickSort3(a, prev + 1, right); }
建议大家可以把前后指针法的实现理解后背下来,后期Hr面试问的时候搓起来会很爽。
避免最坏时间复杂度的两种解决方案
快速排序排起来是很快,但我们上面所写的快排真的就没有缺陷吗?
现在你可以试想一种场景,如果用上面所写的代码去排一个有序数组会如何。

这时候的复杂度将会是一场灾难。基准值如果每次都是数组的第一个值,那么这种情况就很有可能会出现。对于这种由于顺序引起的最坏时间复杂度问题,这里提供两种解决方案。
1.随机选key
既然害怕数组顺序无法选出随机数,那么让选的基准值下标值为随机取的不就能解决问题了吗?就是我们所说的随机选key。
这里随机数需要用到rand()函数,头文件<stdlib.h>
int randi = rand(); randi %= (right - left + 1); randi += left; Swap(&a[randi], &a[left]);
以上就是随机key的取法,(right - left + 1) 是为了控制范围防止越界对随机数做的一个处理。
把这种处理方式放入快排代码中就是这个样子,以Hoare版为例:
void Swap(int* x, int* y) { int tmp = *x; *x = *y; *y = tmp; } void QuickSort1(int* a, int left, int right) { //当left>=right时递归结束 if (left >= right)return; int begin = left, end = right; int keyi = left; //取随机key部分 int randi = rand(); randi %= (right - left + 1); randi += left; Swap(&a[randi], &a[left]); //----------- while (left < right) { while (right > left && a[right] >= a[keyi]) { right--; } while (right > left && a[left] <= a[keyi]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[keyi], &a[left]); QuickSort1(a, begin, left - 1); QuickSort1(a, left + 1, end); }
2.三数取中
具体思路是,找三个下标left,right ,mid对应的数,取三个数中处于中间位置的作为key(基准值),其中 mid = (left + right) / 2 。
这里我们专们写一个三数取中的函数,这一过程相对比较复杂:
//三数取中函数 int GetMid(int* a, int left, int right) { int mid = (left + right) / 2; if (a[left] < a[mid]) { if (a[mid] < a[right]) return mid; else if (a[left] > a[right]) return left; else return right; } else { if (a[mid] > a[right]) return mid; else if (a[left] > a[right]) return left; else return right; } }
与上述随机取key时放置的位置一样
void Swap(int* x, int* y) { int tmp = *x; *x = *y; *y = tmp; } void QuickSort1(int* a, int left, int right) { //当left>=right时递归结束 if (left >= right)return; int begin = left, end = right; int keyi = left; //三数取中部分 int midi = GetMid(a, left, right); Swap(&a[midi], &a[left]); //----------- while (left < right) { while (right > left && a[right] >= a[keyi]) { right--; } while (right > left && a[left] <= a[keyi]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[keyi], &a[left]); QuickSort1(a, begin, left - 1); QuickSort1(a, left + 1, end); }
到这里,避免最坏时间复杂度的两种方案就介绍完了。
小区间优化
什么是小区间优化?
你是否考虑过这样一个问题,当快排递归到最后几层时,会产生多少小区间。

这里出现了一个很明显的问题:待排序的数很少,但是走递归的消耗较大,最后几层的递归占整个递归的80%~90%。
这里给出的小区间优化方式就是,当递归进入待排序数字只剩10个左右的时候,使用直接插入排序的方式对小区间进行排序。
//小区间优化方式 if(right - left + 1 < 10) { //插入排序,减少90%的递归 InsertSort(a + left, right - left + 1); }
放到hoare版快排中就是这样的,可以省去if判断return。
void Swap(int* x, int* y) { int tmp = *x; *x = *y; *y = tmp; } void QuickSort1(int* a, int left, int right) { //小区间优化方式 if(right - left + 1 < 10) { //插入排序,减少90%的递归 InsertSort(a + left, right - left + 1); } //------------- int begin = left, end = right; int keyi = left; while (left < right) { while (right > left && a[right] >= a[keyi]) { right--; } while (right > left && a[left] <= a[keyi]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[keyi], &a[left]); QuickSort1(a, begin, left - 1); QuickSort1(a, left + 1, end); }
此方式优化了大部分的递归,但得益于计算机对递归的处理,这种优化和原版的效率比起来就没有那么明显了。
快速排序的非递归实现
讲了这么多,总算是到了咱们的最后一个问题,快速排序非递归的实现。既然不让递归,咱们可以换个思路,用栈模拟个递归不就行了。在栈中存放左右区间,可以和递归达到同一个效果。
你问我栈是什么?emm,我之前写了一遍关于栈的博客,供参考:
取区间的方式:

先插入总区间,进入一个大循环中,循环结束的条件为栈为空,每次取栈顶弹栈,处理区间后再次往栈中插入被分割出来的有效区间,继续循环。
主体思路就是用栈模拟一个递归的过程,栈本来应该是构建一个结构体存左右区间,不过这里我就直默认顺序接插入右区间和左区间,取的时候依次就是是左区间和右区间,不再麻烦造个结构体了。
以下是非递归实现快速排序,复用上次栈的代码:
typedef int STDataType; typedef struct stack { STDataType* a; int top; int capacity; }ST; void STInit(ST* ps) { assert(ps); ps->a = NULL; ps->top = ps->capacity = 0; } void STDestory(ST* ps) { assert(ps); free(ps->a); ps->a = NULL; ps->top = ps->capacity = 0; } void STPush(ST* ps, STDataType x) { assert(ps); if (ps->top == ps->capacity) { int newcapacity = ps->capacity == 0 ? 4 : 2 * ps->capacity; STDataType* tmp = (STDataType*)realloc(ps->a, newcapacity * sizeof(STDataType)); if (tmp == NULL) { perror("realloc tmp fail:"); exit(1); } ps->a = tmp; ps->capacity = newcapacity; } ps->a[ps->top] = x; ++ps->top; } bool STEmpty(ST* ps) { assert(ps); return ps->top == 0; } void STPop(ST* ps) { assert(ps); assert(!STEmpty(ps)); ps->top--; } STDataType STTop(ST* ps) { assert(ps); assert(!STEmpty(ps)); return ps->a[ps->top - 1]; } int STSize(ST* ps) { assert(ps); return ps->top; } // 快速排序 非递归实现 void QuickSortNonR(int* a, int left, int right) { ST st; STInit(&st); STPush(&st, right); STPush(&st, left); while (!STEmpty(&st)) { int begin = STTop(&st); STPop(&st); int end = STTop(&st); STPop(&st); if (begin >= end)continue; int keyi = begin, prev = begin, pcur = begin + 1; while (pcur <= end) { if (a[pcur] < a[keyi] && ++prev != pcur)Swap(&a[prev], &a[pcur]); ++pcur; } Swap(&a[prev], &a[keyi]); STPush(&st, prev - 1); STPush(&st, begin); STPush(&st, end); STPush(&st, prev + 1); } }
结语
以上就是快速排序的所有内容,本篇博客关于快排的内容,讲到了Hoare原版快速排序,挖坑法和双指针法,避免快排最坏时间复杂度的两种解决方案,小区间优化,非递归的快排等内容,希望能帮助大家快速理解和学会快速排序。
感谢大家的支持!


