摘要
本 PEP 引进了一个新的内置函数 enumerate() 来简化常用的循环写法。它为所有的可迭代对象赋能,作用就像字典的 iteritems() 那样——一种紧凑、可读、可靠的索引表示法。
基本原理
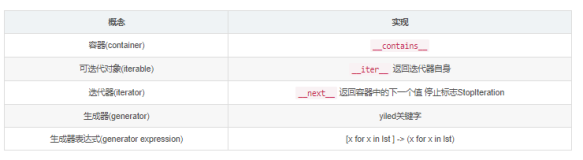
Python 2.2 在 PEP 234[3] 中提出了可迭代对象接口的概念。iter() 工厂函数作为一种通用的调用约定而被提出,深入修改了迭代器的使用方式,作为整个 Python 的统一规范。这种统一的规范就是为映射类型、序列类型和文件对象建立一个通用的可迭代对象接口。
PEP 255[1] 中提出的生成器是作为一种更容易创建迭代器的方法引入的,特别是具有复杂的内部执行过程或变量状态的迭代器。有了生成器以后,PEP 212[2] 中关于循环的计数器的想法就有可能改进了。
那些想法是提供一种干净的迭代语法,带有索引和值,但不适用于所有的可迭代对象。而且,那种方法没有生成器提供的内存友好的优点(生成器不会一次性计算整个序列)。
(Python猫注:关于生成器的 PEP 也有翻译,请查看 PEP-255、PEP-342、PEP-380)
新的提议是添加一个内置函数 enumerate(),在有了迭代器和生成器以后,它就可以实现。它为所有的可迭代对象赋能,作用就像字典的 iteritems() 那样——一种紧凑、可读、可靠的索引表示法。像 zip() 一样,它有望成为一种常用的循环习语(idiom)。
(Python猫注:zip() 函数非常强,推荐阅读《一篇文章掌握 Python 内置 zip() 的全部内容》)
这一提议的目的是利用现有的实现,再加一点点的努力来整合。它是向后兼容的,不需要新的关键字。本提案将合入 Python 2.3,不需要从 __future__ 中导入。
新内置函数的规范
def enumerate(collection): 'Generates an indexed series: (0,coll[0]), (1,coll[1]) ...' i = 0 it = iter(collection) while 1: yield (i, it.next()) i += 1
注A :PEP 212 循环计数器迭代[2]讨论了几个实现索引的提议。有些提议只适用于列表,不像上面的函数适用于任意生成器、xrange、序列或可迭代对象。
另外,那些提议是在 Python 2.2 之前提出并评估的,但是 Python 2.2 没有包含生成器。因此,PEP 212 中的非生成器版本有一个缺点,即会用一个巨大的元组列表,导致消耗太多内存。
这里提供的生成器版本快速且轻便,适用于所有可迭代对象,并允许用户在不浪费计算量的情况下中途放弃。
还有一些涉及相关问题的 PEP:整型迭代器、整型 for 循环,以及一个修改 range 和 xrange 的参数的 PEP。enumerate() 提案并不排斥其它提案,即使那些提案被采纳,它仍然满足一个重要的需求——对任意可迭代对象中的元素进行计数的需求。
其它的提案给出了一种产生索引的方法,但没有相应的值。如果给定的序列不支持随机访问,比如文件对象、生成器或用__getitem__定义的序列,这就特别成问题。
注B :几乎所有的 PEP 审阅人都欢迎这个函数,但对于“是否应该把它作为内置函数”
存在分歧。一方提议使用独立的模块,主要理由是减缓语言膨胀的速度。
另一方提议使用内置函数,主要理由是该函数符合 Python 核心编程风格,适用于任何具有可迭代接口的对象。正如 zip() 解决了在多个序列上循环的问题,enumerate() 函数解决了循环计数器的问题。
如果只允许加一个内置函数,那么 enumerate() 就是最重要的通用工具,可以解决最广泛的问题,同时提高程序的简洁性、清晰度和可靠性。
注C :讨论了多种备选名称:
| 函数名 | 分析 |
| iterindexed() | 五个音节太拗口了 |
| index() | 很好的动词,但是可能会跟 .index () 方法混淆 |
| indexed() | 很受欢迎,但是应该避免形容词 |
| indexer() | 在 for 循环中,名词读起来不太好 |
| count() | 直接而明确,但常用于其它语境 |
| itercount() | 直接、明确,但被不止一个人讨厌 |
| iteritems() | 与字典的 key:value 概念冲突 |
| itemize() | 让人困惑,因为 amap.items() != list(itemize(amap)) |
| enum() | 简练;不及enumerate 清楚;与其它语言中的枚举太相似,但有着不同的含义 |
所有涉及“count”的名称还有一个缺点,即隐含着计数是从 1 开始而不是从 0 开始的意思。
所有涉及“index”的名称与数据库语言的用法冲突,数据库的索引表示一种排序操作,但不是线性排序。
注D: 在最初的提案中,这个函数带有可选的 start 和 stop 参数。GvR 指出,函数enumerate(seqn,4,6) 还有一种看似合理的解释,即返回序列的第 4 和第 5 个元素的切片。为了避免歧义,这两个可选参数被摘掉了,尽管这意味着循环计数器失去了部分的灵活性。
在从 1 开始计数的常见用例中,这种可选参数的写法很有用,比如:
for linenum, line in enumerate(source,1): print linenum, line
(Python猫注:这篇文档说 enumerate 没有起止参数,然而,在后续版本中(例如我用的 3.9),它支持使用一个可选的 start 参数!我暂未查到这个变更是在何时加入的,如有知情者,烦请告知我,以便修正!)
GvR 评论道:
filter 和 map 应该 die,被纳入列表推导式,不增加更多的变体。我宁可引进做迭代器运算的内置函数(例如 iterzip,我经常举的例子)。 我认可用某种方法并行地遍历序列及其索引的想法。把它作为一个内置函数,没有问题。 我不喜欢“indexed”这个名字;形容词不是好的函数名。可以用 iterindexed() ?
Ka-Ping Yee 评论道:
我对你的提议也很满意……新增的内置函数(倾向于用“indexed”)是我期盼了很久的东西。
Neil Schemenauer 评论道:
新的内置函数听起来不错。Guido 可能会担心增加太多内置对象。你最好把它们作为某个模块的一部分。如果你用模块的话,那么你可以添加很多有用的函数(Haskell 有很多,我们可以去“偷”)。
Magnus Lie Hetland 评论道:
我认为 indexed 会是一个有用和自然的内置函数。我肯定会经常使用它。 我非常喜欢 indexed();+1。 很高兴它淘汰了 PEP-281。为迭代器添加一个单独的模块似乎是个好主意。
来自社区的反馈:
对于 enumerate() 提案,几乎 100% 赞成。几乎所有人都喜欢这个想法。
作者的注释:
在这些评论之前,共有四种内置函数被提出来。经过评论之后,xmap、xfilter 和 xzip 被撤销了。剩下的一个对 Python 来说是至关重要的。Indexed() 非常容易实现,并且立马就可以写进文档。更重要的是,它在日常编程中很有用,如果不用它,就需要显式地使用生成器。 这个提案最初包含了另一个函数 iterzip()。但之后在 itertools 模块中实现成了一个 izip() 函数。
参考材料
1、PEP 255 Simple Generators www.python.org/dev/peps/pe…
2、(1, 2) PEP 212 Loop Counter Iteration www.python.org/dev/peps/pe…
3、PEP 234 Iterators www.python.org/dev/peps/pe…
版权
本文档已经进入公共领域。源文档: