
分别用线性SVM和高斯核SVM预测对数据进行分类
(1)问题描述:
task1_linear.mat中有一批数据点,试用线性SVM对他们进行分类,并在图中画分出决策边界。task1_gaussian中也有一批数据点,试用高斯核SVM对他们进行分类,并在图中画出决策边界。
(2)训练过程:
使用线性核函数的svm算法
1.加载数据并可视化:
加载一个2维数据集:
X,y = svmF.loadData('task1_linear.mat') svmF.plotData(X,y)
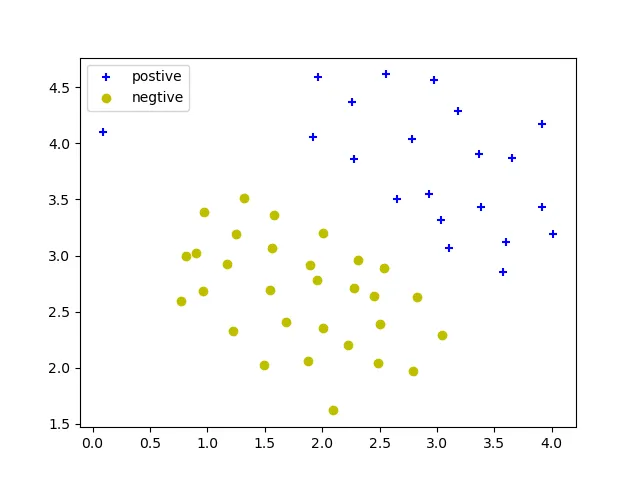
观察可知该数据集可以被线性边界分割为正样本和负样本。
2.训练模型与边界可视化:
model = svmF.svmTrain_SMO(X, y, C=1, max_iter=20) svmF.visualizeBoundaryLinear(X, y, model)
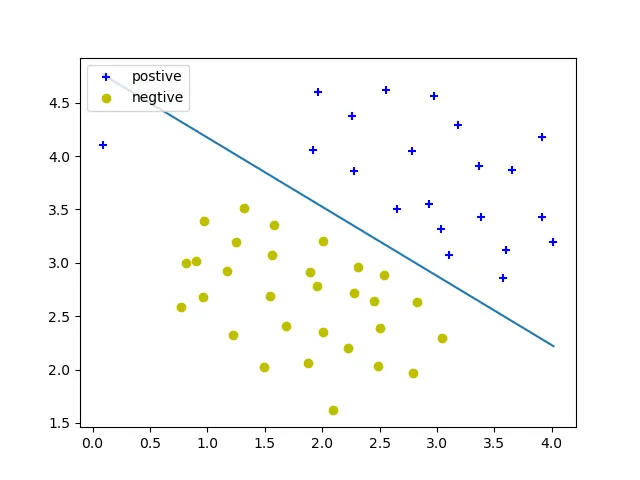
变量 C所起的作用于逻辑回归中的正则化参数1 \λ
变量C 值对决策边界有不同的影响,下面我们尝试分几种情况验证:
C = 1 :
C = 100 :
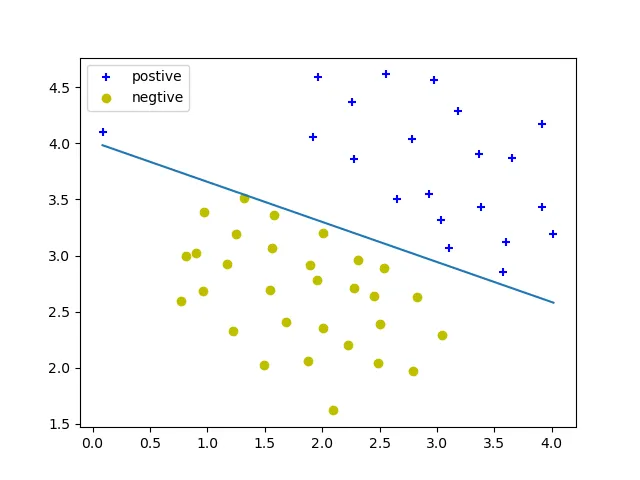
C = 1000 :

我们可以发现,C的大小影响着线性决策边界,其所起的作用于逻辑回归中正则化参数一样,C 太大,可能会导致过拟合问题。
使用高斯核函数的SVM算法
对于非线性的分类任务,常用带有高斯核函数的SVM算法来实现。
1.加载数据并可视化:
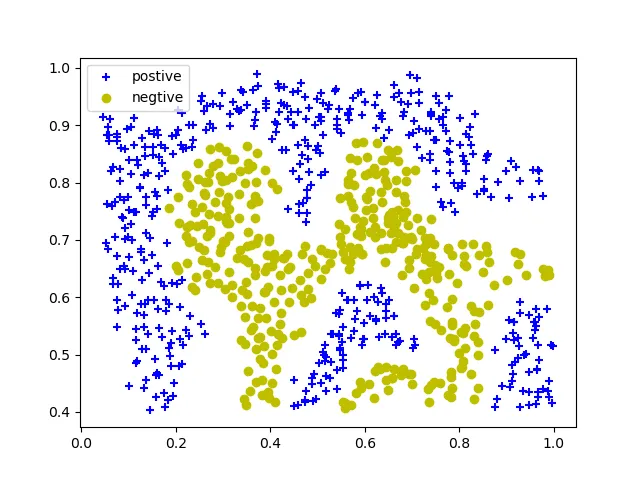
加载一个2维数据集:
X, y = svmF.loadData('task1_gaussian.mat') svmF.plotData(X, y)
可以很明显地看出是非线性的数据。
2.训练模型与边界可视化:
model = svmF.svmTrain_SMO(X, y, C=1, kernelFunction='gaussian', K_matrix=svmF.gaussianKernel(X, sigma=0.1)) svmF.visualizeBoundaryGaussian(X, y, model,sigma=0.1)
实现效果如下所示:
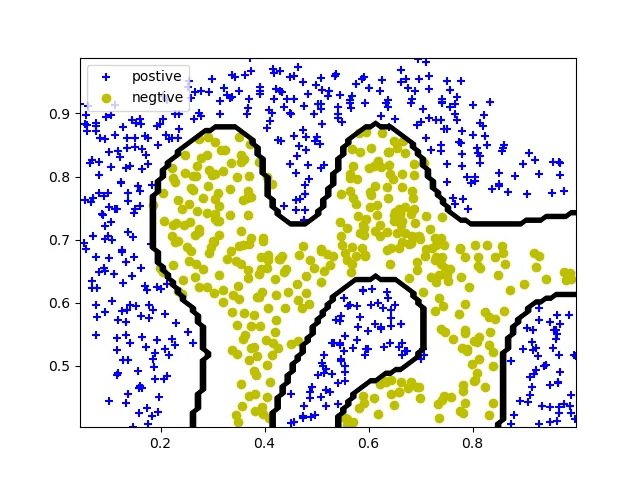
(3)尝试调用sklearn:
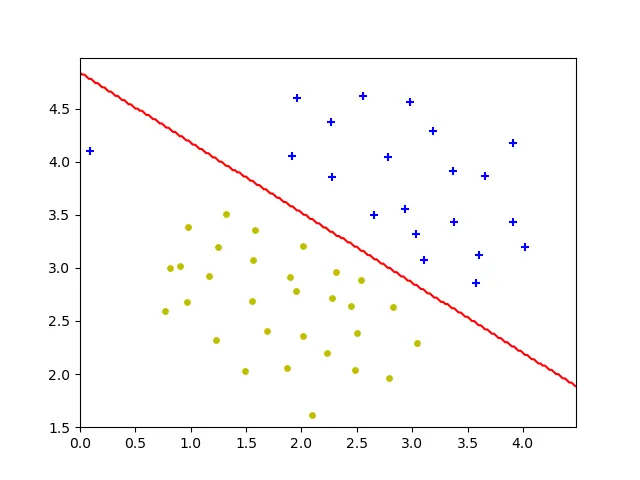
调用sklearn svm,如下所示:
from sklearn import svm c = 1 clf = svm.SVC(c, kernel='linear', tol=1e-3) clf.fit(X, y)
结果:
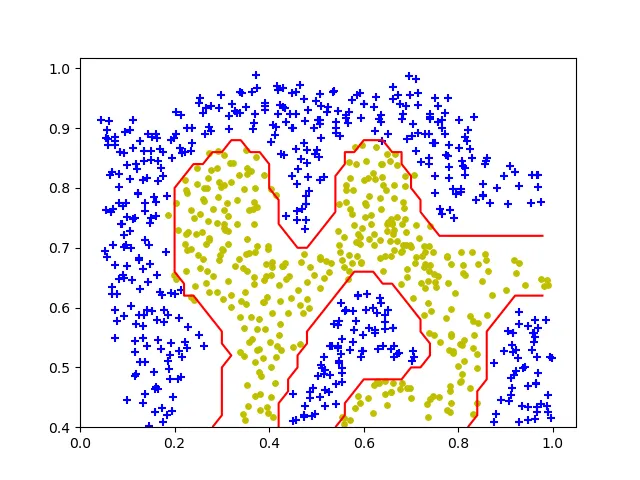
高斯核:
c = 1 sigma = 0.1 clf = svm.SVC(c, kernel='rbf', gamma=np.power(sigma, -2)) clf.fit(X, y)
结果
实验报告地址:
点这里链接


