
一 前言
本文讲详细讲解 nodejs 中两个比较难以理解的部分异步I/O和事件循环,对 nodejs 核心知识点,做梳理和补充。
送人玫瑰,手有余香,希望阅读后感觉不错的同学,可以给点个赞,鼓励我继续创作前端硬文。
老规矩我们带上疑问开始今天的分析🤔🤔🤔:
- 1 说说 nodejs 的异步I/O ?
- 2 说说 nodejs 的事件循环机制 ?
- 3 介绍一下 nodejs 中事件循环的各个阶段 ?
- 4 nodejs 中 promise 和 nextTick 的区别?
- 5 nodejs 中 setImmediate 和 setTimeout 区别 ?
- 6 setTimeout 是精确的吗,什么情况影响 setTimeout 的执行?
- 7 nodejs 中事件循环和浏览器有什么不同 ?
二 异步I/O
概念
处理器访问任何寄存器和 Cache 等封装以外的数据资源都可以当成 I/O 操作,包括内存,磁盘,显卡等外部设备。在 Nodejs 中像开发者调用 fs 读取本地文件或网络请求等操作都属于I/O操作。(最普遍抽象 I/O 是文件操作和 TCP/UDP 网络操作)
Nodejs 为单线程的,在单线程模式下,任务都是顺序执行的,但是前面的任务如果用时过长,那么势必会影响到后续任务的进行,通常 I/O 与 cpu 之间的计算是可以并行进行的,但是同步的模式下,I/O的进行会导致后续任务的等待,这样阻塞了任务的执行,也造成了资源不能很好的利用。
为了解决如上的问题,Nodejs 选择了异步I/O的模式,让单线程不再阻塞,更合理的使用资源。
如何合理的看待Nodejs中异步I/O
前端开发者可能更清晰浏览器环境下的 JS 的异步任务,比如发起一次 ajax 请求,正如 ajax 是浏览器提供给 js 执行环境下可以调用的 api 一样 ,在 Nodejs 中提供了 http 模块可以让 js 做相同的事。比如监听|发送 http 请求,除了 http 之外,nodejs 还有操作本地文件的 fs 文件系统等。
如上 fs http 这些任务在 nodejs 中叫做 I/O 任务。理解了 I/O 任务之后,来分析一下在 Nodejs 中,I/O 任务的两种形态——阻塞和非阻塞。
nodejs中同步和异步IO模式
nodejs 对于大部分的 I/O 操作都提供了阻塞和非阻塞两种用法。阻塞指的是执行 I/O 操作的时候必须等待结果,才往下执行 js 代码。如下一下阻塞代码
同步I/O模式
/* TODO: 阻塞 */
const fs = require('fs');
const data = fs.readFileSync('./file.js');
console.log(data)
- 代码阻塞 :读取同级目录下的
file.js文件,结果data为buffer结构,这样当读取过程中,会阻塞代码的执行,所以console.log(data)将被阻塞,只有当结果返回的时候,才能正常打印data。 - 异常处理 :如上操作有一个致命点就是,如果出现了异常,(比如在同级目录下没有 file.js 文件),就会让整个程序报错,接下来的代码讲不会执行。通常需要 try catch来捕获错误边界。代码如下:
/* TODO: 阻塞 - 捕获异常 */
try{
const fs = require('fs');
const data = fs.readFileSync('./file1.js');
console.log(data)
}catch(e){
console.log('发生错误:',e)
}
console.log('正常执行')
- 如上即便发生了错误,也不会影响到后续代码的执行以及应用程序发生错误导致的退出。
同步 I/O 模式造成代码执行等待 I/O 结果,浪费等待时间,CPU 的处理能力得不到充分利用,I/O 失败还会让整整个线程退出。阻塞 I / O 在整个调用栈上示意图如下:

异步I/O模式
这就是刚刚介绍的异步I/O。首先看一下异步模式下的 I/O 操作:
/* TODO: 非阻塞 - 异步 I/O */
const fs = require('fs')
fs.readFile('./file.js',(err,data)=>{
console.log(err,data) // null <Buffer 63 6f 6e 73 6f 6c 65 2e 6c 6f 67 28 27 68 65 6c 6c 6f 2c 77 6f 72 6c 64 27 29>
})
console.log(111) // 111 先被打印~
fs.readFile('./file1.js',(err,data)=>{
console.log(err,data) // 保存 [ no such file or directory, open './file1.js'] ,找不到文件。
})
- 回调 callback 被异步执行,返回的第一个参数是错误信息,如果没有错误,那么返回
null,第二个参数为fs.readFile执行得到的真正内容。 - 这种异步的形式可以会优雅的捕获到执行 I/O 中出现的错误,比如说如上当读取
file1.js文件时候,出现了找不到对应文件的异常行为,会直接通过第一个参数形式传递到 callback 中。
比如如上的 callback ,作为一个异步回调函数,就像 setTimeout(fn) 的 fn 一样,不会阻塞代码执行。会在得到结果后触发,对于 Nodejs 异步执行 I/O 回调的细节,接下来会慢慢剖析。
对于异步 I/O 的处理, Nodejs 内部使用了线程池来处理异步 I/O 任务,线程池中会有多个 I/O 线程来同时处理异步的 I/O 操作,比如如上的的例子中,在整个 I/O 模型中会这样。

接下来将一起探索一下异步 I/O 执行过程。
事件循环
和浏览器一样,Nodejs 也有自身的执行模型——事件循环( eventLoop ),事件循环的执行模型受到宿主环境的影响,它不属于 javascript 执行引擎( 例如 v8 )的一部分,这就导致了不同宿主环境下事件循环模式和机制可能不同,直观的体现就是 Nodejs 和浏览器环境下对微任务( microtask )和宏任务( macrotask )处理存在差异。对于 Nodejs 的事件循环及其每一个阶段,接下来会详细探讨。
Nodejs 的事件循环有多个阶段,其中有一个专门处理 I/O 回调的阶段,每一个执行阶段我们可以称之为 Tick , 每一个 Tick 都会查询是否还有事件以及关联的回调函数 ,如上异步 I/O 的回调函数,会在 I/O 处理阶段检查当前 I/O 是否完成,如果完成,那么执行对应的 I/O 回调函数,那么这个检查 I/O 是否完成的观察者我们称之为 I/O 观察者。
观察者
如上提到了 I/O 观察者的概念,也讲了 Nodejs 中会有多个阶段,事实上每一个阶段都有一个或者多个对应的观察者,它们的工作很明确就是在每一次对应的 Tick 过程中,对应的观察者查找有没有对应的事件执行,如果有,那么取出来执行。
浏览器的事件来源于用户的交互和一些网络请求比如 ajax 等, Nodejs 中,事件来源于网络请求 http ,文件 I/O 等,这些事件都有对应的观察者,我这里枚举出一些重要的观察者。
- 文件 I/O 操作 —— I/O 观察者;
- 网络 I/O 操作 —— 网络 I/O 观察者;
- process.nextTick —— idle 观察者
- setImmediate —— check 观察者
- setTimeout/setInterval —— 延时器观察者
- ...
在 Nodejs 中,对应观察者接收对应类型的事件,事件循环过程中,会向这些观察者询问有没有该执行的任务,如果有,那么观察者会取出任务,交给事件循环去执行。
请求对象与线程池
从 JavaScript 调用到计算机系统执行完 I/O 回调,请求对象充当着很重要的作用,我们还是以一次异步 I/O 操作为例
请求对象: 比如之前调用 fs.readFile ,本质上调用 libuv 上的方法创建一个请求对象。这个请求对象上保留着此次 I/O 请求的信息,包括此次 I/O 的主体和回调函数等。然后异步调用的第一阶段就完成了,JavaScript 会继续往下执行执行栈上的代码逻辑,当前的 I/O 操作将以请求对象的形式放入到线程池中,等待执行。达到了异步 I/O 的目的。
线程池: Nodejs 的线程池在 Windows 下有内核( IOCP )提供,在 Unix 系统中由 libuv 自行实现, 线程池用来执行部分的 I/O (系统文件的操作),线程池大小默认为 4 ,多个文件系统操作的请求可能阻塞到一个线程中。那么线程池里面的 I/O 操作是怎么执行的呢? 上一步说到,一次异步 I/O 会把请求对象放在线程池中,首先会判断当前线程池是否有可用的线程,如果线程可用,那么会执行请求对象的 I/O 操作,并把执行后的结果返回给请求对象。在事件循环中的 I/O 处理阶段,I/O 观察者会获取到已经完成的 I/O 对象,然后取出回调函数和结果调用执行。I/O 回调函数就这样执行,而且在回调函数的参数重获取到结果。
异步 I/O 操作机制
上述讲了整个异步 I/O 的执行流程,从一个异步 I/O 的触发,到 I/O 回调到执行。事件循环 ,观察者 ,请求对象 ,线程池 构成了整个异步 I/O 执行模型。
用一幅图表示四者的关系:

总结上述过程:
第一阶段:每一次异步 I/O 的调用,首先在 nodejs 底层设置请求参数和回调函 callback,形成请求对象。
第二阶段:形成的请求对象,会被放入线程池,如果线程池有空闲的 I/O 线程,会执行此次 I/O 任务,得到结果。
第三阶段:事件循环中 I/O 观察者,会从请求对象中找到已经得到结果的 I/O 请求对象,取出结果和回调函数,将回调函数放入事件循环中,执行回调,完成整个异步 I/O 任务。
对于如何感知异步 I/O 任务执行完毕的?以及如何获取完成的任务的呢? libuv 作为中间层, 在不同平台上,采用手段不同,在 unix 下通过 epoll 轮询,在 Windows 下通过内核( IOCP )来实现 ,FreeBSD 下通过 kqueue 实现。
三 事件循环
事件循环机制由宿主环境实现
上述中已经提及了事件循环不是 JavaScript 引擎的一部分 ,事件循环机制由宿主环境实现,所以不同宿主环境下事件循环不同 ,不同宿主环境指的是浏览器环境还是 nodejs 环境 ,但在不同操作系统中,nodejs 的宿主环境也是不同的,接下来用一幅图描述一下 Nodejs 中的事件循环和 javascript 引擎之间的关系。
以 libuv 下 nodejs 的事件循环为参考,关系如下:

以浏览器下 javaScript 的事件循环为参考,关系如下:

事件循环本质上就像一个 while 循环,如下所示,我来用一段代码模拟事件循环的执行流程。
const queue = [ ... ] // queue 里面放着待处理事件
while(true){
//开始循环
//执行 queue 中的任务
//....
if(queue.length ===0){
return // 退出进程
}
}
- Nodejs 启动后,就像创建一个 while 循环一样,
queue里面放着待处理的事件,每一次循环过程中,如果还有事件,那么取出事件,执行事件,如果存在事件关联的回调函数,那么执行回调函数,然后开始下一次循环。 - 如果循环体中没有事件,那么将退出进程。
我总结了流程图如下所示:

那么如何事件循环是如何处理这些任务的呢?我们列出 Nodejs 中一些常用的事件任务:
setTimeout或setInterval延时器计时器。- 异步 I/O 任务:文件任务 ,网络请求等。
setImmediate任务。process.nextTick任务。Promise微任务。
接下来会一一讲到 ,这些任务的原理以及 nodejs 是如何处理这些任务的。
1 事件循环阶段
对于不同的事件任务,会在不同的事件循环阶段执行。根据 nodejs 官方文档,在通常情况下,nodejs 中的事件循环根据不同的操作系统可能存在特殊的阶段,但总体是可以分为以下 6 个阶段 (代码块的六个阶段) :
/*
┌───────────────────────────┐
┌─>│ timers │ -> 定时器,延时器的执行
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │ -> i/o
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
*/
第一阶段:
timer,timer 阶段主要做的事是,执行setTimeout或setInterval注册的回调函数。第二阶段:pending callback ,大部分 I/O 回调任务都是在 poll 阶段执行的,但是也会存在一些上一次事件循环遗留的被延时的 I/O 回调函数,那么此阶段就是为了调用之前事件循环延迟执行的 I/O 回调函数。
第三阶段:idle prepare 阶段,仅用于 nodejs 内部模块的使用。
第四阶段:poll 轮询阶段,这个阶段主要做两件事,一这个阶段会执行异步 I/O 的回调函数; 二 计算当前轮询阶段阻塞后续阶段的时间。
第五阶段:check阶段,当 poll 阶段回调函数队列为空的时候,开始进入 check 阶段,主要执行
setImmediate回调函数。第六阶段:close阶段,执行注册
close事件的回调函数。
对于每一个阶段的执行特点和对应的事件任务,我接下来会详细剖析。我们看一下六个阶段在底层源码中是怎么样体现的。
我们看一下 libuv 下 nodejs 的事件循环的源代码(在 unix 和 win 有点差别,不过不影响流程,这里以 unix 为例子。):
libuv/src/unix/core.c
````c++
int uv_run(uv_loop_t* loop, uv_run_mode mode) {
// 省去之前的流程。
while (r != 0 && loop->stop_flag == 0) {
/* 更新事件循环的时间 */
uv__update_time(loop);
/*第一阶段: timer 阶段执行 */
uv__run_timers(loop);
/*第二阶段: pending 阶段 */
ran_pending = uv__run_pending(loop);
/*第三阶段: idle prepare 阶段 */
uv__run_idle(loop);
uv__run_prepare(loop);
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
/* 计算 timeout 时间 */
timeout = uv_backend_timeout(loop);
/* 第四阶段:poll 阶段 */
uv__io_poll(loop, timeout);
/* 第五阶段:check 阶段 */
uv__run_check(loop);
/* 第六阶段: close 阶段 */
uv__run_closing_handles(loop);
/* 判断当前线程还有任务 */
r = uv__loop_alive(loop);
/* 省去之后的流程 */
}
return r;
}
* 我们看到六个阶段是按序执行的,只有完成上一阶段的任务,才能进行下一阶段
* 当 `uv__loop_alive` 判断当前事件循环没有任务,那么退出线程。
### 2 任务队列
在整个事件循环过程中,有四个队列(**实际的数据结构不是队列**)是在 libuv 的事件循环中进行的,还有两个队列是在 nodejs 中执行的分别是 **promise 队列** 和 **nextTick** 队列。
> 在 NodeJS 中不止一个队列,不同类型的事件在它们自己的队列中入队。在处理完一个阶段后,移向下一个阶段之前,事件循环将会处理两个中间队列,直到两个中间队列为空。
#### libuv 处理任务队列
事件循环的每一个阶段,都会执行对应任务队列里面的内容。
* timer 队列( **PriorityQueue** ):本质上的数据结构是**二叉最小堆**,二叉最小堆的根节点获取最近的时间线上的 timer 对应的回调函数。
* I/O 事件队列:存放 I/O 任务。
* Immediate 队列( **ImmediateList** ):多个 Immediate ,node 层用链表数据结构储存。
* 关闭回调事件队列:放置待 close 的回调函数。
#### 非 libuv 中间队列
* **nextTick** 队列 : 存放 nextTick 的回调函数。这个是在 nodejs 中特有的。
* **Microtasks** 微队列 Promise : 存放 promise 的回调函数。
中间队列的执行特点:
* 首先要明白两个中间队列并非在 libuv 中被执行,它们都是在 nodejs 层执行的,在 libuv 层处理每一个阶段的任务之后,会和 node 层进行通讯,那么会优先处理两个队列中的任务。
* nextTick 任务的优先级要大于 Microtasks 任务中的 Promise 回调。也就是说 node 会首先清空 nextTick 中的任务,然后才是 Promise 中的任务。为了验证这个结论,例举一个打印结果的题目如下:
````js
/* TODO: 打印顺序 */
setTimeout(()=>{
console.log('setTimeout 执行')
},0)
const p = new Promise((resolve)=>{
console.log('Promise执行')
resolve()
})
p.then(()=>{
console.log('Promise 回调执行')
})
process.nextTick(()=>{
console.log('nextTick 执行')
})
console.log('代码执行完毕')
如上代码块中的 nodejs 中的执行顺序是什么?
效果:

打印结果:Promise执行 -> 代码执行完毕 -> nextTick 执行 -> Promise 回调执行 -> setTimeout 执行
解释:很好理解为什么这么打印,在主代码事件循环中,Promise执行 和 代码执行完毕 最先被打印,nextTick 被放入 nextTick 队列中,Promise 回调放入 Microtasks 队列中,setTimeout 被放入 timer 堆中。接下来主循环完成,开始清空两个队列中的内容,首先清空 nextTick 队列,nextTick 执行 被打印,接下来清空 Microtasks 队列,Promise 回调执行 被打印,最后再判断事件循环 loop 中还有 timer 任务,那么开启新的事件循环 ,首先执行,timer 任务,setTimeout 执行被打印。 整个流程完毕。
- 无论是 nextTick 的任务,还是 promise 中的任务, 两个任务中的代码会阻塞事件循环的有序进行,导致 I/O 饿死的情况发生,所以需要谨慎处理两个任务中的逻辑。比如如下:
/* TODO: 阻塞 I/O 情况 */
process.nextTick(()=>{
const now = +new Date()
/* 阻塞代码三秒钟 */
while( +new Date() < now + 3000 ){
}
})
fs.readFile('./file.js',()=>{
console.log('I/O: file ')
})
setTimeout(() => {
console.log('setTimeout: ')
}, 0);
效果:

- 三秒钟, 事件循环中的 timer 任务和 I/O 任务,才被有序执行。也就是说
nextTick中的代码,阻塞了事件循环的有序进行。
3 事件循环流程图
接下来用流程图,表示事件循环的六大阶段的执行顺序,以及两个优先队列的执行逻辑。

4 timer 阶段 -> 计时器 timer / 延时器 interval
延时器计时器观察者(Expired timers and intervals):延时器计时器观察者用来检查通过 setTimeout 或 setInterval创建的异步任务,内部原理和异步 I/O 相似,不过定期器/延时器内部实现没有用线程池。通过setTimeout 或 setInterval定时器对象会被插入到延时器计时器观察者内部的二叉最小堆中,每次事件循环过程中,会从二叉最小堆顶部取出计时器对象,判断 timer/interval 是否过期,如果有,然后调用它,出队。再检查当前队列的第一个,直到没有过期的,移到下一个阶段。
libuv 层如何处理 timer
首先一起看一下 libuv 层是如何处理的 timer
libuv/src/timer.c
````c++
void uv__run_timers(uv_loop_t loop) {
struct heap_node heap_node;
uv_timer_t* handle;
for (;;) {
/ 找到 loop 中 timer_heap 中的根节点 ( 值最小 ) /
heap_node = heap_min((struct heap) &loop->timer_heap);
/ */
if (heap_node == NULL)
break;
handle = container_of(heap_node, uv_timer_t, heap_node);
if (handle->timeout > loop->time)
/* 执行时间大于事件循环事件,那么不需要在此次 loop 中执行 */
break;
uv_timer_stop(handle);
uv_timer_again(handle);
handle->timer_cb(handle);
}
}
* 如上 handle timeout 可以理解成过期时间,也就是计时器回到函数的执行时间。
* 当 timeout 大于当前事件循环的开始时间时,即表示还没有到执行时机,回调函数还不应该被执行。那么根据二叉最小堆的性质,父节点始终比子节点小,那么根节点的时间节点都不满足执行时机的话,其他的 timer 也不满足执行时间。此时,退出 timer 阶段的回调函数执行,直接进入事件循环下一阶段。
* 当过期时间小于当前事件循环 tick 的开始时间时,表示至少存在一个过期的计时器,那么循环迭代计时器最小堆的根节点,并调用该计时器所对应的回调函数。每次循环迭代时都会更新最小堆的根节点为最近时间节点的计时器。
如上是 timer 阶段在 libuv 中执行特点。接下里分析一下 node 中是如何处理定时器延时器的。
#### node 层如何处理 timer
在 Nodejs 中 `setTimeout` 和 `setInterval` 是 nodejs 自己实现的,来一起看一下实现细节:
> node/lib/timers.js
````js
function setTimeout(callback,after){
//...
/* 判断参数逻辑 */
//..
/* 创建一个 timer 观察者 */
const timeout = new Timeout(callback, after, args, false, true);
/* 将 timer 观察者插入到 timer 堆中 */
insert(timeout, timeout._idleTimeout);
return timeout;
}
- setTimeout: 逻辑很简单,就是创建一个 timer 时间观察者,然后放入计时器堆中。
那么 Timeout 做了些什么呢?
node/lib/internal/timers.js
````js
function Timeout(callback, after, args, isRepeat, isRefed) {
after = 1
if (!(after >= 1 && after <= 2 * 31 - 1)) {
after = 1 // 如果延时器 timeout 为 0 ,或者是大于 2 31 - 1 ,那么设置成 1
}
this._idleTimeout = after; // 延时时间
this._idlePrev = this;
this._idleNext = this;
this._idleStart = null;
this._onTimeout = null;
this._onTimeout = callback; // 回调函数
this._timerArgs = args;
this._repeat = isRepeat ? after : null;
this._destroyed = false;
initAsyncResource(this, 'Timeout');
}
* 在 nodejs 中无论 setTimeout 还是 setInterval 本质上都是 Timeout 类。超出最大时间阀 `2 ** 31 - 1` 或者 `setTimeout(callback, 0)` ,_idleTimeout 会被设置成 1 ,转换为 setTimeout(callback, 1) 来执行。
#### timer 处理流程图
用一副流程图描述一下,我们创建一个 timer ,再到 timer 在事件循环里面执行的流程。
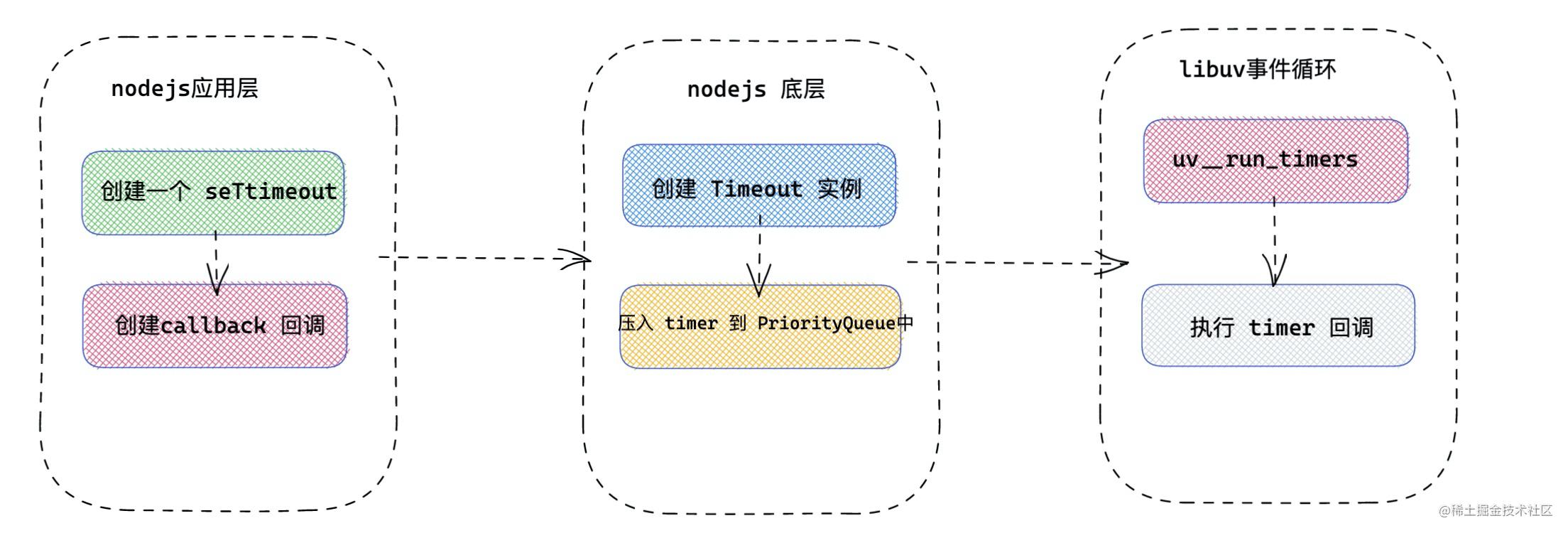
#### timer 特性
这里有两点需要注意:
* **执行机制** :延时器计时器观察者,每一次都会执行一个,执行一个之后会清空 nextTick 和 Promise, 过期时间是决定两者是否执行的重要因素,还有一点 poll 会计算阻塞 timer 执行的时间,对 timer 阶段任务的执行也有很重要的影响。
验证结论一次执行一个 timer 任务 ,先来看一段代码片段:
````js
setTimeout(()=>{
console.log('setTimeout1:')
process.nextTick(()=>{
console.log('nextTick')
})
},0)
setTimeout(()=>{
console.log('setTimeout2:')
},0)
打印结果:

nextTick 队列是在事件循环的每一阶段结束执行的,两个延时器的阀值都是 0 ,如果在 timer 阶段一次性执行完,过期任务的话,那么打印 setTimeout1 -> setTimeout2 -> nextTick ,实际上先执行一个 timer 任务,然后执行 nextTick 任务,最后再执行下一个 timer 任务。
精度问题 :关于 setTimeout 的计数器问题,计时器并非精确的,尽管在 nodejs 的事件循环非常的快,但是从延时器 timeout 类的创建,会占用一些事件,再到上下文执行, I/O 的执行,nextTick 队列执行,Microtasks 执行,都会阻塞延时器的执行。甚至在检查 timer 过期的时候,也会消耗一些 cpu 时间。
性能问题 :如果想用 setTimeout(fn,0) 来执行一些非立即调用的任务,那么性能上不如
process.nextTick实在,首先 setTimeout 精度不够,还有一点就是里面有定时器对象,并需要在 libuv 底层执行,占用一定性能,所以可以用process.nextTick解决这种场景。
5 pending 阶段
pending 阶段用来处理此次事件循环之前延时的 I/O 回调函数。首先看一下在 libuv 中执行时机。
libuv/src/unix/core.c
````c++
static int uvrun_pending(uv_loop_t loop) {
QUEUE q;
QUEUE pq;
uvio_t w
/ pending_queue 为空,清空队列 ,返回 0 */
if (QUEUE_EMPTY(&loop->pending_queue))
return 0;
QUEUE_MOVE(&loop->pending_queue, &pq);
while (!QUEUE_EMPTY(&pq)) { / pending_queue 不为空的情况,清空 I/O 回调。返回 1 /
q = QUEUE_HEAD(&pq);
QUEUE_REMOVE(q);
QUEUE_INIT(q);
w = QUEUE_DATA(q, uv__io_t, pending_queue);
w->cb(loop, w, POLLOUT);
}
return 1;
}
* 如果存放 I/O 回调的任务的 `pending_queue` 是空的,那么直接返回 0。
* 如果 pending_queue 有 I/O 回调任务,那么执行回调任务。
### 6 idle, prepare 阶段
`idle` 做一些 libuv 一些内部操作, `prepare` 为接下来的 I/O 轮询做一些准备工作。接下来一起解析一下比较重要 `poll` 阶段。
### 7 poll I / O 轮询阶段
在正式讲解 poll 阶段做哪些事情之前,首先看一下,在 libuv 中,轮询阶段的执行逻辑:
````c++
timeout = 0;
if ((mode == UV_RUN_ONCE && !ran_pending) || mode == UV_RUN_DEFAULT)
/* 计算 timeout */
timeout = uv_backend_timeout(loop);
/* 进入 I/O 轮询 */
uv__io_poll(loop, timeout);
- 初始化超时时间 timeout = 0 ,通过
uv_backend_timeout计算本次poll阶段的超时时间。超时时间会影响到异步 I/O 和后续事件循环的执行。
timeout代表什么
首先要明白不同 timeout ,在 I/O 轮询中代表什么意思。
- 当
timeout = 0的时候,说明 poll 阶段不会阻塞事件循环的进行,那么说明有更迫切执行的任务。那么当前的 poll 阶段不会发生阻塞,会尽快进入下一阶段,尽快结束当前 tick,进入下一次事件循环,那么这些紧急任务将被执行。 - 当
timeout = -1时,说明会一直阻塞事件循环,那么此时就可以停留在异步 I/O 的 poll 阶段,等待新的 I/O 任务完成。 - 当
timeout等于常数的情况,说明此时 io poll 循环阶段能够停留的时间,那么什么时候会存在 timeout 为常数呢,将马上揭晓。
获取timeout
timeout 的获取是通过 uv_backend_timeout 那么如何获得的呢?
int uv_backend_timeout(const uv_loop_t* loop) {
/* 当前事件循环任务停止 ,不阻塞 */
if (loop->stop_flag != 0)
return 0;
/* 当前事件循环 loop 不活跃的时候 ,不阻塞 */
if (!uv__has_active_handles(loop) && !uv__has_active_reqs(loop))
return 0;
/* 当 idle 句柄队列不为空时,返回 0,即不阻塞。 */
if (!QUEUE_EMPTY(&loop->idle_handles))
return 0;
/* i/o pending 队列不为空的时候。 */
if (!QUEUE_EMPTY(&loop->pending_queue))
return 0;
/* 有关闭回调 */
if (loop->closing_handles)
return 0;
/* 计算有没有延时最小的延时器 | 定时器 */
return uv__next_timeout(loop);
}
uv_backend_timeout 主要做的事情是:
- 当前事件循环停止时,不阻塞。
- 当前事件循环 loop 不活跃的时候 ,不阻塞。
- 当 idle 队列 ( setImmediate ) 不为空时,返回 0,不阻塞。
- i/o pending 队列不为空的时候,不阻塞。
- 有关闭回调函数的时候,不阻塞。
- 如果上述均不满足,那么通过
uv__next_timeout计算有没有延时阀值最小的定时器 | 延时器( 最急迫执行 ),返回延时时间。
接下来看一下 uv__next_timeout 逻辑。
>
int uv__next_timeout(const uv_loop_t* loop) {
const struct heap_node* heap_node;
const uv_timer_t* handle;
uint64_t diff;
/* 找到延时时间最小的 timer */
heap_node = heap_min((const struct heap*) &loop->timer_heap);
if (heap_node == NULL) /* 如何没有 timer,那么返回 -1 ,一直进入 poll 状态 */
return -1;
handle = container_of(heap_node, uv_timer_t, heap_node);
/* 有过期的 timer 任务,那么返回 0,poll 阶段不阻塞 */
if (handle->timeout <= loop->time)
return 0;
/* 返回当前最小阀值的 timer 与 当前事件循环的事件相减,得出来的时间,可以证明 poll 可以停留多长时间 */
diff = handle->timeout - loop->time;
return (int) diff;
}
uv__next_timeout 做的事情如下:
- 找到时间阀值最小的 timer (最优先执行的),如何没有 timer,那么返回 -1 。poll 阶段将无限制阻塞。这样的好处是一旦有 I/O 执行完毕 ,I/O 回调函数会直接加入到 poll ,接下来就会执行对应的回调函数。
- 如果有 timer ,但是
timeout <= loop.time证明已经过期了,那么返回 0,poll 阶段不阻塞,优先执行过期任务。 - 如果没有过期,返回当前最小阀值的 timer 与 当前事件循环的事件相减得值,即是可以证明 poll 可以停留多长时间。当停留完毕,证明有过期 timer ,那么进入到下一个 tick。
执行io_poll
接下来就是 uv__io_poll 真正的执行,里面有一个 epoll_wait 方法,根据 timeout ,来轮询有没有 I/O 完成,有得话那么执行 I/O 回调。这也是 unix 下异步I/O 实现的重要环节。
poll阶段本质
接下来总结一下 poll 阶段的本质:
- poll 阶段就是通过 timeout 来判断,是否阻塞事件循环。poll 也是一种轮询,轮询的是 i/o 任务,事件循环倾向于 poll 阶段的持续进行,其目的就是更快的执行 I/O 任务。如果没有其他任务,那么将一直处于 poll 阶段。
- 如果有其他阶段更紧急待执行的任务,比如 timer ,close ,那么 poll 阶段将不阻塞,会进行下一个 tick 阶段。
poll 阶段流程图
我把整个 poll 阶段做的事用流程图表示,省去了一些细枝末节。

8 check 阶段
如果 poll 阶段进入 idle 状态并且 setImmediate 函数存在回调函数时,那么 poll 阶段将打破无限制的等待状态,并进入 check 阶段执行 check 阶段的回调函数。
check 做的事就是处理 setImmediate 回调。,先来看一下 Nodejs 中是怎么定义的 setImmediate。
Nodejs 底层中的 setImmediate
setImmediate定义
node/lib/timer.js
function setImmediate(callback, arg1, arg2, arg3) { validateCallback(callback); /* 校验一下回调函数 */ /* 创建一个 Immediate 类 */ return new Immediate(callback, args); }
- 当调用
setImmediate本质上调用 nodejs 中的 setImmediate 方法,首先校验回调函数,然后创建一个Immediate类。接下来看一下 Immediate 类。node/lib/internal/timers.js
````js
class Immediate{
constructor(callback, args) {
this._idleNext = null;
this._idlePrev = null; / 初始化参数 /
this._onImmediate = callback;
this._argv = args;
this._destroyed = false;
this[kRefed] = false;
initAsyncResource(this, 'Immediate');
this.ref();
immediateInfo[kCount]++;
immediateQueue.append(this); /* 添加 */
}
}
* Immediate 类会初始化一些参数,然后将当前 Immediate 类,插入到 `immediateQueue` 链表中。
* immediateQueue 本质上是一个链表,存放每一个 Immediate。
**setImmediate执行**
poll 阶段之后,会马上到 check 阶段,执行 immediateQueue 里面的 Immediate。 在每一次事件循环中,会先执行一个setImmediate 回调,然后清空 nextTick 和 Promise 队列的内容。为了验证这个结论,同样和 setTimeout 一样,看一下如下代码块:
````js
setImmediate(()=>{
console.log('setImmediate1')
process.nextTick(()=>{
console.log('nextTick')
})
})
setImmediate(()=>{
console.log('setImmediate2')
})

打印 setImmediate1 -> nextTick -> setImmediate2 ,在每一次事件循环中,执行一个 setImmediate ,然后执行清空 nextTick 队列,在下一次事件循环中,执行另外一个 setImmediate2 。
setImmediate执行流程图

setTimeout & setImmediate
接下来对比一下 setTimeout 和 setImmediate,如果开发者期望延时执行的异步任务,那么接下来对比一下 setTimeout(fn,0) 和 setImmediate(fn) 区别。
- setTimeout 是 用于在设定阀值的最小误差内,执行回调函数,setTimeout 存在精度问题,创建 setTimeout 和 poll 阶段都可能影响到 setTimeout 回调函数的执行。
- setImmediate 在 poll 阶段之后,会马上进入 check 阶段,会执行
setImmediate回调。
如果 setTimeout 和 setImmediate 在一起,那么谁先执行呢?
首先写一个 demo:
setTimeout(()=>{
console.log('setTimeout')
},0)
setImmediate(()=>{
console.log( 'setImmediate' )
})
猜测
先猜测一下,setTimeout 发生 timer 阶段,setImmediate 发生在 check 阶段,timer 阶段早于 check 阶段,那么 setTimeout 优先于 setImmediate 打印。但事实是这样吗?
实际打印结果

从以上打印结果上看, setTimeout 和 setImmediate 执行时机是不确定的,为什么会造成这种情况,上文中讲到即使 setTimeout 第二个参数为 0,在 nodejs 中也会被处理 setTimeout(fn,1)。当主进程的同步代码执行之后,会进入到事件循环阶段,第一次进入 timer 中,此时 settimeout 对应的 timer 的时间阀值为 1,若在前文 uv__run_timer(loop) 中,系统时间调用和时间比较的过程总耗时没有超过 1ms 的话,在 timer 阶段会发现没有过期的计时器,那么当前 timer 就不会执行,接下来到 check 阶段,就会执行 setImmediate 回调,此时的执行顺序是: setImmediate -> setTimeout。
但是如果总耗时超过一毫秒的话,执行顺序就会发生变化,在 timer 阶段,取出过期的 setTimeout 任务执行,然后到 check 阶段,再执行 setImmediate ,此时 setTimeout -> setImmediate。
造成这种情况发生的原因是:timer 的时间检查距当前事件循环 tick 的间隔可能小于 1ms 也可能大于 1ms 的阈值,所以决定了 setTimeout 在第一次事件循环执行与否。
接下来我用代码阻塞的情况,会大概率造成 setTimeout 一直优先于 setImmediate 执行。
/* TODO: setTimeout & setImmediate */
setImmediate(()=>{
console.log( 'setImmediate' )
})
setTimeout(()=>{
console.log('setTimeout')
},0)
/* 用 100000 循环阻塞代码,促使 setTimeout 过期 */
for(let i=0;i<100000;i++){
}
效果:

100000 循环阻塞代码,这样会让 setTimeout 超过时间阀值执行,这样就保证了每次先执行 setTimeout -> setImmediate 。
特殊情况:确定顺序一致性。我们看一下特殊的情况。
const fs = require('fs')
fs.readFile('./file.js',()=>{
setImmediate(()=>{
console.log( 'setImmediate' )
})
setTimeout(()=>{
console.log('setTimeout')
},0)
})
如上情况就会造成,setImmediate 一直优先于 setTimeout 执行,至于为什么,来一起分析一下原因。
- 首先分析一下异步任务——主进程中有一个异步 I/O 任务,I/O 回调中有一个 setImmediate 和 一个 setTimeout 。
- 在
poll阶段会执行 I/O 回调。然后处理一个 setImmediate
万变不离其宗,只要掌握了如上各个阶段的特性,那么对于不同情况的执行情况,就可以清晰的分辨出来。
9 close 阶段
close 阶段用于执行一些关闭的回调函数。执行所有的 close 事件。接下来看一下 close 事件 libuv 的实现。
libuv/src/unix/core.c
````c++
static void uv__run_closing_handles(uv_loop_t loop) {
uv_handle_t p;
uv_handle_t* q;
p = loop->closing_handles;
loop->closing_handles = NULL;
while (p) {
q = p->next_closing;
uv__finish_close(p);
p = q;
}
}
* `uv__run_closing_handles` 这个方法循环执行 close 队列里面的回调函数。
### 10 Nodejs 事件循环总结
接下来总结一下 Nodejs 事件循环。
* Nodejs 的事件循环分为 6 大阶段。分别为 timer 阶段,pending 阶段,prepare 阶段,poll 阶段, check 阶段,close 阶段。
* nextTick 队列和 Microtasks 队列执行特点,在每一阶段完成后执行, nextTick 优先级大于 Microtasks ( Promise )。
* poll 阶段主要处理 I/O,如果没有其他任务,会处于轮询阻塞阶段。
* timer 阶段主要处理定时器/延时器,它们并非准确的,而且创建需要额外的性能浪费,它们的执行还收到 poll 阶段的影响。
* pending 阶段处理 I/O 过期的回调任务。
* check 阶段处理 setImmediate。 setImmediate 和 setTimeout 执行时机和区别。
## 四 Nodejs事件循环习题演练
接下来为了更清楚事件循环流程,这里出两道事件循环的问题。作为实践:
### 习题一
````js
process.nextTick(function(){
console.log('1');
});
process.nextTick(function(){
console.log('2');
setImmediate(function(){
console.log('3');
});
process.nextTick(function(){
console.log('4');
});
});
setImmediate(function(){
console.log('5');
process.nextTick(function(){
console.log('6');
});
setImmediate(function(){
console.log('7');
});
});
setTimeout(e=>{
console.log(8);
new Promise((resolve,reject)=>{
console.log(8+'promise');
resolve();
}).then(e=>{
console.log(8+'promise+then');
})
},0)
setTimeout(e=>{ console.log(9); },0)
setImmediate(function(){
console.log('10');
process.nextTick(function(){
console.log('11');
});
process.nextTick(function(){
console.log('12');
});
setImmediate(function(){
console.log('13');
});
});
console.log('14');
new Promise((resolve,reject)=>{
console.log(15);
resolve();
}).then(e=>{
console.log(16);
})
如果刚看这个 demo 可以会发蒙,不过上述讲到了整个事件循环,再来看这个问题就很轻松了,下面来分析一下整体流程:
- 第一阶段: 首先开始启动 js 文件,那么进入第一次事件循环,那么先会执行同步任务:
最先打印:
打印console.log('14');
打印console.log(15);
nextTick 队列:
nextTick -> console.log(1)
nextTick -> console.log(2) -> setImmediate(3) -> nextTick(4)
Promise队列
Promise.then(16)
check队列
setImmediate(5) -> nextTick(6) -> setImmediate(7)
setImmediate(10) -> nextTick(11) -> nextTick(12) -> setImmediate(13)
timer队列
setTimeout(8) -> promise(8+'promise') -> promise.then(8+'promise+then')
setTimeout(9)
- 第二阶段:在进入新的事件循环之前,清空 nextTick 队列,和 promise 队列,顺序是 nextTick 队列大于 Promise 队列。
清空 nextTick ,打印:
console.log('1');
console.log('2');
执行第二个 nextTick 的时候,又有一个 nextTick ,所以会把这个 nextTick 也加入到队列中。接下来马上执行。
console.log('4')
接下来清空Microtasks
console.log(16);
此时的 check 队列加入了新的 setImmediate。
check队列
setImmediate(5) -> nextTick(6) -> setImmediate(7)
setImmediate(10) -> nextTick(11) -> nextTick(12) -> setImmediate(13)
setImmediate(3)
- 然后进入新的事件循环,首先执行 timer 里面的任务。执行第一个 setTimeout。
执行第一个 timer:
console.log(8);
此时发现一个 Promise 。在正常的执行上下文中:
console.log(8+'promise');
然后将 Promise.then 加入到 nextTick 队列中。接下里会马上清空 nextTick 队列。
console.log(8+'promise+then');
执行第二个 timer:
console.log(9)
- 接下来到了 check 阶段,执行 check 队列里面的内容:
执行第一个 check:
console.log(5);
此时发现一个 nextTick ,然后还有一个 setImmediate 将 setImmediate 加入到 check 队列中。然后执行 nextTick 。
console.log(6)
执行第二个 check
console.log(10)
此时发现两个 nextTick 和一个 setImmediate 。接下来清空 nextTick 队列。将 setImmediate 添加到队列中。
console.log(11)
console.log(12)
此时的 check 队列是这样的:
setImmediate(3)
setImmediate(7)
setImmediate(13)
接下来按顺序清空 check 队列。打印
console.log(3)
console.log(7)
console.log(13)
到此为止,执行整个事件循环。那么整体打印内容如下:

五 总结
本文主要讲的内容如下:
- 异步 I/O 介绍及其内部原理。
- Nodejs 的事件循环,六大阶段。
- Nodejs 中 setTimeout ,setImmediate , 异步 i/o ,nextTick ,Promise 的原理及其区别。
- Nodejs 事件循环实践。

