
前期准备
因为注册QQ互联需要已备案的网站,所以需要准备一个已备案的网站与域名。
首先访问QQ互联平台https://connect.qq.com/,注册成为开发者;
然后创建一个网站应用,等审核成功后会得到一个APP ID与APP KEY,后面会使用到。
开发流程
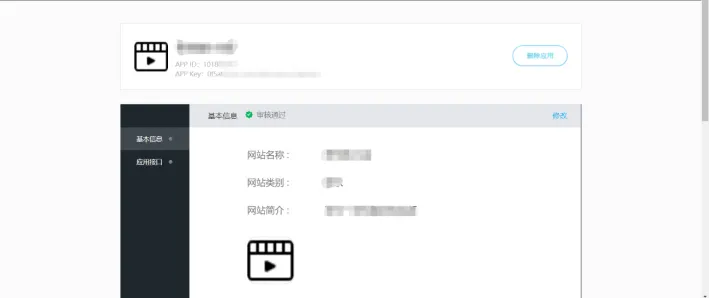
图1 准备网站应用
1 前端放置登录按钮
在网站找一个合适的位置放置登录按钮(建议放置在首页、登录页以及注册页)。登录按钮图标在QQ互联平台下载,上面提供了多种样式。效果如下:
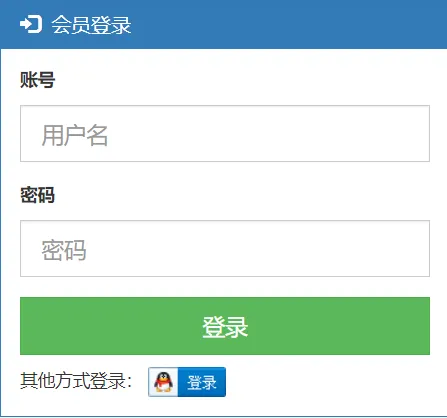
图2 登陆页
具体HTMl代码如下:
<a href="https://graph.qq.com/oauth2.0/authorize?response_type=code&client_id=YOURAPPID&redirect_uri=URL"> <img src="{{url_for('static',filename'base/images/Connect_logo_7.png')}}"></a> |
其中a标签中 client_id 是最开始申请的APPID,redirect_uri是申请网站填写的网站回调域。
这样点开QQ登录按钮,就能跳转到QQ登录的界面:
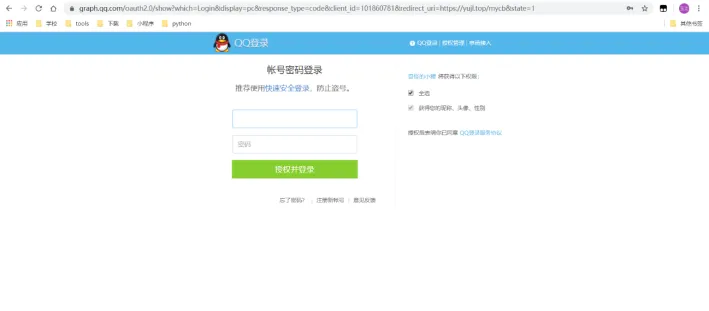
图3 转跳后页面
2 获取Access Toke
当登录成功后,会跳转到刚刚所填写的回调地址。并且url后面会跟上Authorization Code(此Code在10分钟内过期)。接着通过Code值去获取Access Token(Access Token是应用在调用OpenAPI访问和修改用户数据时必须传入的参数)。
为了获取Access Token需要请求:
https://graph.qq.com/oauth2.0/token,方式为GET,请求参数包括以下:
参数 |
是否必须 |
含义 |
grant_type |
必须 |
值为“authorization_code”。 |
client_id |
必须 |
申请QQ登录成功后,分配给网站的appid。 |
client_secret |
必须 |
申请QQ登录成功后,分配给网站的appkey。 |
code |
必须 |
上一步返回的authorization code |
redirect_uri |
必须 |
与上面一步中传入的redirect_uri保持一致。 |
如果成功返回,就可以得到Access Token。这一步具体代码如下:
@home.route('/mycb') def mycb(): data = request.args.to_dict() code = data.get('code') #获取authorization code url = 'https://graph.qq.com/oauth2.0/token' body={'grant_type': 'authorization_code', 'client_id': '101860781','client_secret':'0f5a014e13e7d35fbcca51ecc2ff6745','code':code,'redirect_uri':'https://yujl.top/mycb'} #body为上面所说的请求参数 response = requests.get(url, params=body) #发送GET请求 token = response.text 得到返回包 token_url = '?' + token requests.session().close() #关闭请求 return redirect('/token' + token_url) |
由于返回回来的包格式为:
access_token=61897CE***************D444F968BD2A&expires_in=77**000&refresh_token=0018693**************6009D9C2EFBE |
这样不能直接转换为json格式,所以将这个包作为参数然后转发到/token,以此来得到json格式的token。
@home.route('/token') def token(): data = request.args.to_dict() #得到access_token、expires_in、refresh_token |
3 通过access_token来获取open_id
接着需要通过access_token来获取open_id(openid是此网站上唯一对应用户身份的标识,网站可将此ID进行存储便于用户下次登录时辨识其身份)。
请求地址为https://graph.qq.com/oauth2.0/me,方法还是GET,参数就是上面获取到的access_token。具体方法为:
def get_openid(data): data为token得到的数据包 url = 'https://graph.qq.com/oauth2.0/me' body = {'access_token': data.get('access_token')} response = requests.get(url, params=body) open_id = json.loads(response.text[10:-4]) open_id = open_id.get('openid') requests.session().close() return open_id |
4 调用OpenAPI
得到open_id就可以调用OpenAPI了,API列表如下:

图4 API列表
接下来以get_user_info 为例:
还是以GET方式请求:
https://graph.qq.com/user/get_user_info,
需要的参数有access_token、oauth_consumer_key(APP ID)、openid。代码示例:
def get_user_info(data, open_id): url = 'https://graph.qq.com/user/get_user_info' body={'access_token':data.get('access_token'), 'oauth_consumer_key': '101860781', 'openid': open_id} response = requests.get(url, params=body) user_info = response.json() requests.session().close() return user_info |
返回的参数说明:
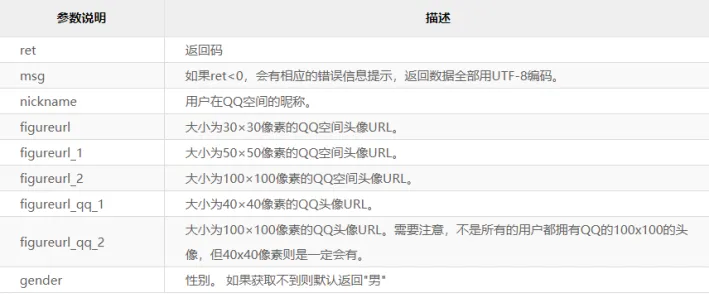
图5 参数说明
5 保存用户数据
到这一步,基本就完成了。接着就是根据自己的需要,可以在user界面展示昵称和头像,和选择存进数据库了。选择将open_id作为用户的唯一标识符存进数据库,这样用户在后面登录的时候可以得到上次保存的信息。以下是这部分代码:
@home.route('/token') def token(): data = request.args.to_dict() open_id = get_openid(data) user_info = get_user_info(data, open_id) uuid_count=User.query.filter_by(uuid=open_id).count() #查询openid是否存在。 if uuid_count == 1: #如果存在就根据openid查到用户信息,并添加到session空间里。 name = User.query.filter_by(uuid=open_id).first() session['home'] = name.name return redirect('/user') else: #如果不存在,也就是第一次登录,给一个默认的密码(经过hash加密) password = generate_password_hash('123456') hash_name = str(hash(random.randint(1000,9999))) name = user_info.get('nickname') + hash_name #因为我的网站是不允许重名的,所以在qq的昵称后面加上一个随机数。 user = User( name=name, #添加了随机数的用户名 uuid=open_id, #唯一标识符 pwd = password, #密码 face=user_info.get('figureurl_1') #头像 )#将相关信息存进数据库 db.session.add(user) db.session.commit() session['home'] = name #将用户名添加到session空间中。 return redirect('/user') # 重定向到user界面。 |

