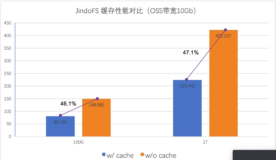
使用缓存可以有效缩短数据的读取路径和降低I/O操作频次,从而提高数据的读取响应速度。对象存储在原有的单机缓存的基础上,在集群范围内构建分布式缓存,进而优化数据读取的性能。
对象存储业务层的数据存储模型是按照桶(Bucket)、对象(Object)、块(Block)三个层级来对数据进行存储管理的。针对一次对象数据读取,用户请求会通过负载均衡到业务前端系统,业务前端系统通过计算得到对象的块列表并进行遍历,请求键值存储系统获取块数据,最后将读取的块数据有序地返回给用户。
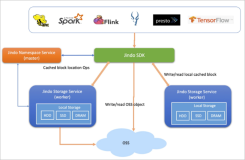
下图是用户读取数据的系统路径图,红线部分是键值存储系统直读飞天盘古优化。随着键值存储系统直读飞天盘古功能的上线开通,块数据的读取可以绕过键值存储系统,直接请求飞天盘古系统读取,这在一定程度缩短了数据读取的路径,减少了整体对象存储系统的响应时间,但是同时也使得键值存储系统路径上对数据读取的缓存优化失效,导致飞天盘古的请求压力上升。
用户读取数据的系统路径
另外,对象存储业务前端系统支持块数据的单机内存缓存。对于块数据读取,会优先去读取缓存,如果没有命中,就需要客户端请求键值存储系统获取数据。但单机内存缓存会由于业务前端机服务内存大小限制及负载均衡策略造成的流量发散而导致块数据的缓存命中率降低。
所以,从整体系统的架构上来考虑降低飞天盘古的请求压力,需要在对象存储业务前端系统服务层面去优化系统全局缓存,提高缓存的命中率。
典型的缓存架构包含读穿型缓存和旁路型缓存。读穿型缓存与旁路型缓存的区别在于请求方请求数据的时候,如果缓存没有命中,旁路型缓存由缓存客户端更新缓存,而读穿型缓存则由缓存服务端更新。基于业务读写数据模式,在业务前端系统的内部实现采用的是旁路型缓存,读块数据的时候,会优先去缓存中获取数据,如果没有,再调用键值存储系统客户端获取数据后更新缓存返回;而写块数据的时候,则直接通过键值存储系统客户端写入底层的键值存储系统,由键值存储系统写入飞天盘古,不做缓存更新。
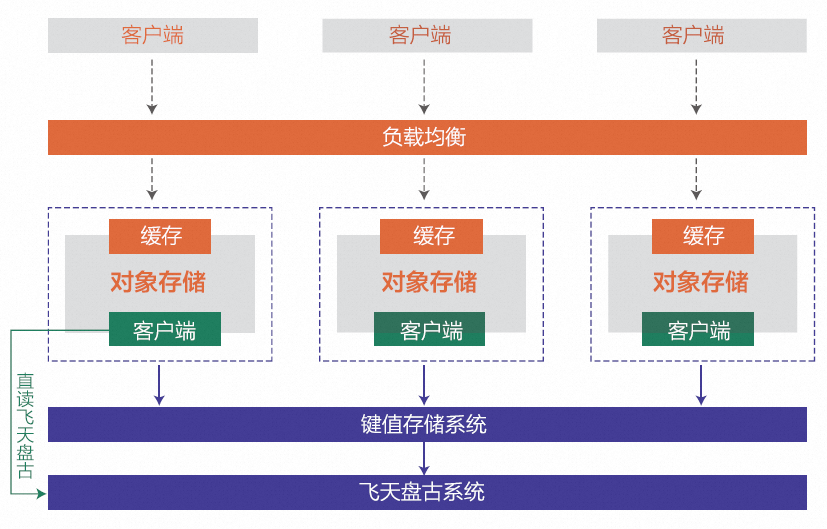
下图是在现有的业务前端系统的基础上设计和实现的分布式缓存系统架构图。分布式缓存主要通过一致性哈希算法来构建全局化缓存,用虚拟化节点来优化集群数据的均衡性。对象存储的分布式缓存系统架构是去中心化的,在业务前端系统中既实现了缓存服务端功能,也同时实现了基于一致性哈希算法的全局缓存节点管理和流量处理的缓存客户端功能。
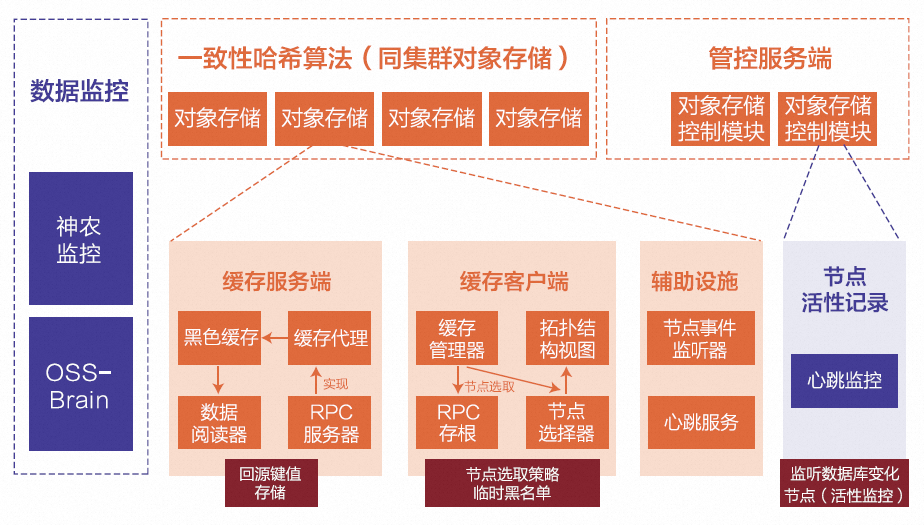
对象存储分布式缓存架构系统
在对象存储分布式缓存系统架构中,核心系统功能支撑可以分为三个部分:管控服务、缓存服务和数据监控。
管控服务负责管理集群服务节点的信息,实时收集集群缓存服务节点的心跳,为缓存节点提供集群范围内所有的缓存节点信息,是一个支持HTTP协议的Web集群服务。
缓存服务是在原有业务前端系统服务中构建的,主要包含三个功能模块:
(1)缓存服务端
缓存服务端模块是在LRU缓存功能的基础上构建的RPC服务,对外提供块数据读取功能并且支持慢启动。
(2)缓存客户端
缓存客户端则实现了RPC客户端功能,基于集群全局节点信息,利用一致性哈希算法构建全局缓存节点的哈希环。当用户请求获取数据时,数据的读取模块会调用缓存客户端,缓存客户端会根据块的Key信息获取存储该块数据的对应缓存节点,然后发起RPC请求获取块的相应数据。
(3)节点信息管理
节点信息管理则负责定时将本节点的信息更新给管控服务端,同时也定时从管控服务端同步全局缓存节点信息。
在数据监控方面,对象存储分布式缓存实施采集分布式缓存服务端的运行数据,监控分布式缓存服务端的整体状态。另外,通过数据分析功能获取热点数据,实时分析分布式缓存服务端的业务状态,同时为分布式缓存服务端热点数据的预热提供有效的数据支撑。