

英伟达 AI 科学家 Jim Fan 表示,「AutoGPT 只是一项有趣的实验,虽然火爆但并不意味着可以投入生产。」他的观点得到了很多人的附和和现身说法。
仿佛一夜之间,AI 圈出现了一个新晋顶流:AutoGPT。
顾名思义,AutoGPT 为自主人工智能,一项任务交给它,它能自主地提出计划,然后执行,完全不用人类插手的那种。此外其还具有互联网访问、使用 GPT-3.5 进行文件存储和生成摘要等功能。
例如,用户让 AutoGPT 建立一个网站,提出的要求是让其创建一个表单,并在表单上添加标题「Made with autogpt」,最后将背景更改为蓝色,用时不到 3 分钟,不用人类参与,AutoGPT 自己就搞定了,就像下面展示的那样。期间 AutoGPT 采用的 React 和 Tailwind CSS,都是自己决定的。
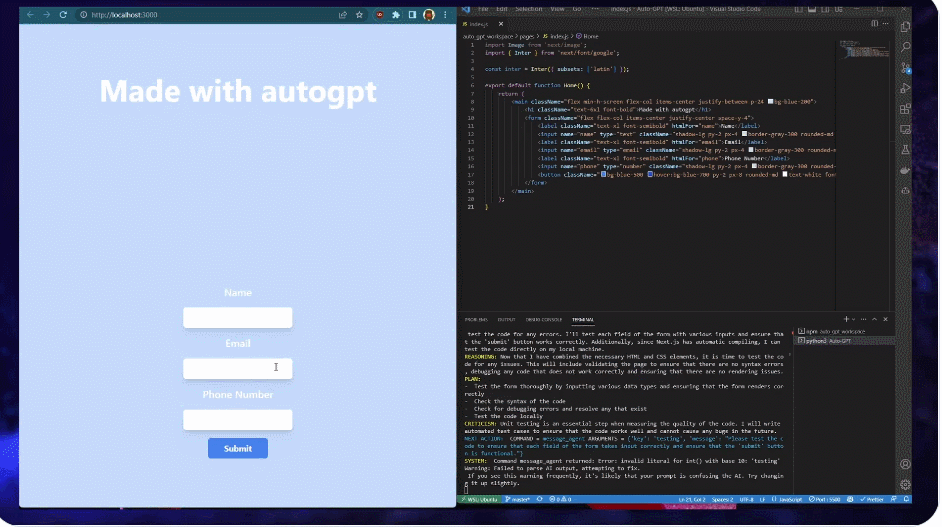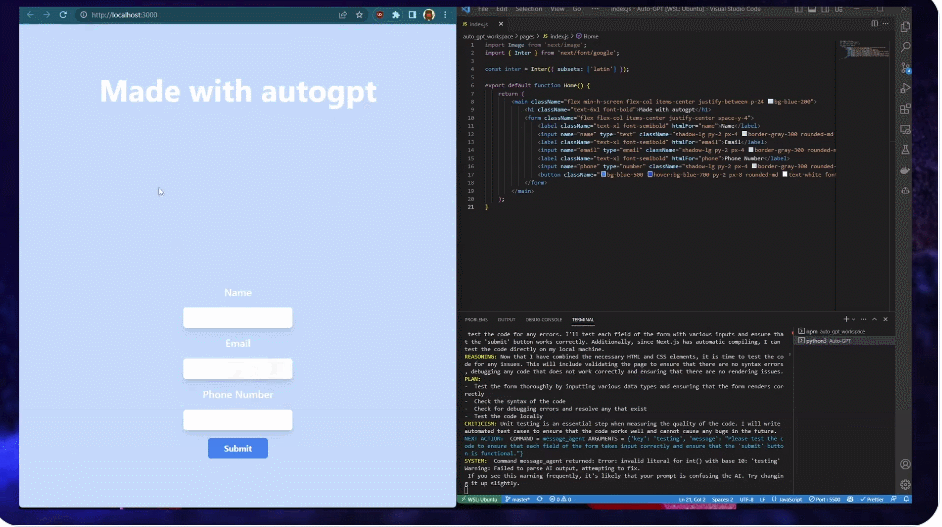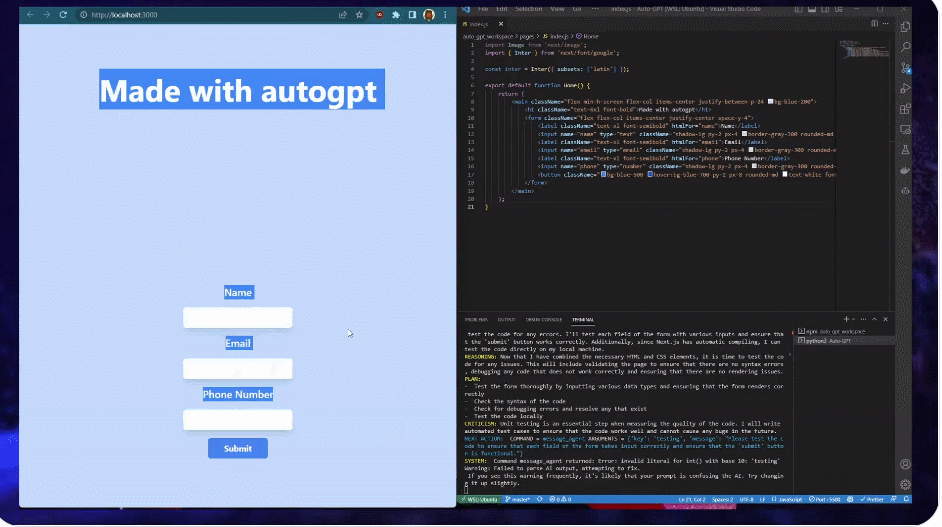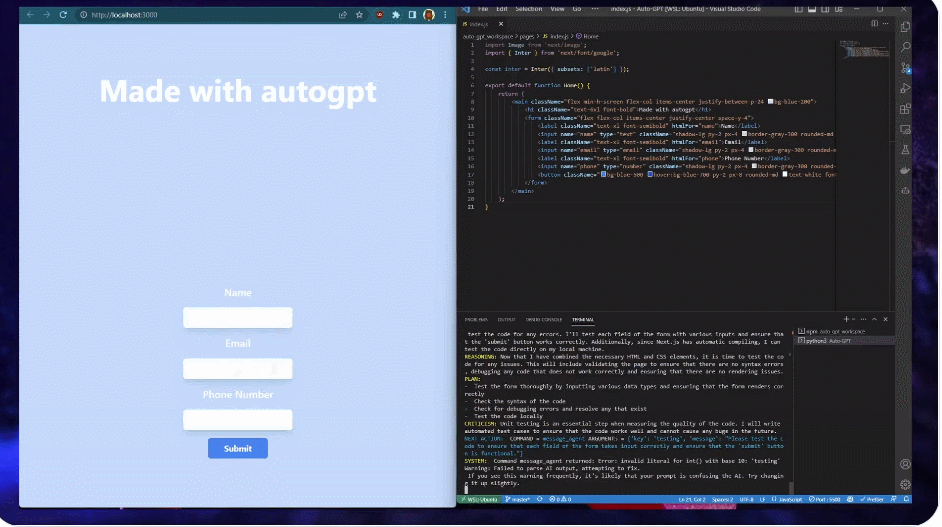
一个示例看下来,AutoGPT 已经能够自己上网查资料、使用第三方工具、操作你的电脑。从上线以来,项目热度不减,截至今天,AutoGPT 的 GitHub Star 量达到 78k,马上接近 80k,超过了 PyTorch 的 65k。


AutoGPT 地址:https://github.com/torantulino/auto-gpt
PyTorch 地址:https://github.com/pytorch/pytorch
要知道,AutoGPT 是一个刚上线没几天的项目,而 PyTorch 的最初版本可追溯到 2018 年。不仅如此,从推特网友的总结来看,AutoGPT 还超过了 Bitcoin、 Django 等项目的 Star 量。
 图源:https://twitter.com/MattPRD/status/1647653434760515584
图源:https://twitter.com/MattPRD/status/1647653434760515584
就连前特斯拉 AI 总监、刚刚回归 OpenAI 的 Andrej Karpathy 对此都评价道:「AutoGPT 是 prompt 工程的下一个前沿。」

不过,与看好 AutoGPT 发展不同的是,来自英伟达的 AI 科学家 Jim Fan 却对此泼了一盆冷水。
Jim Fan 表示自己仅将 AutoGPT 视为一项有趣的实验,仅此而已,而且这项研究虽然火爆但并不意味着可以投入生产,网上很多酷炫的演示都是精心挑选出来的。

随后,Jim Fan 还表示,在其实验中「AutoGPT 可以很好地解决某些简单且定义明确的任务,但大多数时候对真正有用的、更难的任务,AutoGPT 并不可靠。
这种不可靠性可以归因于 GPT-4 固有的局限性。如果不能访问 GPT-4 权重或者更好的微调,我认为仅仅通过提示技巧无法从根本上解决问题。
就像没有任何提示可以将 GPT-3 变成 GPT-4 的能力一样,我不认为 AutoGPT + 冻结的 GPT-4 可以可靠地解决重要的复杂决策。当前的媒体炒作正在将该项目推向完全不切实际的期望。」
附和者众:AutoGPT 局限大,无法解决任何商业问题
Jim Fan 的观点获得了很多人的赞同。有人认为,「诚然,AutoGPT 是一个伟大的实验,并将引领通过智能体自主完成很多酷炫事情的浪潮。但它不能成为一个可以构筑解决任何商业问题基础的产品,毕竟太不可预测了。」

光说不练没有说服力,有人现身说法,表示自己整个周六都在让 AutoGPT 打开一个 docx 文档、打开其导出的 ChatGPT 对话以提供更多上下文(json)、浏览其他技术内容并重写 docx 文档。遗憾的是,AutoGPT 甚至都未能接近达成这些目标,还是放弃吧。

这类体验例子还有很多,有人针对现实世界的问题尝试大量 prompt,但 AutoGPT 总是朝着没有任何意义的不同方向发展。

不同意见者:虽被夸大,其前景与 GPT 相当
在很多人赞同 Jim Fan 观点的同时,也有人指出,虽然 AutoGPT 肯定被夸大了,并且现在非常「蛮力」、不优雅。但它展示的前景仍然非常强大,几乎与 GPT 模型相当。

有人从应用的角度剖析 AutoGPT 的不足,目前它虽然无法很好地解决很多事情,比如循环(loop)、切线、随机完成不同的任务。但要弄清楚的是,AutoGPT 需要大量的脑力,预计它会变得越来越好。

持上述观点的不是个例,「AutoGPT 肯定会随时间推移而愈加完善。像这样的项目两年前就已经成为了可能,尽管在任意通用域上的可靠使用也许只能在数年而非数月内到来。」

机器之心的读者们,你们认为 AutoGPT 会是昙花一现吗?看不看好它的前景呢?请在评论区留下自己的观点吧!
参考链接:https://twitter.com/DrJimFan/status/1647616587199815684




