Kettle 是什么
Kettle 是一款国外开源的 ETL 工具,对商业用户也没有限制,纯 Java 编写,可以在 Window、Linux、Unix 上运行,绿色无需安装,数据抽取高效稳定。Kettle 中文名称叫水壶,它允许管理来自不同数据库的数据,把各种数据放到一个壶里,然后以一种指定的格式流出。Kettle 中有两种脚本文件,Transformation 和 Job, Transformation 完成针对数据的基础转换,Job 则完成整个工作流的控制。通过图形界面设计实现做什么业务,并在 Job 下的 start 模块,有一个定时功能,可以每日,每周等方式进行定时。
Kettle 的核心组件
| 名称 | 功能 |
| Spoon | 通过图形接口,允许你通过图形界面来设计 ETL 转换过程(Transformation) |
| Pan | 运行转换的命令行工具 |
| Kitchen | 运行作业的命令行工具 |
| Carte | Carte 是一个轻量级别的 Web 容器,用于建立专用、远程的 ETL Server |
- 作业和转换可以在图形界面里执行,但这只适合在开发、测试和调试阶段。在开发完成后,需要部署到生产环境中 Spoon 就很少用到了,Kitchen 和 Pan 命令行工具用于实际的生产环境。
- 部署生产阶段一般需要通过命令行执行,需要把命令行放到 Shell 脚本中,并定时调度这个脚本。
- Kitchen 和 Pan 工具是 Kettle 的命令行执行程序,只是在 Kettle 执行引擎上的封装,它们只是解释命令行参数,调用并把这些参数传递给 Kettle 引擎。
- Kitchen 和 Pan 在概念和用法上都非常相近,这两个命令的参数也基本是一样的。唯一不同的是 Kitchen 用于执行作业,Pan 用于执行转换。
Kettle 概念模型
Kettle 的执行分为两个层次:Job(作业,.kjb 后缀)和 Transformation(转换,.ktr 后缀)
 img
img
简单地说,一个转换就是一个 ETL 的过程,而作业则是多个转换、作业的集合,在作业中可以对转换或作业进行调度、定时任务等。
在实际过程中,写的流程不能很复杂,当数据抽取需要多步骤时,需要分成多个转换,在集成到一个作业里顺序摆放,然后执行即可。
目录文件功能说明
 来源网络
来源网络 来源网络
来源网络 来源网络下载及安装
来源网络下载及安装
官网各个版本下载地址:https://sourceforge.net/projects/pentaho/files/Data%20Integration/ 国内 Kettle 论坛网:https://www.kettle.net.cn/
Kettle 是纯 Java 编程的开源软件,需要安装 JDK,并配置环境变量,解压后直接使用无需安装。
需准备的其他东西:数据库驱动,如将驱动放在 Kettle 根目录的 bin 文件夹下面即可。
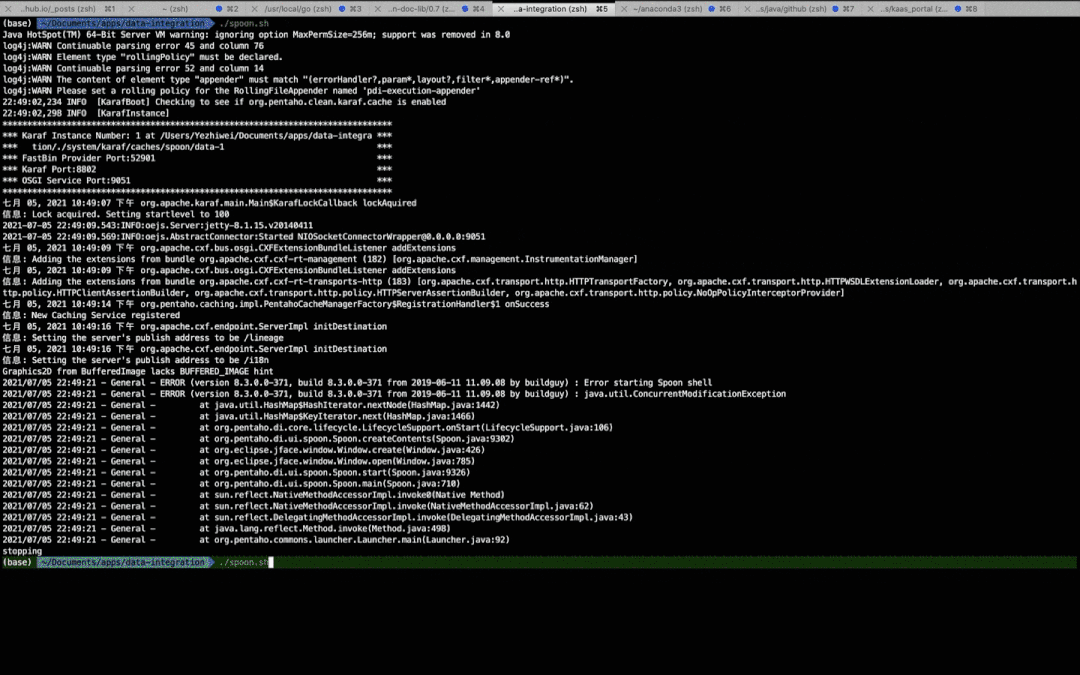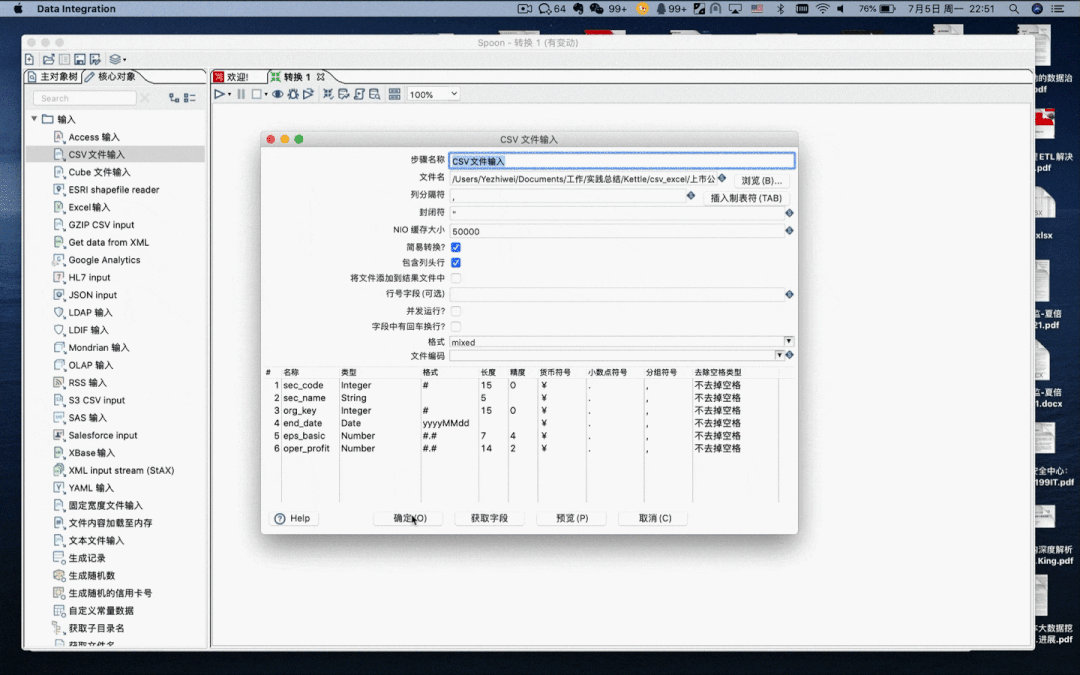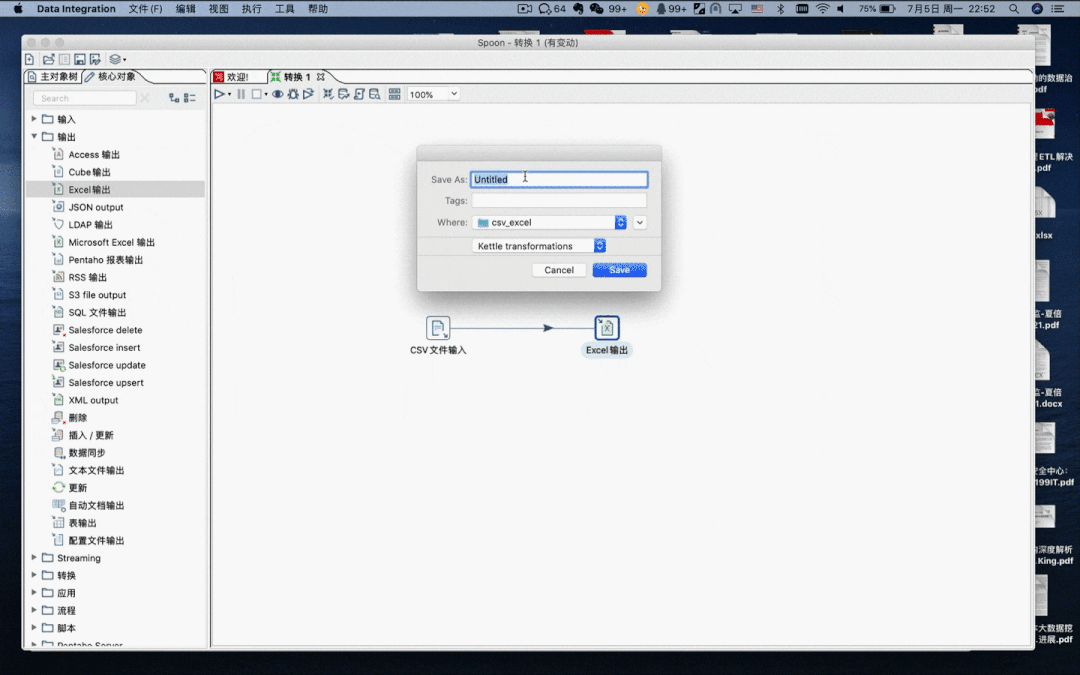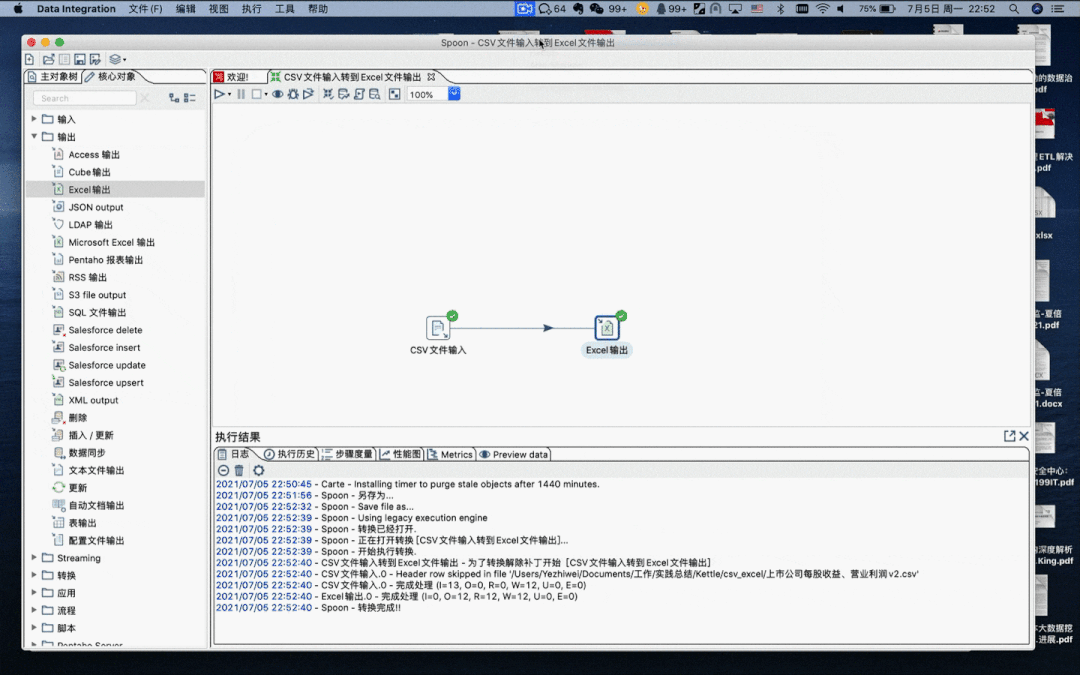
打开 Kettle 只需要运行 Spoon.bat (win)/ spoon.sh (Linux / macOS),即可打开 Spoon 图形工具。
启动 Kettle
如下图,执行 ./spoon.sh 命令
 image-20210705214148018
image-20210705214148018
欢迎页面
 首页HelloWorld
首页HelloWorld
需求:把数据从 CSV 文件复制到 Excel 文件
 CSV 文件到 Excel 文件
CSV 文件到 Excel 文件
CSV 文件输入
 CSV 输入控件
CSV 输入控件
将 「CSV 文件输入」拖拽到右侧的工作区,双击进行编辑,浏览选择准备好的测试文件,点击「获取字段」自动获取 CSV 文件中表头信息,输入配置完成,下一步进行输出配置。
 编辑 CSV 文件输入
编辑 CSV 文件输入
Excel 输出
 Excel 输出
Excel 输出
将 「Excel 输出」拖拽到右侧的工作区,双击进行编辑,这步比较简单,浏览选择输出目录和设置文件名,完成配置。
 输出配置
输出配置
转换文件
按住 shift + 鼠标左键可以建立连接,保存转换配置
 连接
连接
运行转换
 运行结果
运行结果
查看结果
 运行结果
运行结果
总结
初步了解 Kettle 核心组件及其使用
- 作业和转换可以在图形界面里执行,但这只适合在开发、测试和调试阶段。在开发完成后,需要部署到生产环境中 Spoon 就很少用到了,Kitchen 和 Pan 命令行工具用于实际的生产环境。
- 部署生产阶段一般需要通过命令行执行,需要把命令行放到 Shell 脚本中,并定时调度这个脚本。
- Kitchen 和 Pan 工具是 Kettle 的命令行执行程序,只是在 Kettle 执行引擎上的封装,它们只是解释命令行参数,调用并把这些参数传递给 Kettle 引擎。
- Kitchen 和 Pan 在概念和用法上都非常相近,这两个命令的参数也基本是一样的。唯一不同的是 Kitchen 用于执行作业,Pan 用于执行转换。
分步操作一个 HelloWrold 过程