
netcat-memory-logger
netcat是用来监听某一端口的数据,所以我们可以使用nc命令进行模拟,然后用Flume的source端监听该端口,然后传输到channel,最终传到logger控制台。
channel通常有两种形式,一种是memory,另外一种是file,两种方式分别基于内存和磁盘,可想而知,memory的效率会高很多,而磁盘的效率会相对差一点,但是基于磁盘的缓冲有一个优点就是能够大幅度的防止数据丢失,因为如果采用内存的话,一旦该服务器宕机,那么缓存在内存中的数据就会丢失,而缓冲在磁盘中,宕机恢复后会从磁盘重新进行读取,这样会更加可靠。
sink采用logger一般是用于检测,方便排错,将一些日志或数据传输到控制台。
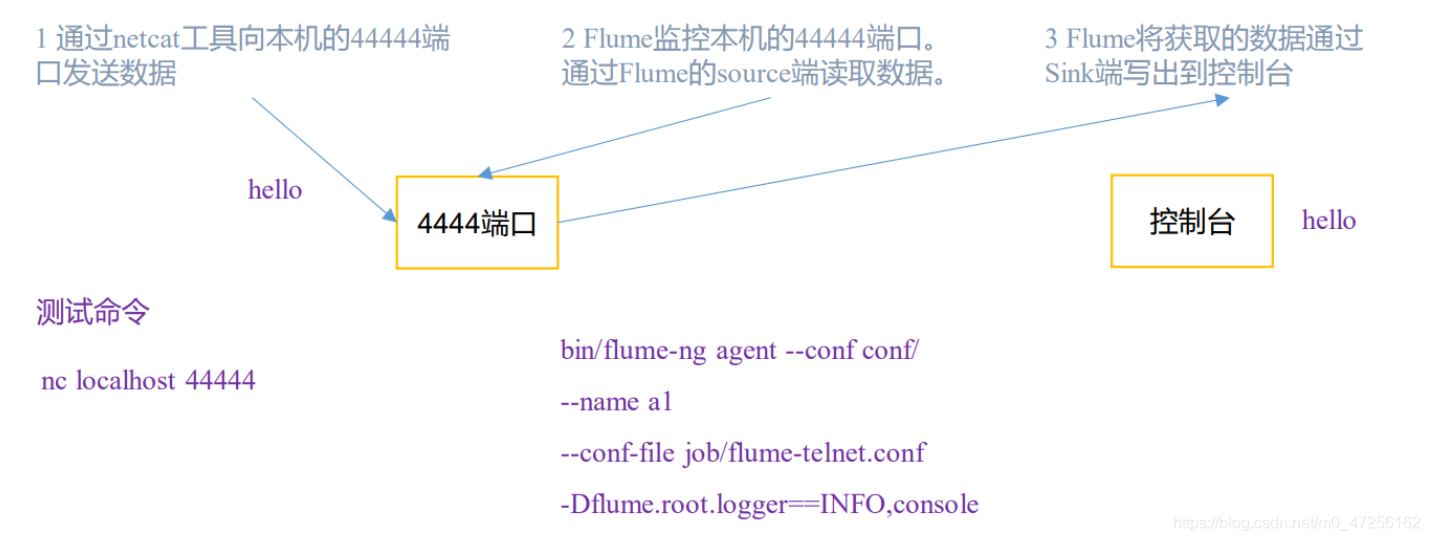
我们要执行上述的任务,就要更改相应的Flume配置信息。
a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444 a1.sinks.k1.type = logger a1.sinks.k1.hostname = hadoop104 a1.sinks.k1.port = 44444 a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
上边的capacity的1000不是对应什么字节或者内存大小这样,它对应的该缓存能够容纳多少事件,因为我们的数据从source端传过来后,Flume会对其进行加工,包装成一个Event类,包含头部和身体,身体一般就是序列化后的数据,而head对应我们自己封装的数据,对于拦截器可能会使用到,将事件拦截下,包装一些信息在里面。
那我们将文件配置好了,如何启动呢?
bin/flume-ng agent -n a1 -c conf -f job/netcat-memory-logger.conf -Dflume.root.logger=INFO,console
上述的命令意思就是开启Flume任务,agent是代表打开客户端,-n a1就是本次flume的任务名字,因为我们在一台服务器上面可以开多个任务去监控不同的任务,所以就要有名字进行区分,-c conf是用来加载配置信息,-f job/netcat-memory-logger.conf就是加载我们上面配置的文件,-Dflume.root.logger=INFO,console的意思就是将信息类日志信息级别的打印到控制台,如果你不加该命令,你会发现在控制台上看不到任何输出信息。
我们运行后,用nc localhost 44444与本机的44444端口进行通信,向44444端口发送数据,打开Flume任务进行监听该端口的数据。
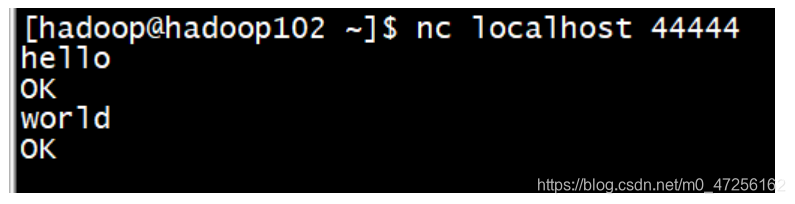

我们可以看到我们向44444端口发送的hello和world成功被flume监听到,并成功地打印到了控制台。
