

勋章









我关注的人








粉丝










技术能力
- Java
- C++
- C语言
- Python
- Shell
- Go
- Kotlin
- iOS开发
- Android开发
- 设计模式
暂时未有相关云产品技术能力~
北京阿里云ACE会长
-
发表了文章 2023-10-02
Next Sentence Prediction,NSP
Next Sentence Prediction(NSP) 是一种用于自然语言处理 (NLP) 的预测技术。
-
发表了文章 2023-10-01
ISV
ISV(独立软件供应商)是一种为其他公司或个人提供软件产品或服务的公司。ISV 通常专注于开发和销售特定的软件解决方案,以满足客户的需求。ISV 可以提供各种类型的软件,包括桌面应用程序、Web 应用程序、移动应用程序、游戏等。
-
发表了文章 2023-10-01
Masked Language Modeling,MLM
Masked Language Modeling(MLM)是一种预训练语言模型的方法,通过在输入文本中随机掩盖一些单词或标记,并要求模型预测这些掩盖的单词或标记。MLM 的主要目的是训练模型来学习上下文信息,以便在预测掩盖的单词或标记时提高准确性。
-
发表了文章 2023-09-30
数字孪生
数字孪生(Digital Twin)是一种数字模型,它可以模拟现实世界中的物体、设施、系统等的结构、行为和性能。数字孪生技术将物理世界与数字世界相结合,通过实时数据和历史数据,
-
发表了文章 2023-09-30
AI-Generated Metaverse, AIGM
AI-Generated Metaverse,简称 AIGM,是指由人工智能生成的元宇宙。元宇宙是一个虚拟的三维空间,由各种虚拟场景和物体组成,用户可以在其中自由地移动和交互。AIGM 则更进一步,利用人工智能技术自动生成元宇宙中的虚拟场景和物体,极大地丰富了元宇宙的内容,提高了用户体验。
-
发表了文章 2023-09-29
预期违背理论(expectancy violations theory)
预期违背理论(Expectancy Violations Theory)是由心理学家 John Bowlby 提出的,该理论认为人们在社交互动中会根据以往的经验和预期来判断他人的行为。当他人的行为与我们的预期相违背时,我们会产生一种心理上的不适感,这种不适感可能表现为惊讶、失望、愤怒等情绪。预期违背理论可以用来解释人们在社交互动中的情绪反应,以及为什么人们会对他人的行为产生不同的情感体验。
-
发表了文章 2023-09-29
准试验研究(Quasi-experiment)
准试验研究(Quasi-experiment)
-
发表了文章 2023-09-28
AIAM 模型
AIAM(Artificial Intelligence and Music)模型是一种基于深度学习的音乐生成模型。
-
发表了文章 2023-09-28
人机协同” (human-agent collaboration
人机协同(Human-Agent Collaboration,简称 HAC)是指人类与智能代理(如机器人、虚拟助手等)
-
发表了文章 2023-09-27
AIGM 框架
AIGM (Adaptive Image Generation and Manipulation) 是一个基于深度学习的图像生成和处理框架。它使用先进的生成对抗网络 (GAN) 和变分自编码器 (VAE) 技术,可以实现图像的自动生成、转换、编辑和增强等功能。
-
发表了文章 2023-09-27
MyEduChat 平台
MyEduChat 平台是一个在线教育平台,提供各种在线课程、学习资源和互动工具,帮助学生
-
发表了文章 2023-09-25
预期努力(effort expectancy)量表
预期努力(effort expectancy)量表是一种用于测量个体认为完成某个任务或目标所需的努力程度的自我评估工具。这个量表可以帮助个人或团队了解他们对某个任务的信心水平,以及完成任务所需的付出,从而为制定计划和决策提供依据。
-
发表了文章 2023-09-25
感知偶然性(perceived contingency,PC)量表。
感知偶然性(perceived contingency,PC)量表。感知偶然性(Perceived Contingency,PC)量表是一种用于评估个体对事件之间关系的认知程度的量表。
-
发表了文章 2023-09-25
感 知 拟 人 性 (Perceived Anthropomorphism, PA)量表。
感 知 拟 人 性 (Perceived Anthropomorphism,感知拟人性(Perceived Anthropomorphism,PA)量表是一种用于评估人们对于非人类事物 PA)量表。
-
发表了文章 2023-09-24
tts
TTS(Text-to-Speech,文本到语音)是一种将计算机上的文本转换为人类可听的语音输出的技术。这种技术可以帮助人们在无法阅读文本的环境(如驾车、视力障碍等)下接收信息,同时也可以用于语音助手、智能家居等场景中。
-
发表了文章 2023-09-24
opencv
OpenCV(Open Source Computer Vision Library,开源计算机视觉库)是一个开源的计算机视觉和机器学习软件库,它包含了许多图像处理、视频分析和计算机视觉方面的功能。OpenCV 的目的是为人工智能、
-
发表了文章 2023-09-23
ArcFace
ArcFace 是虹软公司开发的一款人脸识别 SDK,它具有高性能、高精度、高鲁棒性等特点,支持多种人脸检测、识别和跟踪技术,可用于多种场景,如手机解锁、身份认证、人脸支付等。
-
发表了文章 2023-09-23
语言模型的研发公司排行
全球范围内有很多公司在研发语言模型,以下是其中一些比较知名的公司和机构:
-
发表了文章 2023-09-22
poc Proof of Concept
Proof of Concept(简称 POC)是概念验证的意思。在软件开发领域,POC 通常用于验证某个想法或概念是否可行。它通常是一个小型项目或原型,可以通过实际操作来证明某个想法或技术的有效性。POC 可以帮助开发者在项目开始之前确定技术的可行性,减少开发过程中的风险。
-
发表了文章 2023-09-22
ai绘画的主要研发公司
全球范围内有很多公司在研发 AI 绘画技术,以下是其中一些比较知名的公司和机构:
-
发表了文章 2023-09-22
RTE
RTE(Real-Time Ethernet)是一种实时以太网技术,它允许在以太网网络中实现确定性的数据传输。RTE 通常用于工业自动化、控制和监控应用,要求在严苛的实时环境中传输数据。
-
发表了文章 2023-09-21
云服务的公司排行
云服务是一种基于互联网的计算方式,它通过提供共享计算资源、存储、应用程序和其他服务来满足企业和个人的需求。云服务公司排名可能因地区、服务范围、行业应用等因素而有所不同,以下是一些全球知名的云服务公司及其排名:
-
发表了文章 2023-09-20
PDS(Personal/Enterprise Data Storage)
PDS 是一款集数据存储、管理和智能分析于一体的云存储平台,适用于个人和企业用户。它提供了目录、文件管理功能,以及影像内容的分类打标、人脸聚类等智能分析功能,基于内容的智能搜索能力,用户体系以及第三方身份系统接入能力。用户可基于此开发一套面向企业或个人的网盘系统。PDS 还提供了一些官方应用,可与您的系统组合使用,简化您的开发。
-
发表了文章 2023-09-20
Serverless 应用引擎 SAE
Serverless 应用引擎 SAE(Serverless App Engine)是阿里云推出的一款支持 Serverless 架构的微服务应用开发、部署和管理的平台。SAE 提供了一系列通用能力,如服务注册与发现、环境隔离、配置管理、服务治理、限流降级、应用平滑上下线、服务鉴权等,帮助开发者低门槛地上云,按需使用、按量计费,节省闲置计算资源。
-
发表了文章 2023-09-19
kibana
Kibana是一种用于数据可视化和分析的开源工具,它是Elastic Stack(以前称为ELK Stack)的一部分,与Elasticsearch紧密集成。Kibana提供了一个直观的Web界面,使用户能够以交互方式探索、分析和呈现数据。它支持各种图表、图形和仪表板,帮助用户从数据中发现模式、趋势和见解。
-
发表了文章 2023-09-18
会话日志记录
会话日志记录是一种记录计算机程序或通讯工具(如 SecureCRT、Xshell 等)会话过程中的操作、消息和事件的功能。会话日志可以帮助用户回顾之前的操作,排查问题,分析系统行为等。以下是会话日志记录的使用方法:
-
发表了文章 2023-09-18
开发小程序
HTML、CSS 和 JavaScript 这三种前端技术。然后学习微信小程序开发相关的技术和框架。以下是一个详细的学习路径:
-
发表了文章 2023-09-17
Tablestore
Tablestore(表格存储)是阿里云提供的一种云原生、高性能、可扩展的 NoSQL 数据库服务。它支持海量数据存储和快速查询,适用于大数据分析、数据仓库、日志收集等场景。
-
发表了文章 2023-09-16
Softmax 分类器
机器学习中的 Softmax 分类器是一种常用的多分类模型,它将逻辑回归(Logistic Regression)推广到多分类问题中。在 Softmax 分类器中,我们使用一个二维平面(或多维空间中的超平面)来将不同类别的数据分开。这个超平面由一个线性函数决定,该线性函数可以表示为:y = w1 * x1 + w2 * x2 +... + wn * xn 其中,y 是输出变量(通常为类别的概率向量),x1, x2,..., xn 是输入变量,w1, w2,..., wn 是需要学习的权重。 Softmax 分类器的主要优点是它可以处
-
发表了文章 2023-09-14
CIFAR-10
CIFAR-10 数据集是机器学习领域中一个常用的数据集,主要用于图像分类任务。它包含 60000 张 32x32 彩色图片,分为 10 个类别,每个类别有 6000 张图片。其中,50000 张图片用于训练,10000 张图片用于测试。
-
发表了文章 2023-09-14
加载变量
在机器学习中,加载变量通常指从数据集中提取特征变量和目标变量,以便在后续建模和训练过程中使用。特征变量是描述数据样本的属性或特征,而目标变量则是用于评估模型性能的变量。 以下是一个简单的示例,说明如何在 Python 中加载变量:
-
发表了文章 2023-09-12
图像嵌入(Image Embedding
机器学习中的图像嵌入(Image Embedding)是一种将图像数据转化为连续的、低维度的向量表示的方法,这些向量表示通常用于后续的机器学习任务,如分类、聚类、检索等。图像嵌入的目的是将高维度的图像数据转化为更易于处理的低维度数据,同时保留尽可能多的原始图像信息。常用的图像嵌入方法包括:
-
发表了文章 2023-09-09
自组织映射(Self-Organizing Map, SOM
自组织映射(Self-Organizing Map, SOM)是一种聚类方法,它属于非线性降维技术。SOM 的主要思想是将原始数据映射到一个较低维的子空间,同时保持数据之间的原始结构和关系。SOM 的特点是可视化程度较高,可以直观地展示数据中的簇结构和关联关系。
-
发表了文章 2023-09-08
维特比解码(Viterbi Decoding
维特比解码(Viterbi Decoding)是一种用于解码卷积编码(Convolutional Coding)的算法,由 Andrew Viterbi 在 1968 年提出。卷积编码是一种前向纠错编码技术,用于提高数据传输的可靠性。在卷积编码中,数据被组织成一定大小的块,并用一个纠错码附加到数据块中。在接收端,维特比解码算法根据接收到的编码数据,通过比较不同可能的解码路径的权重,来找到最有可能的解码路径,从而实现对数据的解码。
-
发表了文章 2023-09-07
RankNet
RankNet 是一种用于学习排名的机器学习模型,由 Microsoft Research Asia 在 2005 年提出。
-
发表了文章 2023-09-07
自动编码器(Autoencoder
自动编码器(Autoencoder)是一种无监督式学习模型,旨在通过降低数据维度来提高机器学习模型的性能。它由编码器(Encoder)和解码器(Decoder)两个主要部分组成。编码器的作用是将输入数据压缩成低维度的隐向量,从而捕获数据的主要特征;解码器的作用是将隐向量还原回原始数据空间。自动编码器可以实现类似 PCA 的数据降维和数据压缩功能。
-
发表了文章 2023-09-05
嵌入查找(Embedded Lookup)
嵌入查找(Embedded Lookup)是一种机器学习技术,它通过将输入数据映射到低维空间,然后在该空间中进行查找。这种技术可以提高搜索和匹配的速度,尤其是在大规模数据集上
-
发表了文章 2023-09-03
评估系统或算法质量的重要指标
准确性(Accuracy):衡量系统或算法输出结果与真实结果之间的接近程度。通常使用分类准确率、回归误差等指标来评估。 精确率(Precision)和召回率(Recall):主要用于评估分类模型的性能。精确率衡量预测为正例的样本中实际为正例的比例,召回率衡量实际为正例的样本中被正确预测为正例的比例。
-
发表了文章 2023-09-02
L1范数(L1 norm)
L1范数(L1 norm),也称为曼哈顿距离(Manhattan distance)或绝对值范数(Absolute value norm),是向量中各个元素绝对值之和。它在数学和机器学习中经常被用作一种正则化项或稀疏性度量。
-
发表了文章 2023-09-02
数据分割
在机器学习和数据分析中,数据分割是指将可用数据集划分为训练集、验证集和测试集等子集的过程。这种分割的目的是为了评估和验证机器学习模型的性能,并对其进行调优和泛化能力的评估。下面我将解释为什么要进行数据分割,以及如何进行数据分割,并提供一个简单的示例。
-
发表了文章 2023-09-01
MongoDB
MongoDB 是一个基于分布式文件存储的数据库,使用 C 语言编写。它旨在为 Web 应用提供可扩展的高性能数据存储解决方案。MongoDB 介于关系数据库和非关系数据库之间,支持的数据结构非常松散,类似于 JSON 的 BSON 格式,因此可以存储比较复杂的数据类型。MongoDB 的最大特点是支持强大的查询语言,其语法类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能。
-
发表了文章 2023-09-01
反向传播(Backpropagation)
反向传播(Backpropagation)是一种用于训练神经网络的常用算法。它通过计算神经网络中各个参数对于损失函数的梯度,从而实现参数的更新和优化。神经网络是一种模拟人脑神经元相互连接的计算模型,用于解决各种机器学习和深度学习任务。
-
发表了文章 2023-09-01
React
React 是一个用于构建用户界面的 JavaScript 库,由 Facebook 开发,主要用于搭建前端 UI。React 的特点包括声明式设计、高效、灵活,可以与已知的库或框架很好地配合。它采用 JSX 语法,使得开发者能够更方便地描述应用的结构和样式。
-
发表了文章 2023-08-31
Vue
Vue 是一个用于构建用户界面的渐进式 JavaScript 框架。与其它庞大的框架不同,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,使其易于学习和集成到现有项目中。
-
发表了文章 2023-08-30
Laravel
Laravel 是一款基于 PHP 的 Web 应用程序开发框架,它具有简洁、优雅的语法,强大的功能,以及丰富的组件,让开发者能够快速、高效地开发出功能丰富、性能优良的 Web 应用。要用 Laravel,首先需要安装 Laravel。
-
发表了文章 2023-08-30
Express
Express 是一个基于 Node.js 的快速、简洁、灵活的 Web 应用开发框架。它提供了一系列强大的功能,帮助开发者快速构建各种 Web 应用。Express 的原理是利用 Node.js 内置的 http 模块,通过中间件和路由等功能,实现Web应用的开发。
-
发表了文章 2023-08-30
Remax
Remax 是一款基于 Vue.js 的微信小程序开发框架,它提供了一套简洁、完整的 API,让开发者能够快速、高效地开发出功能丰富、性能优良的微信小程序。
-
发表了文章 2023-08-29
高斯-马尔科夫定理(Gauss-Markov theorem)
高斯-马尔科夫定理(Gauss-Markov theorem),也称为高斯-马尔科夫定理(Gauss-Markov theorem)或线性最小二乘定理(linear least squares theorem),是统计学中一个重要的定理,它描述了在一些假设条件下,普通最小二乘估计(Ordinary Least Squares, OLS)是线性回归模型中最优的无偏估计。
-
发表了文章 2023-08-29
关系模式(Relational Model)
关系模式(Relational Model)是一种在数据库中组织和表示数据的方式。它基于关系理论,使用表格(也称为关系)来存储和表示数据。在关系模型中,数据被组织为行(记录)和列(字段)的二维表格。
-
发表了文章 2023-08-28
第三范式(3NF)
第三范式(3NF)是关系数据库设计中的规范化级别之一。它建立在第一范式(1NF)和第二范式(2NF)的基础上
-
 发表了文章
2024-05-28
发表了文章
2024-05-28
WebSocket 协议
-
发表了文章
2024-05-28
Project Object Model
-
发表了文章
2024-05-28
Model-View-Controller
-
发表了文章
2024-05-27
MongoDB
-
发表了文章
2024-05-27
模型评估
-
发表了文章
2024-05-27
JDK序列
-
发表了文章
2024-05-26
网络安全
-
发表了文章
2024-05-26
模型评估
-
发表了文章
2024-05-26
神经网络
-
发表了文章
2024-05-25
FinOps
-
发表了文章
2024-05-25
Copilot+ PC
-
发表了文章
2024-05-25
pid巡线
-
发表了文章
2024-05-24
RocketMQ
-
发表了文章
2024-05-24
MSE Sentinel vs OpenSergo
-
发表了文章
2024-05-24
Volcano 火山模型到 Pipeline
-
发表了文章
2024-05-23
位运算
-
发表了文章
2024-05-23
傅里叶
-
发表了文章
2024-05-23
YOLO
-
发表了文章
2024-05-23
YOLO
-
发表了文章
2024-05-22
RGB颜色模型和HSV颜色模型

-
 回答了问题
2024-05-29
回答了问题
2024-05-29
Hologres这个update 语句执行了20s,要换行存?
数据量大小:更新了大量的行。
索引设计:没有有效的索引来加速更新操作。
网络延迟:数据分布在网络上,更新操作需要跨节点通信。赞0 踩0 评论0 -
回答了问题
2024-05-29
Hologres这个用什么格式?默认吗?
属性不匹配的问题。在 Hologres 中,table orientation 指的是表的数据组织方式,可以是行或列。而 storage format 指的是数据存储的格式,比如 ORC(Optimized Row Columnar)是一种用于列存储的文件格式,它支持高压缩比和高性能的列式访问。
赞0 踩0 评论0 -
回答了问题
2024-05-29
Hologres更新的时候会根据主键读取行存数据,针对更新列去更新列存数据?
行存数据:
行存格式适合于高并发的点查和更新操作。
当执行更新操作时,Hologres 会根据主键定位到具体的行数据。
列存数据:列存格式适合于分析型查询,尤其是当查询涉及到的数据列较少时。
列存数据通常在后台进行维护,例如,通过异步的方式进行数据的整理,以优化查询性能。赞0 踩0 评论0 -
回答了问题
2024-05-29
最近大模型降价潮,哪家才是真的“价美”也“物美”?
回复模版,A更简介明了,xiag
相对较差。
卡死
我们需要求解快车从起点到终点共用的时间。我们可以先计算慢车的总时间,再利用快车和慢车的速度关系来求解快车的时间。
慢车的行程时间计算:
慢车停留时间计算:慢车停15个车站,每站停留2分钟,总停留时间为 (2 \times 15 = 30) 分钟。
慢车的行驶时间(不包括停留时间):假设慢车的速度为 (v),慢车行驶的时间为 (t) 分钟。
因为慢车从起点到终点共用 (t + 30) 分钟。
快车的行程时间计算:
快车的速度是慢车的1.5倍,即快车的速度为 (1.5v)。
快车只停一次,这段停留时间为2分钟。
假设快车的行驶时间(不包括停留时间)为 (T) 分钟。
因为快车从起点到终点共用 (T + 2) 分钟。
根据题意,快车是在慢车发出60分钟后出发,且两车同时到达终点:
[ t + 30 = T + 60 + 2 ]简化方程:
[ t + 30 = T + 62 ]
[ t = T + 32 ]速度关系:
慢车行驶的总距离与快车行驶的总距离相同。
慢车的行驶时间为 (t),快车的行驶时间为 (T)。
因为 (快车速度 = 1.5 \times 慢车速度),所以我们有:
[ \frac{\text{总距离}}{T} = 1.5 \times \frac{\text{总距离}}{t} ]
[ \frac{1}{T} = 1.5 \times \frac{1}{t} ]
[ t = 1.5T ]
根据 (t = T + 32),代入 (t = 1.5T):
[ 1.5T = T + 32 ]
[ 1.5T - T = 32 ]
[ 0.5T = 32 ]
[ T = 64 ]所以,快车从起点到终点的行驶时间为 (T = 64) 分钟,加上停留的2分钟,总时间为:
[ 64 + 2 = 66 ] 分钟。因此,快车从起点到终点共用66分钟。
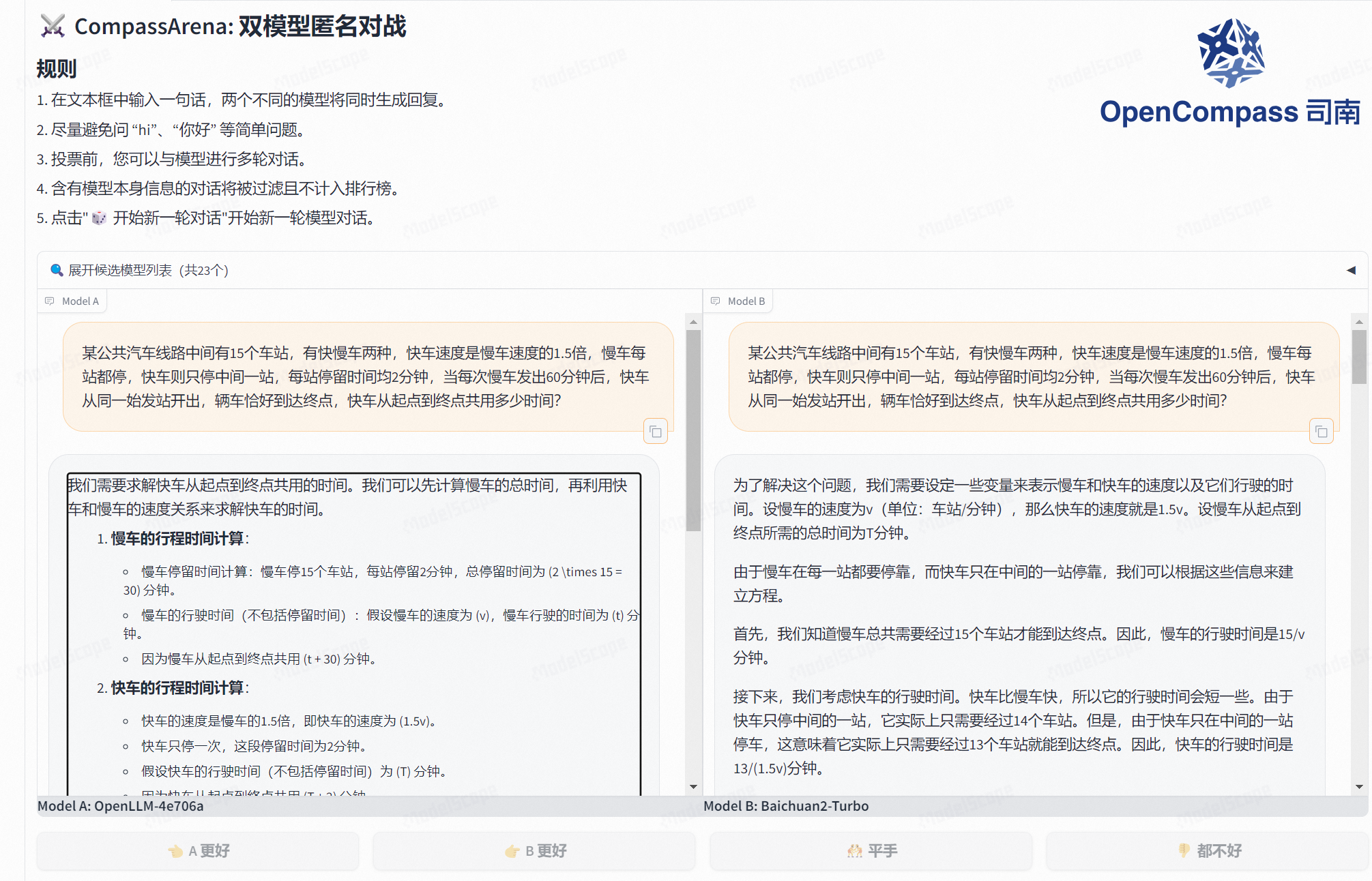
答案精准第一位
速度 高效 第二位
表达高效 第三位
使用遍历 成本 较低。
赞3 踩0 评论0 -
回答了问题
2024-05-28
请问Android性能高的具体参数或者指标是什么?
处理器(CPU):
核心数:多核处理器可以同时处理更多任务。
主频:处理器的时钟频率,通常以 GHz 计量,频率越高,处理速度越快。
架构:更先进的架构可以提供更高的性能和能效比。
图形处理器(GPU):GPU 的性能直接影响图形密集型应用和游戏的流畅度。
支持的图形 API 级别,如 OpenGL ES、Vulkan 等。赞0 踩0 评论0 -
回答了问题
2024-05-28
性能分析的SDK接入后,gradle编译报错,再编译就不报,然后一直循环,这是什么问题?
插件应用冲突:
如果项目中使用了多个插件,可能存在冲突。检查 build.gradle 文件中是否正确应用了所有插件。
Gradle Daemon 问题:有时 Gradle Daemon 可能遇到问题导致编译失败。尝试停止 Gradle Daemon 进程并重新编译:
./gradlew --stop赞0 踩0 评论0 -
回答了问题
2024-05-28
使用websocket请求asr 返回40000002错误码
检查消息格式:
确保发送的消息格式符合服务器的要求。检查 JSON 对象是否完整且格式正确。
检查编码问题:如果消息中包含特殊字符,确保它们被正确编码。
赞0 踩0 评论0 -
回答了问题
2024-05-28
快速部署MC服务器
配置服务器:
编辑 server.properties 文件,根据需要配置服务器设置,比如游戏模式、难度、玩家数量等。
启动服务器:运行服务器软件中的启动脚本(可能是一个可执行文件或一个批处理脚本)。
赞1 踩0 评论0 -
回答了问题
2024-05-28
请问android上怎么保持服务不被杀死?类似微信通知服务,一直都能收到消息。
进程守护
使用前台服务
将服务设置为前台服务,这样可以提高其优先级,减少被系统杀死的可能性。前台服务需要显示一个持续性的通知给用户,告知服务正在进行的活动。Notification notification = ...; // 创建通知
startForeground(NOTIFICATION_ID, notification); // 将服务提升为前台服务
请求高优先级
在 Android 8.0(API 级别 26)及以上版本中,可以使用 setProcessImportance 方法请求高优先级。Process.setProcessImportance(Process.IMPORTANCE_HIGH);
使用工作服务
使用 startForegroundService() 或 JobScheduler、WorkManager API 来启动服务,这些方法允许系统更灵活地管理服务,同时保持服务的稳定性。进程守护技术
创建一个守护服务,当主服务被杀死时,守护服务会重新启动它。这种方法需要两个服务相互监听对方的状态,并在对方被杀死时重启对方。// 主服务中
Intent intent = new Intent(this, GuardianService.class);
startService(intent);// 守护服务中
Intent intent = new Intent(this, MainService.class);
PendingIntent pendingIntent = PendingIntent.getService(this, 0, intent, 0);
AlarmManager alarmManager = (AlarmManager) getSystemService(Context.ALARM_SERVICE);
alarmManager.setInexactRepeating(AlarmManager.ELAPSED_REALTIME,
0, AlarmManager.INTERVAL_HALF_HOUR, pendingIntent);// 监听主服务是否被停止,并在需要时重启
监听系统广播
监听系统广播,如 ACTION_PACKAGE_RESTARTED 或 ACTION_SHUTDOWN,来重启服务。IntentFilter filter = new IntentFilter();
filter.addAction(Intent.ACTION_SHUTDOWN);
filter.addAction(Intent.ACTION_PACKAGE_RESTARTED);
filter.addDataScheme("package");
registerReceiver(serviceReceiver, filter);赞0 踩0 评论0 -
回答了问题
2024-05-28
当AI“复活”成为产业,如何确保数字生命技术始终用于正途?
AI“复活”或数字生命技术的兴起确实带来了许多潜在的好处,比如在教育、娱乐、心理健康支持等领域的应用。然而,这项技术也引发了伦理、法律和社会方面的挑战。
可以考虑几个方面
制定明确的法律法规
制定相关的法律法规来规范数字生命技术的用途,保护个人隐私,防止滥用。法律应该明确界定什么可以做,什么不可以做,并对违规行为设定严格的惩罚措施。
强化伦理审查
建立伦理审查委员会,对数字生命技术的应用进行伦理评估。确保技术的应用不会侵犯个人权利,不会对社会造成负面影响。
增强透明度和可解释性
技术开发者应该提高算法的透明度和可解释性,让用户了解他们的数据如何被使用,以及数字生命是如何被创建和运作的。
公众教育和意识提升
通过教育和公共宣传提高公众对数字生命技术的认识,包括它的好处和潜在风险,使公众能够做出明智的决策。
赞4 踩0 评论0 -
回答了问题
2024-05-28
一条SQL语句的执行究竟经历了哪些过程?
一条 SQL 语句的执行过程确实包含了许多步骤,
- 客户端提交 SQL 语句
用户通过客户端工具(如命令行、图形界面工具或应用程序)编写并提交 SQL 语句。 - 语法解析
数据库服务器接收到 SQL 语句后,首先进行语法解析。解析器检查 SQL 语句的语法是否正确,如关键字是否准确、语法结构是否符合规则等。 - 语义分析
接下来进行语义分析,这一步解析器检查 SQL 语句中的数据库对象(表、列等)是否存在,以及用户是否对这些对象有相应的操作权限。 - 优化器选择执行计划
解析和优化器将 SQL 语句转换成一个或多个执行计划。优化器负责选择最佳的查询计划,这涉及到选择不同的索引、确定表的连接顺序、决定使用哪种类型的连接算法等。 - 权限检查
在执行前,系统还会进行权限检查,确保执行该语句的用户具有足够的权限。 - 执行 SQL 语句
执行计划被送到执行引擎,开始实际的查询或更新操作。对于查询语句,这可能涉及到:
索引查找:如果语句中包含 WHERE 子句,数据库可能会使用索引来快速定位到相关的数据行。
表扫描:如果没有可用的索引或索引不适用,则进行全表扫描。
连接操作:对于涉及多个表的查询,执行诸如嵌套循环连接、哈希连接等操作。
排序操作:如果语句中包含 ORDER BY 子句,执行排序操作。 - 结果集处理
查询结果被返回并可能经过进一步的处理,如聚合计算(GROUP BY 和聚合函数)。 - 返回结果
处理完成的结果集被发送回客户端。 - 缓存和写入
对于更新操作(如 INSERT、UPDATE、DELETE),数据库会先将更改写入到事务日志中以保证事务的持久性和恢复能力,然后将更改应用到数据页上。
数据库可能还会利用缓存来提高性能,将频繁访问的数据保留在内存中。 - 事务管理
如果 SQL 语句是事务的一部分,数据库会确保它要么完全应用,要么在出现错误时完全回滚,以保持数据的一致性。 - 日志记录
数据库会记录操作日志,用于监控、调试和性能分析。
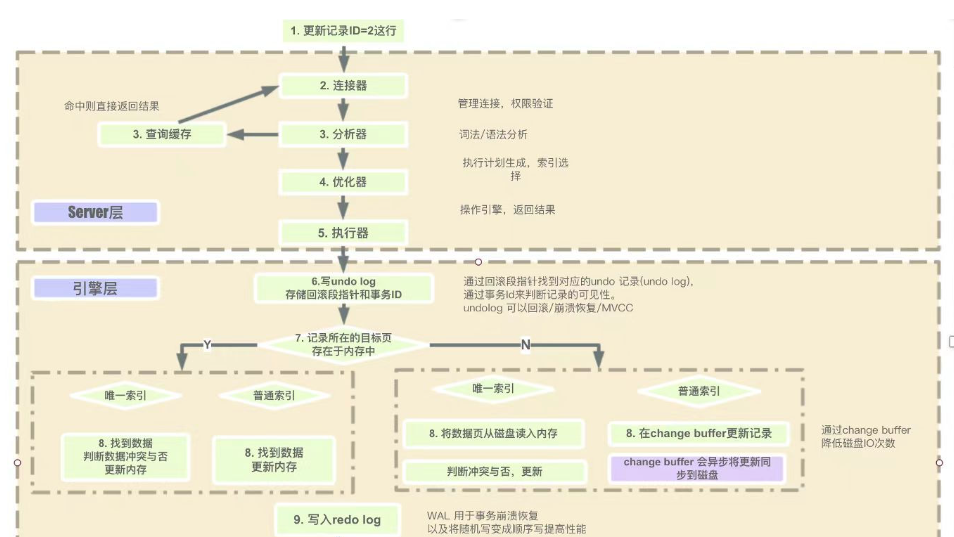 赞6 踩0 评论0
赞6 踩0 评论0 - 客户端提交 SQL 语句
-
回答了问题
2024-05-27
为什么 PAI DSW中一直无法使用GPU加速tensorflow,如何使用GPU加速.
cuDNN注册问题:错误信息Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered表明cuDNN工厂已经被注册,可能存在版本冲突或初始化问题。
cuFFT和cuBLAS注册问题:类似的注册问题也出现在cuFFT和cuBLAS上,这可能与TensorFlow试图加载的GPU操作库有关。
赞1 踩0 评论0 -
回答了问题
2024-05-27
web terminal 下面没有Chrome浏览器按钮
Web Terminal设置问题:
检查Web Terminal的设置,看是否有选项可以启用或显示Chrome浏览器按钮。
权限问题:确认你的账户权限是否允许使用Web Terminal的所有功能。
赞0 踩0 评论1 -
回答了问题
2024-05-27
在云效中工作任务导入显示失败,如何解决?
检查文件大小和行数:如果文件过大或行数过多,可能会导致导入失败。尝试将数据拆分成更小的文件进行导入。
检查网络连接:不稳定的网络连接可能会导致导入过程中断,确保网络环境稳定。
赞1 踩0 评论0 -
回答了问题
2024-05-27
在云效中按导出格式,导入怎么显示失败,如何解决?
使用最新版本的Excel:如果你使用的是较旧版本的Excel创建或编辑文件,可能会遇到兼容性问题。尝试使用最新版本的Excel打开和保存文件。
检查文件完整性:如果文件损坏,它可能无法被正确解析。尝试重新创建文件或从备份中恢复。
赞0 踩0 评论0 -
回答了问题
2024-05-26
报错的都是oom,显存爆了,不用加哪些modelscope参数?
减小批量大小(Batch Size):
如果命令中可以指定批量大小,尝试减小它。较小的批量大小会减少每次迭代的显存需求。
调整--quant_n_samples和--quant_seqlen:对于AWQ量化,减小--quant_n_samples(默认值通常是256)和--quant_seqlen(默认值通常是2048)可以减少量化过程中的显存占用。
赞2 踩0 评论0 -
回答了问题
2024-05-26
请问modelscope中做量化swift和tensorRT llm有区别吗?
Swift支持使用AWQ、GPTQ、BnB、HQQ、EETQ等技术对模型进行量化。
Swift的量化可以用于推理加速,并且量化后的模型支持QLoRA微调。
Swift提供了命令行工具来执行量化操作,例如使用AWQ进行INT4量化,并支持自定义量化数据集。赞5 踩0 评论0 -
回答了问题
2024-05-26
7b chat做modelscope awq的int4量化,特别容易爆显存,怎么解决?
分批处理:
如果模型太大,无法一次性加载到GPU中,可以考虑将数据分批处理,每次只处理模型的一部分。
梯度累积:使用梯度累积技术,通过在多个小批量上累积梯度,然后一次性更新权重,这样可以减少每次迭代所需的显存。
赞6 踩0 评论0 -
回答了问题
2024-05-25
将用户上传的文件信息及上传记录保存到 MaxCompute 表中上传记录?
的业务需求来设计。例如:
file_upload 表可能包含以下列:file_id, user_id, file_name, file_size, file_type, upload_time 等。
upload_record 表可能包含以下列:record_id, file_id, upload_status, start_time, end_time 等。赞3 踩0 评论0 -
回答了问题
2024-05-25
阿里云c++sdk实时语音识别嵌入mrcp
确保Lua脚本传递的参数正确无误,并且C++ SDK能够正确解析和应用这些参数。检查是否有任何缓存或旧配置影响当前设置。
检查C++ SDK中关于超时逻辑的实现。可能是识别超时和无输入超时的逻辑叠加了,需要调整逻辑以确保它们不会相互累积。
赞4 踩0 评论0