
3.2 数据准备
import tensorflow as tf print('Tensorflow Version: {}'.format(tf.__version__)) import pandas as pd import numpy as np import matplotlib.pyplot as plt %matplotlib inline #图像,标签,测试图像与标签 (train_image, train_lable), (test_image, test_label) = tf.keras.datasets.fashion_mnist.load_data() print("train_image shappe:{}\ntest_image shape:{}".format(train_image.shape,test_image.shape)) plt.imshow(train_image[0]) plt.axis("off") plt.show() #归一化 train_image = train_image/255 test_image = test_image/255
Tensorflow Version: 2.0.0 train_image shappe:(60000, 28, 28) test_image shape:(10000, 28, 28)

3.3 建立模型并训练
model = tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=(28,28))) model.add(tf.keras.layers.Dense(128,activation="relu")) model.add(tf.keras.layers.Dense(10,activation="softmax")) model.summary() model.compile(optimizer = "adam",loss='sparse_categorical_crossentropy',metrics=['acc']) model.fit(train_image,train_lable,epochs=5)
Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten_2 (Flatten) (None, 784) 0 _________________________________________________________________ dense_4 (Dense) (None, 128) 100480 _________________________________________________________________ dense_5 (Dense) (None, 10) 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________ Train on 60000 samples Epoch 1/5 60000/60000 [==============================] - 8s 138us/sample - loss: 3.1367 - acc: 0.6865 Epoch 2/5 60000/60000 [==============================] - 8s 130us/sample - loss: 0.6911 - acc: 0.7243 Epoch 3/5 60000/60000 [==============================] - 7s 114us/sample - loss: 0.6168 - acc: 0.7527 Epoch 4/5 60000/60000 [==============================] - 8s 128us/sample - loss: 0.5736 - acc: 0.7814 Epoch 5/5 60000/60000 [==============================] - 7s 117us/sample - loss: 0.5319 - acc: 0.8114
#评价 model.evaluate(test_image, test_label)
10000/1 - 1s 69us/sample - loss: 0.3796 - acc: 0.8244 [0.5249296184539795, 0.8244]
3.5 采用one-hot编码方式训练
train_label_onehot = tf.keras.utils.to_categorical(train_lable) test_label_onehot = tf.keras.utils.to_categorical(test_label) model = tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28 model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(10, activation='softmax')) model.summary() model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='categorical_crossentropy', metrics=['acc'] ) model.fit(train_image, train_label_onehot, epochs=5)
Model: "sequential_3" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten_3 (Flatten) (None, 784) 0 _________________________________________________________________ dense_6 (Dense) (None, 128) 100480 _________________________________________________________________ dense_7 (Dense) (None, 10) 1290 ================================================================= Total params: 101,770 Trainable params: 101,770 Non-trainable params: 0 _________________________________________________________________ Train on 60000 samples Epoch 1/5 60000/60000 [==============================] - 9s 148us/sample - loss: 3.9736 - acc: 0.7085 Epoch 2/5 60000/60000 [==============================] - 7s 122us/sample - loss: 0.6800 - acc: 0.7587 Epoch 3/5 60000/60000 [==============================] - 8s 135us/sample - loss: 0.6008 - acc: 0.7850 Epoch 4/5 60000/60000 [==============================] - 7s 119us/sample - loss: 0.5508 - acc: 0.8023 Epoch 5/5 60000/60000 [==============================] - 8s 125us/sample - loss: 0.5175 - acc: 0.8154 <tensorflow.python.keras.callbacks.History at 0x2fe4bf91388>
#评价model.evaluate(test_image, test_label_onehot)
1s 72us/sample - loss: 0.3707 - acc: 0.8031
[0.5642493257284165, 0.8031]
3.6 多添加几层隐藏层
model = tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28 model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dense(10, activation='softmax')) model.summary()
Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= flatten_2 (Flatten) (None, 784) 0 _________________________________________________________________ dense_4 (Dense) (None, 128) 100480 _________________________________________________________________ dense_5 (Dense) (None, 128) 16512 _________________________________________________________________ dense_6 (Dense) (None, 128) 16512 _________________________________________________________________ dense_7 (Dense) (None, 10) 1290 ================================================================= Total params: 134,794 Trainable params: 134,794 Non-trainable params: 0 _________________________________________________________________
model.compile(optimizer="adam", loss='categorical_crossentropy', metrics=["acc"]) #加入验证集 history = model.fit(train_image,train_label_onehot,epochs=20,validation_data=(test_image,test_label_onehot)) plt.plot(history.epoch,history.history.get("acc"),label="train_acc") plt.plot(history.epoch,history.history.get("val_acc"),label="val_acc") plt.legend() plt.show()
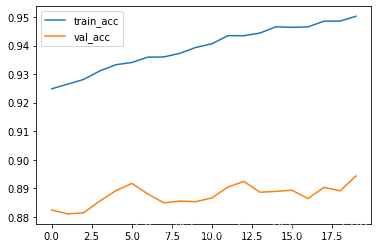
从图中,我们可训练集的准确率,在不断上升,而验证集的数据没有上升,甚至还有些下降,这是典型的过拟合状态,常见的,我们可以采用丢弃法或者减少层数来抑制过拟合状态。
3.7 添加dropout
model = tf.keras.Sequential() model.add(tf.keras.layers.Flatten(input_shape=(28,28))) # 28*28 model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dropout(0.5)) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dropout(0.5)) model.add(tf.keras.layers.Dense(128, activation='relu')) model.add(tf.keras.layers.Dropout(0.5)) model.add(tf.keras.layers.Dense(10, activation='softmax')) model.compile(optimizer="adam", loss='categorical_crossentropy', metrics=["acc"]) #加入验证集 history = model.fit(train_image,train_label_onehot,epochs=20,validation_data=(test_image,test_label_onehot)) plt.plot(history.epoch,history.history.get("acc"),label="train_acc") plt.plot(history.epoch,history.history.get("val_acc"),label="val_acc") plt.legend() plt.show()
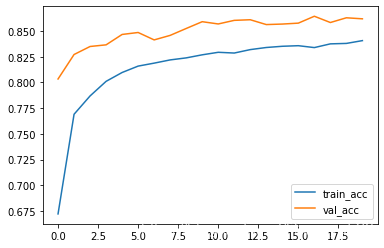
有上图我们可以发现,验证集的准确度比训练集的准确度高,所以dropout具有抑制过拟合的效果。


![[python] 深度学习基础------人工神经网络实现鸢尾花分类(五)](https://ucc.alicdn.com/pic/developer-ecology/83a278715a8942399b2b8c2f0ce4f301.png?x-oss-process=image/format,webp/resize,h_160,m_lfit)






![[python] 深度学习基础------人工神经网络实现鸢尾花分类(四)](https://ucc.alicdn.com/pic/developer-ecology/a129acdf45034b2cb6af13a112b5e3d5.png?x-oss-process=image/format,webp/resize,h_160,m_lfit)
![[python] 深度学习基础------人工神经网络实现鸢尾花分类(三)](https://ucc.alicdn.com/pic/developer-ecology/68e39afa1e2640e499385aacd880b9f8.png?x-oss-process=image/format,webp/resize,h_160,m_lfit)