
@[TOC](AttnGAN: Fine-Grained TexttoImage Generation with Attention(带有注意的生成对抗网络细化文本到图像生成))
这篇文章提出了一种注意力生成对抗网络(AttnGAN),它允许注意力驱动、多阶段细化细粒度文本到图像的生成,此外,还提出了一种深度注意多模态相似性模型来计算细粒度图像-文本匹配损失以训练生成器,进而生成更逼真的图像。
文章被2018年CVPR(IEEE Conference on Computer Vision and Pattern Recognition)会议收录。
论文地址: https://arxiv.org/pdf/1711.10485.pdf
代码地址: https://github.com/taoxugit/AttnGAN
本博客是精读这篇论文的报告,包含一些个人理解、知识拓展和总结。
一、摘要
在本文中,我们提出了一种注意力生成对抗网络(AttnGAN),它允许注意力驱动、多阶段细化细粒度文本到图像的生成。通过一种新的注意生成网络,AttnGAN可以通过关注自然语言描述中的相关词语,合成图像不同子区域的细粒度细节。此外,本文还提出了一种深度注意多模态相似性模型来计算细粒度图像-文本匹配损失以训练生成器。AttnGAN显著优于之前的最新水平,在CUB数据集上,最佳报告初始得分提高了14.14%,在更具挑战性的COCO数据集上,提高了170.25%。通过可视化AttnGAN的注意层,也可以进行详细的分析。这是第一次表明分层注意GAN能够自动选择单词级的条件来生成图像的不同部分。
二、关键词
Deep Learning, Generative Adversarial Nets, Image Synthesis, Computer Vision
三、为什么提出AttnGAN?
传统文本生成图像方法是将整个文本描述编码为全局句子向量,作为基于GAN的图像生成的条件,这种方法在全局句子向量上调节GAN,缺乏单词级的重要细粒度信息。
四、主要原理
主要原理跟StackGAN++差不多,也是多阶段图像生成,但是在其中引入注意力机制。AttnGAN主要是以GAN、CNN、Decnn、LSTM、Attention等机制模块组成的一个复杂网络,模型最简单的模型就是LSTM+CNN,做的事情就是:
- 将文本embedding得到word features和sentence features(利用到了LSTM);
- 利用sentence features生成一个低分辨率的图像(这一步与stackGAN差不多);
- 在低分辨率的图像上进一步加入word features和sentence features来生成更高分辨率的图像。
网络由三大模块组成:LSTM网络,生成器网络、判别器网络。
4.1、两大核心组成
AttnGAN创新主要在于两大组成部分:注意力生成网络和DAMSM
注意力生成网络:生成网络中的引入的注意机制使AttnGAN能够在单词的水平上实现单词与图片中的某个子区域的映射,自动选择字级条件以生成图像的不同子区域。
DAMSM:能够计算细粒度文本图像匹配损失,其仅应用于最后一个生成器的输出,有利于生成更高质量的图片。
4.2 、损失函数
最终设计模型的损失函数为:
L=LG+λLDAMSM, where LG=i=0∑m−1LGi
其中,λ是平衡因子,G的损失函数LG为:
LGi=unconditional loss −21Ex^i∼pGi[log(Di(x^i)]conditional loss −21Ex^i∼pGi[log(Di(x^i,eˉ)],
D的损失函数LD为:
LDi=unconditional loss −21Exi∼pdata i[logDi(xi)]−21Ex^i∼pGi[log(1−Di(x^i)]+conditional loss −21Exi∼pdata i[logDi(xi,eˉ)]−21Ex^i∼pGi[log(1−Di(x^i,eˉ)]
可以看出,总损失的第一项LG,原理与StackGAN中的无条件+有条件结构相似,无条件损失确定图像是真实的还是假的,条件损失确定图像和句子是否相符。
没看StackGAN++可以点击->:Text to image论文精读 StackGAN++
而损失函数的第二项LDAMSM是由DAMSM计算的字符级细粒度图像-文本匹配损失,这部分在本博文的第七节中介绍。
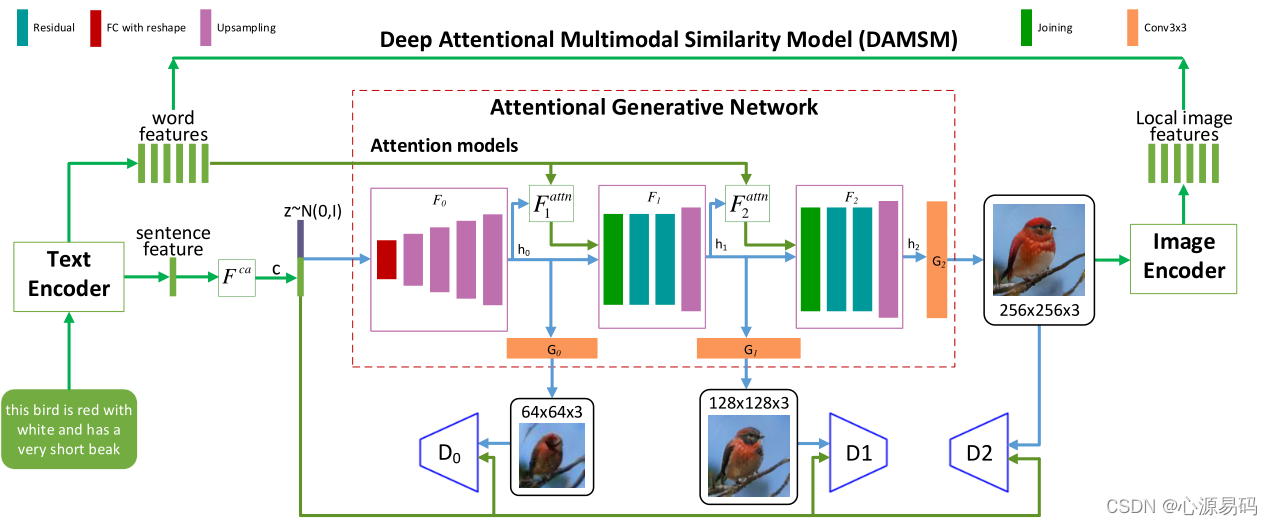
五、框架分析
 在这里插入图片描述
在这里插入图片描述
整个模型分三大块:
- 最左边文本编码器(LSTM)+最右边的图像编码器组合
文本编码器利用注意力机制对文本进行编码,输出sentence feature和word feature,其中sentence feature:取LSTM最后一个状态的输出,作用是当作生成器的控制信息;word feature:取中间隐藏状态的输出,用来确定图片与句子的一致性。图像编码器采用卷积神经网络(CNN)将图像映射到语义向量。 - 中间橘色框注意力生成网络,生成器接收的是sentence feature,生成具有句子特征的图片,从第二个生成器开始加入注意力机制,注意力机制接收的是生成器输出的h0矩阵以及word feature矩阵,输出是一个矩阵作为下一个生成器的输入。每个生成器由上采样、残差网络、全连接、卷积组成。
- 下方的判别器,输入是sentence feature和该阶段生成器生成的图片,判断图片与句子的相符性。
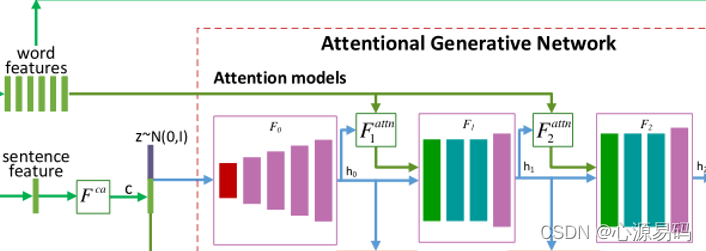
六、生成网络中的注意力机制
6.1、生成网络注意力框架
 在这里插入图片描述
在这里插入图片描述
F^attn^、F^ca^、Fi、Gi都是神经网络模型
F_i^attn^是第i阶段的注意力模型,F^ca^是条件增强模块,Conditioning
Augmentation其将句子向量e^-^转换为条件向量) ,z是随机噪声,e是句子向量的矩阵,e^-^表示全局句子向量
6.2、实现细节
2.1、第一步
 在这里插入图片描述
在这里插入图片描述
编码后的F^ca^ 通过F0, h0=F0 (z,F^ca^(e^-^ )) ,F0通过一个FC层和若干上采样层将输入的向量转换成指定维数。
hi=Fi(hi−1,Fiattn(e,hi−1)) for i=1,2,…,m−1Fattn(e,h)=(c0,c1,…,cN−1)∈RD^×N
其中,Fi^attn^的输入有两个,维数为D×T的单词特征e和维数为D^-^×N的上一隐藏层中的图像特征h,h的每一列是图像每个子区域的特征向量。Fi^attn^输出为c,c_i表示为第i个子区域的单词上下文向量。
6.2、第二步
对输入图片的每一部分,匹配最相关的单词向量来约束其生成,增加图像的细粒度细节。匹配图像子区域和最相关的单词公式如下:
cj=i=0∑T−1βj,iei′, where βj,i=∑k=0T−1exp(sj,k′)exp(sj,i′)
其中sj,i′=hjTei′
而β(i,j)表示 第i个单词对生成图像的第j个区域的重要程度。
6.3、第三步
通过将图像特征和相应的单词上下文特征结合起来生成图像,将生成的图像和sentence feature输入到D中训练。
 在这里插入图片描述
在这里插入图片描述
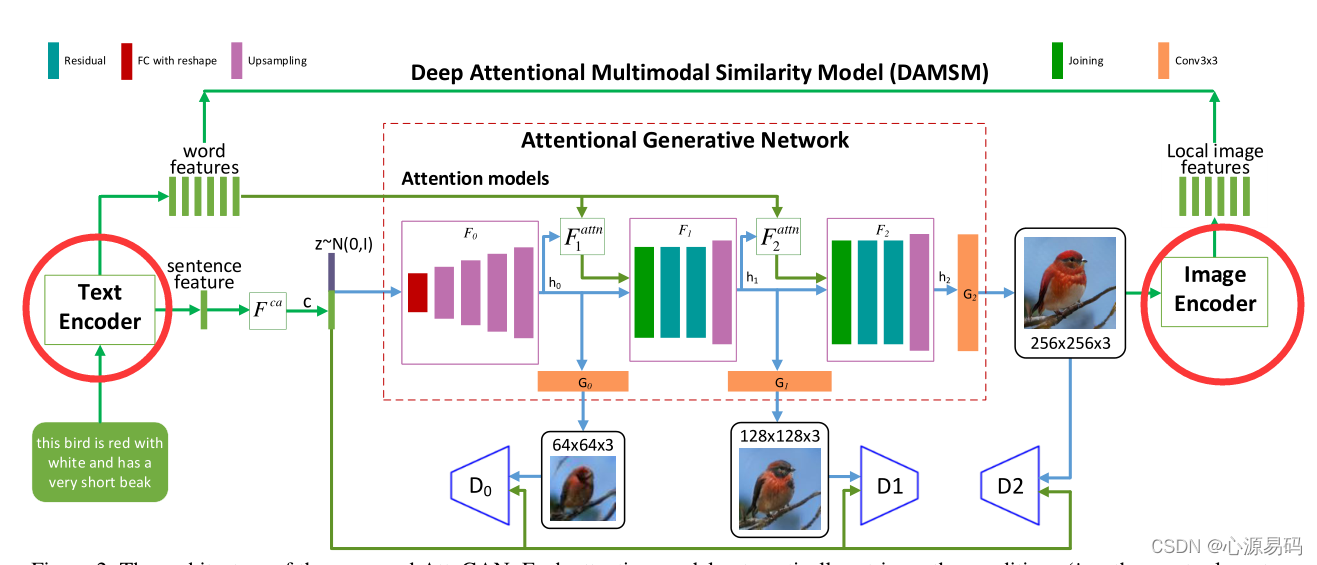
七、DAMSM (Deep Attentional Multimodal Similarity Model)
7.1、DAMSM框架
 在这里插入图片描述
在这里插入图片描述
DAMSM主要有两个神经网络,文本编码器和图像编码器。其将句子的图像和单词的子区域映射到一个公共语义空间,从而在单词级别测量图像-文本相似度,以计算图像生成的细粒度损失。
文本编码器:采用双向长短期记忆网络(LSTM)
图像编码器:采用卷积神经网络(CNN),将图像映射到语义向量
7.2、实现细节
7.2、第一步
根据图像和文本之间的注意模型来衡量图像-句子对的匹配程度,首先计算相似矩阵:
s=eTv
其中,s∈R^(T*289)^。s_ij描述的是文本中第i个单词和图片的第j个区域的点积相似性。v是图像的特征向量,e是单词的特征向量。
将其归一化:
sˉi,j=∑k=0T−1exp(sk,j)exp(si,j)
7.2、第二步
建立一个注意模型来计算每个单词的区域上下文向量:
ci=j=0∑288αjvj, where αj=∑k=0288exp(γ1sˉi,k)exp(γ1sˉi,j)
其中ci是与句子第i个单词相关的图像子区域向量表示,其中γ1是一个因素,表示对图像相关子区域特征的关注度。
7.3、第三步
应用余弦相似度定义计算第i个单词与图片的相关性:
R(ci,ei)=(ciTei)/(∥ci∥∥ei∥)
进而得出整个图像与整个文本描述之间的注意力机制图像-文本匹配:
R(Q,D)=log(i=1∑T−1exp(γ2R(ci,ei)))γ21
7.4、损失函数
对于一个批度文本图片对{[Qi,Di]}Mi=1,有一个后验概率:
P(Di∣Qi)=∑j=1Mexp(γ3R(Qi,Dj))exp(γ3R(Qi,Di))
将后验概率引入图像与其相应文本描述匹配的负对数损失函数:
L1w=−i=1∑MlogP(Di∣Qi),L2w=−i=1∑MlogP(Qi∣Di)
以相同方法得到L1s,L2s
最终可以得出DAMSM的损失函数为:
LDAMSM=L1w+L2w+L1s+L2s
八、实验
实验数据集:CUB、COCO
定量标准:IS、R-precision
实验效果:
 在这里插入图片描述
在这里插入图片描述
 在这里插入图片描述
在这里插入图片描述 在这里插入图片描述
在这里插入图片描述
九、实验复现
十、相关阅读
下一篇:论文精读 DM-GAN: Dynamic Memory Generative Adversarial Networks for t2i 用于文本图像合成的动态记忆生成对抗网络

