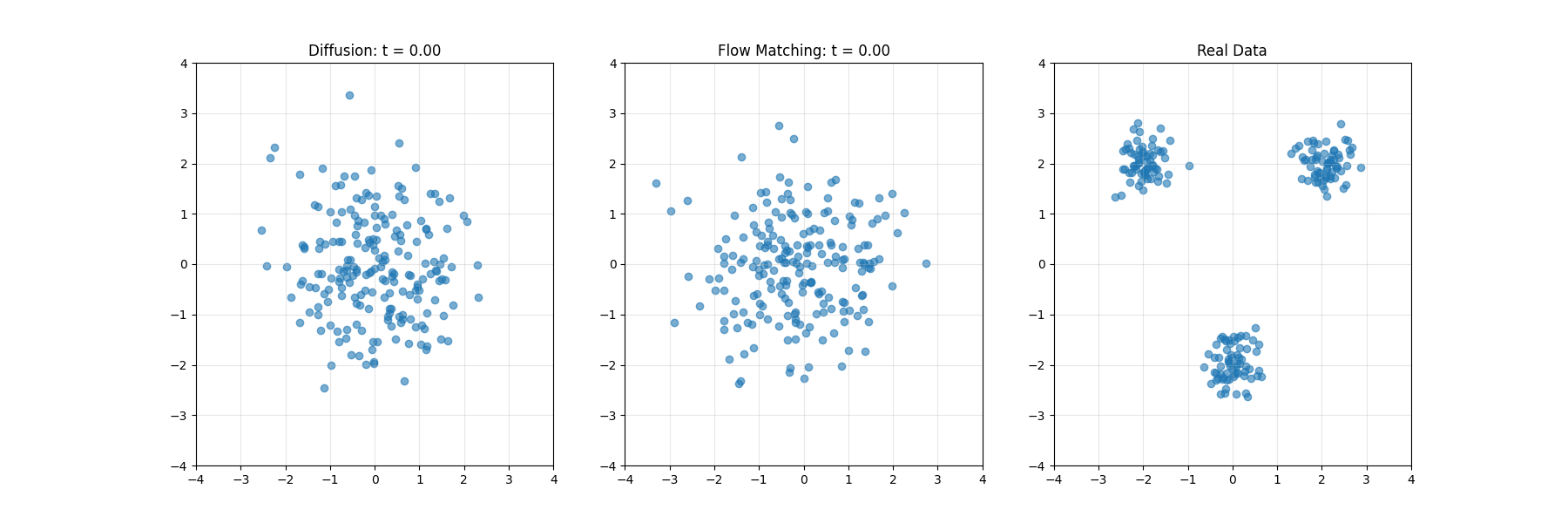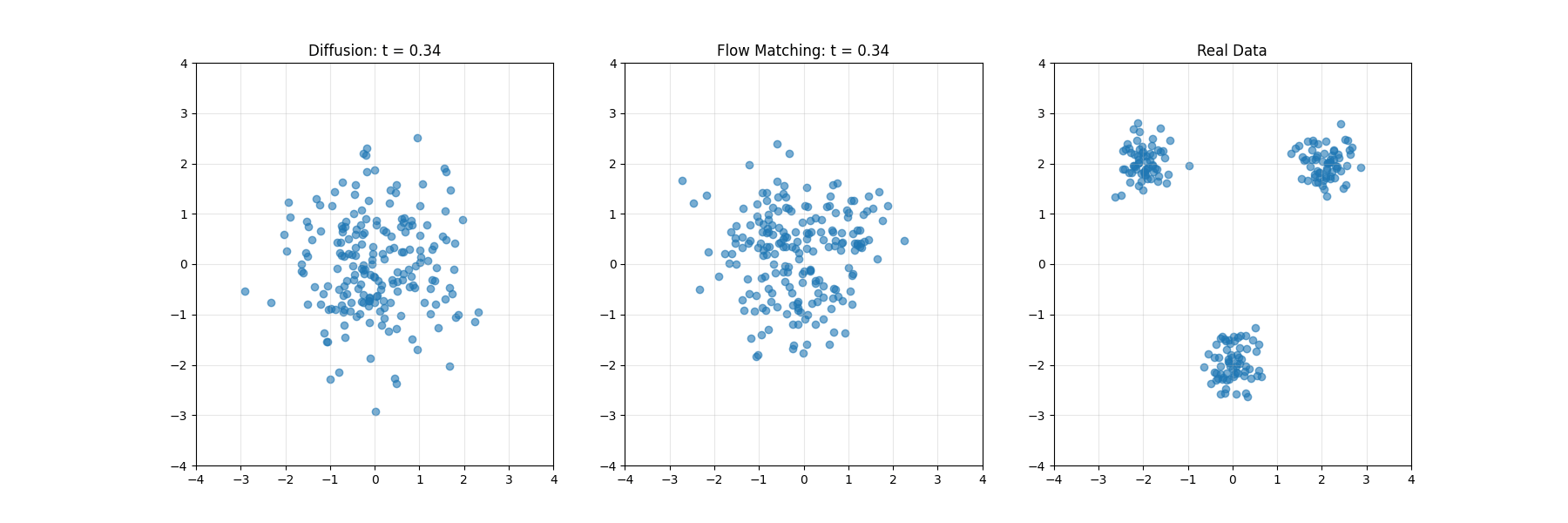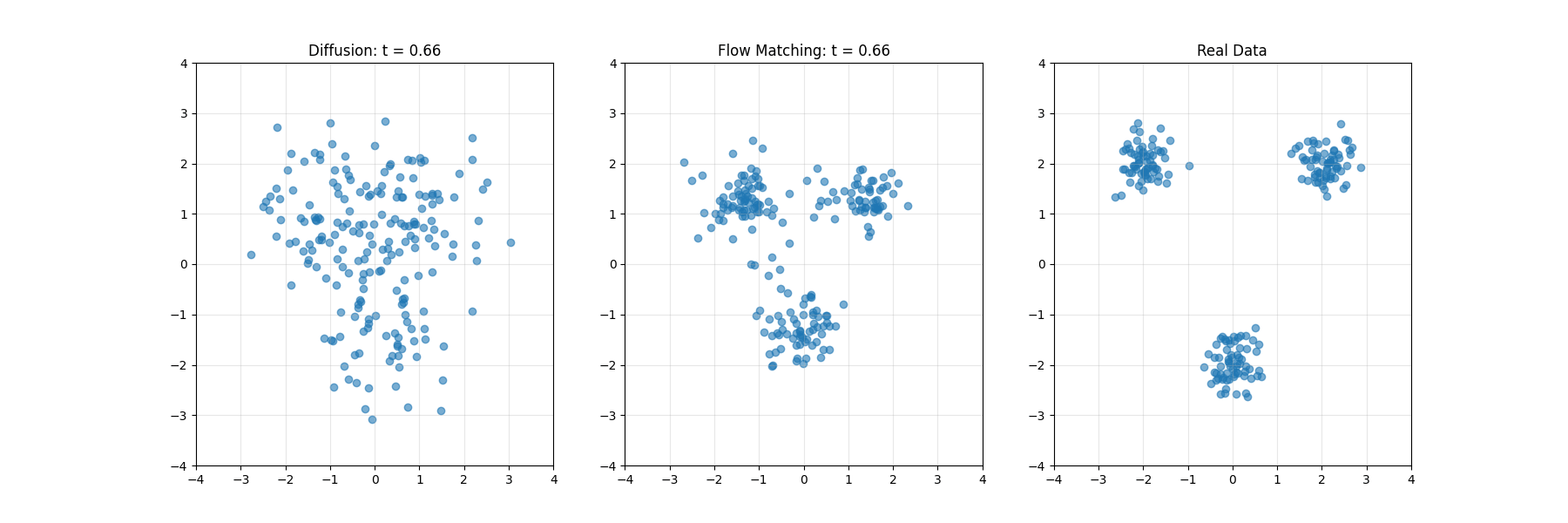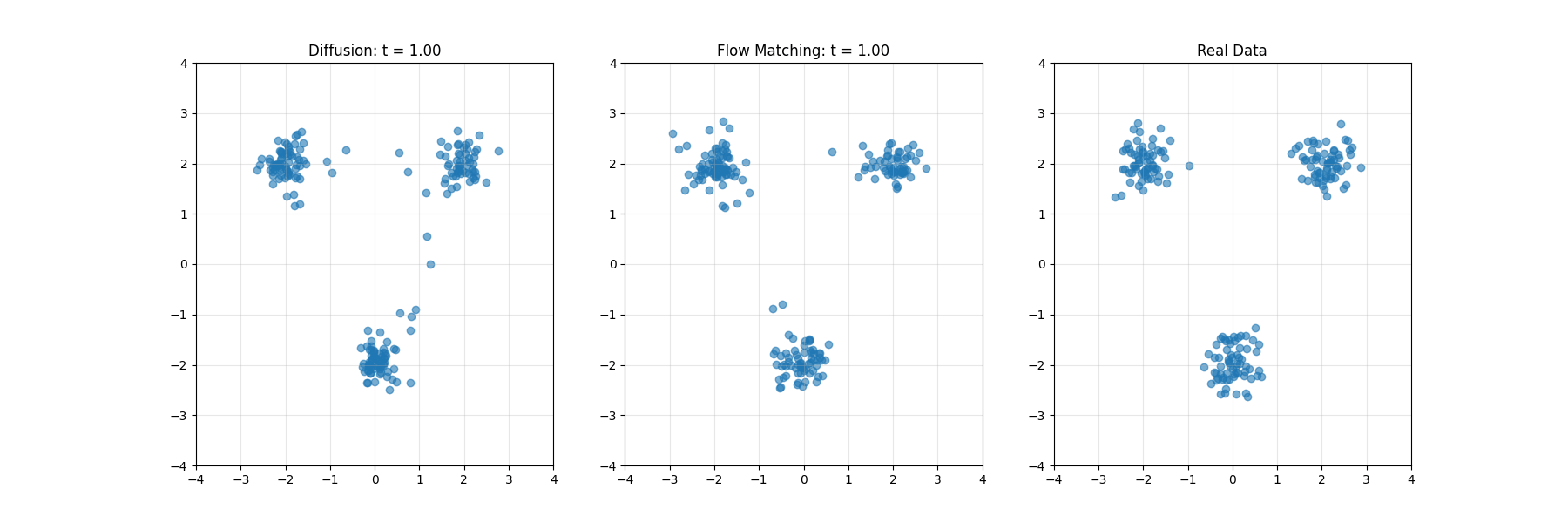
开发者学堂课程【高校精品课-华中科技大学 -智能媒体计算:镜头边界检测(上)】学习笔记,与课程紧密联系,让用户快速学习知识。
课程地址:https://developer.aliyun.com/learning/course/811/detail/15698
镜头边界检测(上)
内容介绍
一、前言
二、镜头变换
三、切变和渐变
四、镜头边界检测的一般流程
一、前言
我们继续讲解基于内容的视频分析,本小节讲解镜头变换检测。再讲解视频的分层组织时,已经了解到镜头是视频里最小的语义单元,它是指摄像机一次操作拍下连续的图像。
二、镜头变换
既然视频是由多个镜头拍摄组成的,那么在两个镜头之间一定是有变化的。那么镜头变换就是一段连续的视频图像序列变换到另一段连续视频图像序列。两个镜头拼接在一起,要检测边界点在哪。
镜头变换类型通常有两种,一种是切变( Abrupt Transition ),也叫突变,它是发生在两帧视频之间,相当于两个镜头直接衔接,即上一个镜头的位置和下一个镜头的首帧相连。另一种是渐变( Gradual Transition ),即从前面一个镜头逐渐过渡到下一个镜头里。这里面还有很多种类型,比如说淡入淡出、隐现、滑入等等。淡入就是后一帧慢慢的进来,淡出前面的镜头慢慢的消失。后面会有详细的示例讲解这些类型。

镜头边界检测通常叫做 SBD ( Shot Boundary Detection ),在上个世纪90年代到2010年,其实有很多人在做这个检测算法。截至目前,大家基本上攻克了切变检测,但是没有办法做到百分之百的渐变检测。
三、切变和渐变
1.切变
切变是指当前图像被下一幅图像快速代替,人的视觉上可以感觉到一个突然的变化。可以想一下,摄像机先拍我再拍你,这两个镜头的拼在一起,相邻的两帧一定有一个变化。在切变里,镜头变换发生在两帧之间,在帧间差别比较上会出现一个尖峰( Peak )。
计算相邻两帧的差别,在同一个镜头内部,所拍摄的内容是连续,两帧之间的差距是非常小的,而在切变相邻的两帧边界上,他们是不连续的,内容是不一样的。因此两帧之间的差别就要远远大于我们同一个镜头内部两帧的帧差。这实际上是检测切变的理论基础,即镜头内帧间的差别小,而变换的相邻两帧的差别大。
比如说(如下图),第三帧和第四帧这块发生了切片,它没有过度。

2.渐变
渐变是在帧间差别上没有一个可检测的尖峰存在,变换发生在多帧之间。容易与物体或摄像机运动相混淆。大家看个例子(如下图),第一帧图像和最后一帧图像,它的内容是发生了变化的,但这两个镜头之间是逐渐过渡的。

一个镜头内部相邻两帧差别小,而它在过渡时的差别也不够大,它没有一个明显的峰值。这时检测就需要想办法找到变化的规律,这样才能把渐变找到,检测峰值是没用的,因为他没有峰值出现。这时需要对多帧进行帧间差别计算,从而寻找它变化的规律。
3.其他类型
常见的10种镜头变换类型,有切变、淡入淡出、隐现、翻页、拉近、滑入、弹入弹出、上拉下拉、翻转、旋转等。前面两种已经有所了解,我们可以在 PPT 中设置各种放映模式,它所产生的特殊效果就相当于是镜头的变化效果。视频编辑工具里也可以做多种镜头变换模式。其实有上百种镜头组合变换模式,常见的是这些。视频镜头拼接的特殊效果是为了让我们的视觉上看上去更加炫酷,但实际上,当反向去从图像的角度检测时就困难了。
下图是淡入淡出的例子,左边是前面的图象慢慢地消失,后面的图像慢慢地出现,前一个镜头就过渡到后一个镜头了。右边是淡出的例子,前一个图像慢慢地消失,后一个出现。

下图是隐现和滑入。隐现是前一个镜头的内容慢慢地变得不清晰,而下一个镜头的内容凸显出来。后一个是滑入,可以从左到右滑,也可以从右向左滑。

四、镜头边界检测的一般流程
镜头边界检测的一般流程首先是视觉内容表示(特征提取)。无论是切变里找到峰值,还是渐变里找到变化的规律,都要想办法把视觉内容提取出来,这就是通常说的特征提取。
特征提取里要想办法度量它的不变性,即对同一个镜头内的帧内容的变化(物体或相机的运动)不敏感。摄像机对着我拍,手上有动作,同时也在慢慢地走动或是晃动,但是他在一个镜头内部,你的检测算法应该对这样的变化是有容忍度的。如果我一动,便判断是另外一个镜头,这说明判断的方法不够好。另外对于不同镜头的帧内容的变化要敏感。从一个摄像机换到另外一个镜头拍,还没检测出来,这也是失效的。镜头内部内容的变化不敏感,但是要对两个镜头之间的内容变化要敏感。这东西说起来容易,做起来就难了,尤其是检测变或者不变。
要如何区分一个镜头是在镜头内部还是在镜头外部呢?如果摄像机不动而我在动,我的动其实相对于整个的画面来讲是局部的,比如说ppt没有动而我在动,这说明他是一个镜头,如果 PPT 和我同时都变化了,可以考虑是另外一个镜头。用一个数学公式来表达的话(如图)。

其中 fn 是视频帧, Ψ 是特征提取函数, Zn 是提取的视频帧 fn 的特征。不同的变换算法实际上是 Ψ 不同,即用什么样的算法,就把它带到 Ψ 里面去。
然后是连续信号的构造,即相似性度量。第一步计算连续两帧特征之间的距离,构建连续信号。相邻两帧求差别,可根据以下公式计算(如图),其中 K 为特征数量, p 为 Lp-norm 范数。

如此便可以度量出是镜头内部还是外部,看这两条曲线(如图)。

左图突然出现了一个峰值,这说明是它一个切变,这个峰值前面的水平波动是一个镜头内部,然后转换到另外一个镜头内部时,它又变得很平滑了,这就是切变检测的事例。
右图曲线没有一个明显的峰值,而是逐渐增大,然后逐渐减小,这说明有一个渐变的规律,这就是渐变检测,这是一般性的。
然后是连续信号分类,即镜头边界识别,可以通过预先设定的阈值对信号进行分类。如果镜头内部帧之间的距离为常数并且接近于0或小于特定的阈值,说明是它在一个镜头内部,而切变发生在两帧之间,帧间距离接近于1,而渐变在多帧之间逐渐变化,取值在0和1之间,不同的渐变它的曲线波形式是不一样。