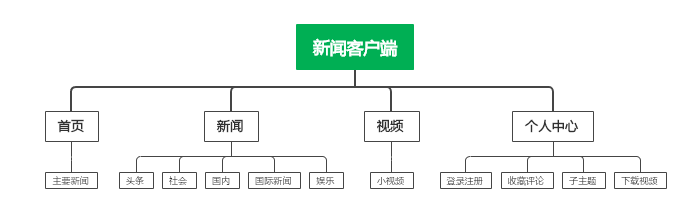
暂时未有相关云产品技术能力~
搞笑前端工程师
拜占庭将军问题,一个由Leslie Lamport于1982年提出的经典分布式系统理论问题,是现代加密货币与区块链技术背后的哲学基础。这一理论模型不仅深刻地影响了计算机科学领域,还成为了构建去中心化信任体系的关键灵感来源。本文将深入剖析拜占庭将军问题的本质、解决方案及其对区块链共识机制的深远影响,为读者揭示这一抽象理论的现实应用价值。
在区块链技术的宏伟蓝图中,Proof of Work(工作量证明,简称PoW)算法扮演着基石的角色。自比特币白皮书发布以来,PoW已成为确保去中心化网络安全、维护数据完整性的关键机制。本文将深入探讨PoW的工作原理、优势、挑战以及其对区块链生态系统的影响,力求为读者提供一个全面而深入的理解。
记账,作为人类文明进步的重要标志之一,其技术与方法的演变,见证了经济、社会乃至文化的深刻变迁。从最原始的实物记录到今天的数字账本——区块链,每一阶段的革新都推动着交易透明度、安全性与效率的大幅提升。本文将穿越千年历史长河,探索记账科技的演进之路。
在数字化浪潮席卷全球的今天,程序员作为构建未来世界的“魔法师”,其职业素养不仅关乎代码的优美与效率,更深层次地体现在对技术的持续追求、团队合作的能力、解决问题的创新思维以及对社会责任的担当上。本文将探讨我认为对于程序员最为重要的几种职业素养,并结合实际案例,分享我在职业生涯中的体会与思考。
在机器学习的广阔领域中,集成学习方法因其卓越的预测性能和泛化能力而备受瞩目。其中,XGBoost(Extreme Gradient Boosting)作为梯度提升决策树算法的杰出代表,自其诞生以来,便迅速成为数据科学竞赛和工业界应用中的明星算法。本文旨在深入浅出地介绍XGBoost的核心原理、技术优势、实践应用,并探讨其在模型调优与解释性方面的考量,为读者提供一个全面且深入的理解框架。
GBDT,全称为Gradient Boosting Decision Tree,即梯度提升决策树,是机器学习领域中一种高效且强大的集成学习方法。它通过迭代地添加决策树以逐步降低预测误差,从而在各种任务中,尤其是回归和分类问题上表现出色。本文将深入浅出地介绍GBDT的基本原理、算法流程、关键参数调整策略以及其在实际应用中的表现与优化技巧。
在机器学习的广阔领域中,朴素贝叶斯分类器以其实现简单、计算高效和解释性强等特点,成为了一颗璀璨的明星。尽管名字中带有“朴素”二字,它在文本分类、垃圾邮件过滤、情感分析等多个领域展现出了不凡的效果。本文将深入浅出地介绍朴素贝叶斯的基本原理、数学推导、优缺点以及实际应用案例,旨在为读者构建一个全面而深刻的理解框架。
逻辑回归(Logistic Regression)是一种广泛应用于分类问题的统计学方法,尽管其名称中含有“回归”二字,但它实际上是一种用于解决二分类或多分类问题的线性模型。逻辑回归通过使用逻辑函数(通常为sigmoid函数)将线性模型的输出映射到概率空间,从而预测某个事件发生的概率。本文将深入探讨逻辑回归的理论基础、模型构建、损失函数、优化算法以及实际应用案例,并简要介绍其在机器学习领域的地位和局限性。
在机器学习的广阔天地中,集成学习方法因其卓越的预测能力和泛化性能而备受青睐。其中,随机森林(Random Forest)作为集成学习的一个重要分支,凭借其简单、高效且易于实现的特性,在分类和回归任务中展现了非凡的表现。本文将深入探讨随机森林的基本原理、核心构建模块、关键参数调优以及在实际应用中的策略与案例分析,旨在为读者提供一个全面而深入的理解。
在机器学习领域,集成学习是一种通过结合多个弱模型以构建更强大预测模型的技术。Adaptive Boosting,简称Adaboost,是集成学习中的一种经典算法,由Yoav Freund和Robert Schapire于1996年提出。Adaboost通过迭代方式,自适应地调整数据样本的权重,使得每个后续的弱学习器更加关注前序学习器表现不佳的样本,以此逐步提高整体预测性能。本文将深入探讨Adaboost的工作原理、算法流程、关键特性、优势及应用场景,并简要介绍其实现步骤。
K-近邻算法(K-Nearest Neighbors, KNN)是一种基于实例的学习方法,属于监督学习范畴。它的工作原理简单直观:给定一个训练数据集,对新的输入实例,KNN算法通过计算其与训练集中每个实例的距离,找出距离最近的K个邻居,然后根据这些邻居的类别(对于分类任务)或值(对于回归任务)来预测新实例的类别或值。KNN因其简单高效和无需训练过程的特点,在众多领域中得到广泛应用,如模式识别、推荐系统、图像分类等。
决策树作为机器学习中的一种基础且强大的算法,因其易于理解和实现、能够处理分类和回归任务的特性而广受欢迎。本文旨在深入浅出地介绍决策树算法的基本原理,并通过Python编程语言实践其应用,帮助读者掌握如何利用Python构建及优化决策树模型。本文预计分为以下几个部分:决策树基础理论、Python中实现决策树的库介绍、实战案例分析、模型评估与调优方法,以及决策树算法的局限性与未来展望。
在人工智能领域,大模型(Large Language Models, LLMs)凭借其强大的语言理解和生成能力,正逐步成为推动技术革新和社会进步的关键力量。随着GPT-3、BERT、Turing-NLG等知名模型的面世,大模型的开放与封闭策略也成为行业内外热议的话题。本文旨在探讨开源与闭源大模型各自的优劣,并基于当前技术发展、市场趋势及社会需求,分析两者在未来的发展前景。
Debian,作为Linux世界中一个历史悠久且广受尊敬的发行版,以其稳定性和对自由软件原则的坚持而著称。对于运维开发工程师而言,熟练掌握Debian系统的常用命令是日常工作的基石。本文旨在为Debian系统的新老用户提供一份全面且实用的命令指南,帮助大家高效地管理、配置和维护Debian系统。本文将涵盖文件操作、包管理、系统监控、网络配置、用户管理等关键领域,力求在2500字左右的篇幅内,条理清晰地介绍每个命令的用途、基本语法及实用示例。
本文探讨了IT行业的现状与未来趋势,云计算已成为企业首选,大数据与AI改变生活,物联网与5G开启新时代,而区块链则革新信任机制。同时,行业面临数据安全、技术伦理、数字鸿沟等挑战。未来,边缘计算、AI泛在化、绿色IT和量子计算将成为发展重点,IT行业将持续重塑人类社会。
Vue.js,由尤雨溪于2014年创建,是一个轻量级的前端框架,因其简洁API、高效渲染和组件系统深受全球开发者喜爱。本文探讨Vue的核心理念、技术架构、开发实践及在现代Web开发中的应用。Vue遵循渐进式框架思想,提供声明式编程、组件化和响应式数据绑定。技术上,它采用双向数据绑定、虚拟DOM和生命周期钩子。开发实践中,Vue CLI和Vuex、Vue Router分别加速开发和管理状态、路由。Vue不仅适用于单页应用,还支持多页应用、移动开发和跨平台项目,拥有丰富的社区生态和插件。随着Vue 3的推出,Vue将持续创新并影响前端开发领域。
此文档是CentOS常用命令指南,涵盖文件操作、系统管理、网络配置、软件安装更新等方面。包括切换目录(`cd`)、查看目录(`ls`)、创建/删除目录(`mkdir`, `rmdir`, `rm`)、文件查看编辑(`cat`, `less`, `vi/vim`)、系统信息(`uname -a`, `hostname`, `top`)、用户权限管理(`useradd`, `passwd`, `sudo`, `chmod`, `chown`)、软件包管理(`yum`或`dnf`)、网络状态(`ip addr`, `ping`)、进程管理(`ps`, `kill`, `nohup`, `jobs`
本文探讨AI技术如何提升内容生产的效率与质量。通过自然语言处理(NLP)实现智能摘要、自动写作和语言风格优化;计算机视觉用于图像识别和智能设计,提升视频与图像内容生产;数据分析与预测帮助精准洞察受众需求和预测内容趋势;AI推荐系统实现个性化信息流,优化用户体验。尽管AI带来变革,但需结合人类创意与伦理监督,以促进内容产业健康发展。
提升前端开发效率的Chrome命令详解:快速打开DevTools(F12或Ctrl+Shift+I/Cmd+Opt+I)、Console中直接运行JS、使用$和$$选择元素、监控事件、模拟设备、计算样式覆盖、网络请求过滤、性能分析、Sources面板调试与编辑、命令行快捷方式如chrome://flags。掌握这些技巧,加速开发流程。
Google近日决定解散其Python研发团队,原因是寻求更低劳动力成本,可能转向其他国家招聘。此举可能源于美国程序员薪资高昂,相比之下,中国工程师薪资更低且效率更高。谷歌CEO Sundar Pichai已将部分团队迁移至印度。这一决策引发对公司长期可持续性和人才保留问题的讨论,暗示谷歌正面临挑战。
本文解析了AI作画算法的原理,介绍了基于机器学习和深度学习的CNNs及GANs在艺术创作中的应用。从数据预处理到模型训练、优化,再到风格迁移、图像合成等实际应用,阐述了AI如何生成艺术作品。同时,文章指出未来发展中面临的版权、伦理等问题,强调理解这些算法对于探索艺术新境地的重要性。
**PostCSS** 是一个JavaScript库,用于转换CSS,通过插件系统解析、优化代码,确保兼容性和效率。它提供插件化架构、向后/向前兼容性、代码质量提升和与其他工具链集成。PostCSS工作原理包括解析CSS成抽象语法树,插件遍历并转换AST,最后生成增强版CSS。主要功能包括Autoprefixer(自动添加浏览器前缀)、CSS变量、CSS Modules、Linting、预处理器支持等。在实际项目中,PostCSS可通过配置文件集成到Webpack等构建工具中,持续优化工作流,助力现代前端开发。
OneFlow是阿里云开发的高性能开源深度学习框架,专注于大规模分布式训练。它采用数据流图执行引擎,支持动态图与静态图混合编程,提供无缝分布式训练及多种并行策略。OneFlow与PyTorch、TensorFlow等主流框架兼容,且在GPU优化和通信效率上具有优势。适用于NLP、CV等多个领域,其灵活高效的特点使其在深度学习领域中展现出强劲竞争力。
Fiddler是一款强大的Web调试工具,适用于Windows、macOS和Linux,用于捕获、记录和分析HTTP/HTTPS流量。本文详细介绍了Fiddler的安装步骤,包括下载、安装和配置,特别是信任根证书和代理设置。在使用方面,讲解了如何启动/停止捕获流量、查看和管理会话,以及重发请求、编辑请求/响应和清除会话。此外,还探讨了进阶功能,如自定义过滤规则、使用AutoResponder模拟服务器响应、性能分析和统计,以及插件扩展和脚本编写。Fiddler是学习HTTP协议和解决Web问题的得力工具。
该文章源自React核心开发者Dan的博客《再见,清洁代码》。文中讲述了一个场景,作者的同事完成了一个功能,虽然代码运行正常但显得冗余。作者试图通过重构消除重复,使代码更整洁,但第二天被上司要求恢复原状。作者后来认识到,追求“清洁代码”是成长过程中的一个阶段,虽然抽象和消除重复有其价值,但应考虑代码的可维护性和团队协作。真正的目标不是绝对的“清洁”,而是适应变化和良好沟通。
本文介绍了6种常见分类算法:逻辑回归、朴素贝叶斯、决策树、支持向量机、K近邻和神经网络。逻辑回归适用于线性问题,朴素贝叶斯在高维稀疏数据中有效,决策树适合规则性任务,SVM擅长小样本非线性问题,KNN对大规模数据效率低,神经网络能处理复杂任务。选择算法时需考虑数据特性、任务需求和计算资源。
本文探讨了人工智能领域的创业机遇与挑战。AI技术的快速发展,如深度学习、自然语言处理等,已广泛应用于医疗、金融、制造等行业。未来创业机会包括AI基础设施、垂直行业解决方案、伦理安全领域及AI与其他技术的融合创新。然而,创业者需面对技术壁垒、数据获取、市场接受度、商业模式创新及政策伦理挑战。要在AI领域成功创业,需紧跟技术趋势,深挖行业需求,创新商业模式,并妥善应对各种挑战。
通过命令行调用AI大模型以提高效率,文章介绍了一个使用前端npm的方法。首先创建npm包项目,初始化配置,然后编写`constant.js`、`kiwi.js`和`main.js`三个文件,分别存放API密钥、调用接口和主逻辑。在`kiwi.js`中使用axios与大模型API交互,`main.js`接收命令行参数并输出结果。通过修改`package.json`设置入口文件,并使用`npm link`全局安装,实现命令行调用,如`moon 你好`。
**npm命令详解:**了解基本概念和安装后,通过`npm init`生成`package.json`。安装包用`install [package]`,加`--save`或`--save-dev`管理依赖。移除包用`uninstall`,更新用`update`,全局安装加`-g`。搜索包用`search`,查看依赖用`list`,检查过时包用`outdated`,审计安全用`audit`。版本控制用`version`,发布包用`publish`。掌握这些命令能提升开发效率。探索更多npm特性,加强项目管理和协作。
**ECMAScript是JavaScript的规范,定义语言核心如语法和数据类型;JavaScript是其实现,浏览器中的实现包括额外的API和库。两者关系:蓝图与建筑,规范与实现。了解此区分有助于精准开发。**
本文集合一些React的原理面试题,方便读者以后面试查漏补缺。作者给出自认为可以让面试官满意的简易答案,如果想要了解更深刻,可以点击链接查看对应的详细博文。在此对链接中的博文作者非常感谢🙏。
最近看一些论坛上,独立开发越来越火爆🔥。 例如 1. xxx网站SEO做的好,靠网站广告月入3000dollar 2. 开发了xxx软件,上架 Apple Store,睡后收入可以不用上班等~
前端开发自互联网诞生以来,伴随着浏览器技术和网络标准的演进,经历了从静态页面到动态交互应用的深刻变革。本文旨在梳理前端开发的关键节点和发展历程,展现其在用户体验、技术革新和工程实践等方面的显著进步。
本文集合一些React的Hooks面试题,方便读者以后面试查漏补缺。作者给出自认为可以让面试官满意的简易答案,如果想要了解更深刻,可以点击链接查看对应的详细博文。在此对链接中的博文作者非常感谢🙏。
引入 浅拷贝和深拷贝应该是面试时非常常见的问题了,为了能将这两者说清楚,于是打算用两篇文章分别解释下深浅拷贝。 PS: 我第一次听到拷贝这个词,有种莫名的熟悉感,感觉跟某个英文很相似,后来发现确实Copy的音译,感觉这翻译还是蛮有意思的
ElementUI 是基于 Vue 2.0 的桌面端组件库,提供丰富的 UI 组件,助力快速构建美观应用。本文为初学者提供快速入门教程:确保安装 Node.js 和 Vue CLI,使用 Vue CLI 创建项目,通过 `npm` 或 `yarn` 安装 ElementUI。在 `main.js` 引入并使用,直接在组件中使用按钮、表单、表格和对话框等组件。此外,还介绍了自定义主题的方法。深入了解官方文档和社区资源,提升开发效率。开始愉快地使用 ElementUI 吧!
防抖: 首先它是常见的性能优化技术,主要用于处理频繁触发的浏览器事件,如窗口大小变化、滚动事件、输入框内容改变等。在用户连续快速地触发同一事件时,防抖机制会确保相关回调函数在一个时间间隔内只会被执行一次。
上篇我们讲了防抖,这篇我们就谈谈防抖的好兄弟 -- 节流。这里在老生常谈般的提一下他们两者之间的区别,顺带给读者巩固下。
AIGC技术现正快速发展,涉及文本、图像、音频和视频生成。GPT-3等模型已能生成连贯文本,GANs创造高质量图像,WaveNet合成逼真音频。尽管面临质量控制、原创性、可解释性和安全性的挑战,未来趋势将聚焦更高生成质量、多模态内容、个性化定制、增强可解释性和透明度,以及关注安全性和伦理问题。AIGC将在多领域创造更多可能性。
本文详细介绍了Chrome插件的开发,从基础概念到实战技巧。首先,解释了插件的结构,包括manifest.json、背景脚本、内容脚本和UI界面。接着,阐述了生命周期、通信机制以及开发步骤,包括创建项目结构、编写manifest.json、开发脚本和UI,以及测试与调试。通过一个显示当前页面URL的插件实例,展示了具体实现过程。最后,讲解了如何在Chrome Web Store发布和分发插件。Chrome插件开发为开发者提供了创造个性化体验的平台,本文旨在引导读者入门并深入实践。
什么是NextJs 首先查看NextJs官网给出了如下的解释(官网地址: nextjs.org): The React Framework for the Web. Used by some of the world's largest companies, Next.js enables you to create high-quality web applications with the power of React components 总结就是用的公司多,框架水平NB,经住了很多项目的磨练。然后官网就给出了NextJs学习教程,做一个Dashboard网站。 如果要看这个教程的话:可
PyTorch是Facebook推出的深度学习库,以其动态图、直观API和强大的社区支持深受青睐。与TensorFlow相比,PyTorch的动态图机制简化了模型开发和调试,API设计更简洁。核心特性包括张量操作、自动微分、模块化编程、数据加载与预处理、优化器和损失函数。广泛应用于CV、NLP、推荐系统和强化学习,支持模型部署和推理。丰富的开源库(如torchvision、torchaudio、torchtext)和社区资源(如PyTorch Lightning、PyTorch Hub)为用户提供了全栈式解决方案。
2023年图灵奖得主Avi Wigderson,普林斯顿大学数学教授,以其在计算复杂性理论、密码学和计算数论的贡献获奖。Wigderson的工作深化了对计算问题难度的理解,推动了交互式证明系统和零知识证明的发展,影响了量子计算和密码学实践。他倡导数学与计算科学融合,促进计算思维教育,激励新一代科研人才应对计算挑战。
这章主要讲的是数组的排序篇,我们知道面试的时候,数组的排序是经常出现的题目。所以这块还是有必要进行一下讲解的。笔者观察了下前端这块的常用算法排序题,大概可以分为如下
续借上文,这篇文章主要讲的是数组原型链相关的考题,有些人可能会纳闷,数组和原型链之间有什么关系呢?我们日常使用的数组forEach,map等都是建立在原型链之上的。举个🌰,如我有一个数组const arr = [1,2,3]我想要调用arr.sum方法对arr数组的值进行求和,该如何做呢?我们知道数组没有sum函数,于是我们需要在数组的原型上定义这个函数,才能方便我们调用,具体代码如下。接下来我们就是采用这种方式去实现一些数组常用的方法。
兄弟们,这不情人节快要到了,我该送女朋友什么🎁呢?哦,对了,差点忘了,我好像没有女朋友。 不过这不影响我们要过这个节日,我们可以学习技术。举个简单的🌰: 比如说,今天我们学习了如何画一颗炫酷的💗,以后找到了女朋友忘准备礼物了,是不是可以用这个救救场,🐶。
该专题主要是讲解我们在面试的时候碰到一些JS的手写题, 确实这种手写题还是比较恶心的。有些时候好不容易把题目写出来了,突然面试官冷不丁来一句有没有更优的解法,直接让我们僵在原地。为了解决兄弟们的这些困扰,这个专题于是就诞生啦。我们会将一些常见的不是最优解的答案作为对比,方便大家更好理解。
所以,你已经了解了前六条规则。你成功地通过了初步的工作邀约交谈,也从其他公司获得了竞争性的工作机会,现在是时候真正进入谈判阶段了。 当然,这也是许多人容易出现问题的环节。
还在为写文章时找不到标题图片而困扰吗?举个例子,CSDN的博客文章如果你不给他图片的话,那么它会按照一些默认的标签图片作为你的文章封面,例如下面这样。
最近我看到一篇关于谈判Offer的文章,个人认为他写的非常好,在很多方面给我了不一样的思考,例如找工作是一种价值交换,如何能够在与HR谈判中得到更高的薪资等,于是我将其翻译如下,希望也能带给你一些收获。兄弟们,学会这些,避免如下惨剧。
 发表了文章
2024-06-11
发表了文章
2024-06-11
发表了文章
2024-06-11
发表了文章
2024-06-11
发表了文章
2024-06-10
发表了文章
2024-06-10
发表了文章
2024-06-10
发表了文章
2024-06-04
发表了文章
2024-05-31
发表了文章
2024-05-31
发表了文章
2024-05-31
发表了文章
2024-05-29
发表了文章
2024-05-29
发表了文章
2024-05-29
发表了文章
2024-05-22
发表了文章
2024-05-22
发表了文章
2024-05-22
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-06-11
发表了文章
2024-06-11
发表了文章
2024-06-11
发表了文章
2024-06-11
发表了文章
2024-06-10
发表了文章
2024-06-10
发表了文章
2024-06-10
发表了文章
2024-06-04
发表了文章
2024-05-31
发表了文章
2024-05-31
发表了文章
2024-05-31
发表了文章
2024-05-29
发表了文章
2024-05-29
发表了文章
2024-05-29
发表了文章
2024-05-22
发表了文章
2024-05-22
发表了文章
2024-05-22
发表了文章
2024-05-15
发表了文章
2024-05-15
发表了文章
2024-05-15

 回答了问题
2024-05-19
回答了问题
2024-05-19
回答了问题
2024-05-18
回答了问题
2024-05-18
回答了问题
2024-05-16
回答了问题
2024-05-16
回答了问题
2024-05-15
回答了问题
2024-05-15
回答了问题
2024-05-15
回答了问题
2024-05-15
回答了问题
2024-05-12
回答了问题
2024-05-12
回答了问题
2024-05-10
回答了问题
2024-05-10
回答了问题
2024-05-10
回答了问题
2024-05-10
回答了问题
2024-05-09
回答了问题
2024-05-09
回答了问题
2024-05-08
回答了问题
2024-05-08
回答了问题
2024-05-19
回答了问题
2024-05-19
回答了问题
2024-05-18
回答了问题
2024-05-18
回答了问题
2024-05-16
回答了问题
2024-05-16
回答了问题
2024-05-15
回答了问题
2024-05-15
回答了问题
2024-05-15
回答了问题
2024-05-15
回答了问题
2024-05-12
回答了问题
2024-05-12
回答了问题
2024-05-10
回答了问题
2024-05-10
回答了问题
2024-05-10
回答了问题
2024-05-10
回答了问题
2024-05-09
回答了问题
2024-05-09
回答了问题
2024-05-08
回答了问题
2024-05-08