
探索云世界




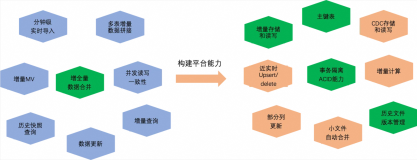
本文主要介绍基于 MaxCompute 的离线近实时一体化新架构如何来支持这些综合的业务场景,提供近实时增全量一体的数据存储和计算(Transaction Table2.0)解决方案。

10年老兵带你看尽MaxCompute大数据运算挑战与实践
在大数据时代,要想个性化实现业务的需求,还是得操纵各类的大数据软件,如:hadoop、hive、spark等。笔者(阿里封神)混迹Hadoop圈子多年,经历了云梯1、ODPS等项目,目前base在E-Mapreduce。在这,笔者尽可能梳理下hadoop的学习之路。

ODPS(Open Data Processing Service),原是阿里云从 09年开始自研的大规模批量计算引擎,2016 年更名为MaxCompute。2022云栖大会上,阿里云ODPS全新升级为一体化大数据平台,存储、调度、元数据一体化融合 ,从 Processing 升级为 Platform,即 Open Data Platform and Service。提供了离线计算、实时交互式分析、机器学习等可扩展的智能计算引擎,满足用户多元化数据计算需求。
2017杭州云栖大会将于10月11-14日在杭州云栖小镇举办,作为全球最具影响力的科技展会之一,今年的云栖大会规模更大,内容也更丰富。为了帮助大家解决报名、参会中的一些问题,小编专门整理了下大会相关的FAQ,供大家参考。
还在为传统 DBMS 的性能问题而烦恼?想借助 ODPS 的分布计算能力?但是你又不想学习官方的 SDK ?如果你恰好在老项目中用了 JDBC 访问 Oracle 或 MySQL?那么你可能对这篇文章感兴趣。本文将结合几种常见的使用场景(数据查询、数据导入、第三方客户端工具)来介绍odps-jdbc
“用户每天产生的日志量大约在2TB。我们需要将这些海量的数据导入云端,然后分天、分小时的展开数据分析作业,分析结果再导入数据库和报表系统,最终展示在运营人员面前。”墨迹天气运维部经理章汉龙介绍,整个过程中数据量庞大,且计算复杂,这对云平台的大数据能力、生态完整性和开放性提
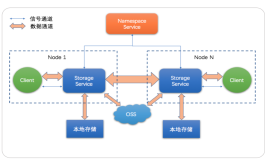
JindoFS 是EMR打造的高性能大数据存储服务,可以为不同的计算引擎提供不同的存储服务,可以根据应用的场景来选择不同的存储模式。在2019杭州云栖大会大数据生态专场,阿里巴巴计算平台事业部EMR团队技术专家殳鑫鑫和Intel大数据团队软件开发经理徐铖共同向大家分享了云上大数据的高性能数据湖存储方案JindoFS的产生背景、架构以及与Intel DCPM的性能评测。

8 月最后一天,由 Apache Kafka 与 Apache Flink 联合举办的 Meetup 深圳站圆满落幕,现场站无虚席,来自 Confluent 、中国农业银行 、虎牙直播、数见科技以及阿里巴巴的五位技术专家带来了丰富精彩的分享,全场干货满满!
机器学习算法基于信用卡消费记录做信用评分 背景 如果你是做互联网金融的,那么一定听说过评分卡。评分卡是信用风险评估领域常用的建模方法,评分卡并不简单对应于某一种机器学习算法,而是一种通用的建模框架,将原始数据通过分箱后进行特征工程变换,继而应用于线性模型进行建模的一种方法。
背景 [PyODPS DataFrame]http://pyodps.readthedocs.io/zh_CN/latest/) 提供了类似 pandas 的接口,来操作 ODPS 数据,同时也支持在本地使用 pandas,和使用数据库来执行。
作者简介: 范伦挺 阿里巴巴 基础架构事业群-技术专家 花名萧一,2010年加入阿里巴巴,现任阿里巴巴集团大数据计算平台运维负责人。团队主要负责阿里巴巴各类离在线大数据计算平台(如MaxCompute、AnalyticDB、StreamComput
这篇帖子,就以推荐引擎产品上的离线算法和在线算法给大家说明下,并且方便后续如果在产品使用中如果发现通用的计算规则不符合自己的场景的时候,需要做一些优化的时候,也能更好地指导怎么调。
很多农民因为缺乏资金,在每年耕种前会向相关机构申请贷款来购买种地需要的物资,等丰收之后偿还。农业贷款发放问题是一个典型的数据挖掘问题。贷款发放人通过往年的数据,包括贷款人的年收入、种植的作物种类、历史借贷信息等特征来构建经验模型,通过这个模型来预测受贷人的还款能力。
本文通过几个例子,介绍了几种下载MaxCompute SQL计算结果的方法。为了减少篇幅,所有的SDK部分都只举例介绍Java的例子。 SQLTask SQLTask是SDK直接调用MaxCompute SQL的接口,能很方便得运行SQL并获得其返回结果。 从文档可以看到,SQLTask.ge
概述 在人工智能领域存在这样的现象,很多用户有人工智能的需求,但是没有相关的技术能力。另外有一些人工智能专家空有一身武艺,但是找不到需求方。这意味着在需求和技术之间需要一种连接作为纽带。 今天PAI正式对外发布了“AI市场”以及“PAI自定义算法”两大功能,可以帮助用户5分钟将线下的spark算法或是pyspark算法发布成算法组件,并且支持组件发布到AI市场供更多用户使用。
传统的搜索文本相关性模型,如BM25通常计算Query与Doc文本term匹配程度。由于Query与Doc之间的语义gap, 可能存在很多语义相关,但文本并不匹配的情况。为了解决语义匹配问题,出现很多LSA,LDA等语义模型。
1月15日在北京举行了首次阿里云大数据合作伙伴深度培训,我司获邀参加,我和两名研发的同学又一次来到了阿里巴巴望京园区。  > 培训的第一部分内容、数加的介绍及应用 除了介绍性内容之外,还是有「干货」的,这个干货就是MaxCompute 的实践。
DataHub服务是MaxCompute提供的流数据服务, 并提供把实时数据准实时归档到MaxCompute中功能, 在延时上可以做到5分钟数据在MaxCompute中可见;相对于MaxCompute之前提供的批量数据接口Tunnel实时性有了极大的提高。本文简要介绍如何快速通过DataHub创建.
一、背景介绍 随着数据规模的不断扩大,传统的RDBMS难以满足OLAP的需求,本文将介绍如何将Oracle的数据实时同步到阿里云的大数据处理平台当中,并利用大数据工具对数据进行分析。 OGG(Oracle GoldenGate)是一个基于日志的结构化数据备份工具,一般用于Oracle数据
章剑锋(简锋),开源界老兵,Apache Member,曾就职于 Hortonworks,目前在阿里巴巴计算平台事业部任高级技术专家,并同时担任 Apache Tez、Livy 、Zeppelin 三个开源项目的 PMC ,以及 Apache Pig 的 Committer。
阿里云大数据实验室时阿里云开发的一站式大数据教学实践和科研创新平台,提供创业创新大赛平台,为各行业用户提供简单易用的大数据真实环境,让数据价值触手可及。在阿里云大数据实验室中集成了MaxCompute。
PyOdps 0.4版本,DataFrame API支持使用pandas进行本地计算,用户因此能join ODPS和本地数据,也能进行本地debug,另外还有MapReduce API等新特性
从98年成立至今的18年中,网鱼累计签约门店已接近900家,已拥有超过830万会员,2016年网鱼网咖共服务了3300多万人次,服务范围覆盖全国100多个城市,现在网鱼网咖已走出国门,在加拿大、澳大利亚、新加坡等国家开设多家门店。
之前尝试使用过一些国内外的云产品,特别是大数据分析型产品,例如:亚马逊的EMR、Redshift,Google的Bigquery以及阿里云的MaxCompute。相信大多数人对亚马逊的EMR、Redshift,Google的Bigquery都比较了解。
最近,经常有客户咨询如何低成本搭建高性能的海量数据搜索引擎,比如实现公众号检索、影讯检索等等。由于客户的数据在阿里云上,所以希望找到云上解决方案。笔者开始调研一些云上产品,很多人向我推荐了OpenSearch,所以花了点时间好好研究了下,用过之后发现效果不错,自带分词、云数据库同步功能,在研究过程中也发现了一些问题,分享给大家。
Spark AI 北美峰会的第一天,坊间传闻被证实,Databrics(俗称数砖,亦称砖厂)的杀手锏 Delta 产品特性作为 Delta Lake 项目开源!会前,笔者有幸同砖厂的两位大佬李潇和连城做了个线下交流,谈到 Delta 时被告知会有相关重磅在大会上宣布,但却没想到是开源出去。
阿里云Elasticsearch集成了Elastic Stack商业版的X-Pack组件包,包括安全、告警、监控、报表生成、图分析、机器学习等组件,用户可以开箱即用。本文将对X-Pack 的告警组件功能进行详细解读。
如何从海量的历史、实时数据中快速获取有用信息,令搜索变得越来越具挑战性。OpenSearch是阿里云推出的一款云搜索服务,本文将介绍OpenSearch的发展历程、基本功能、以及实现原理和架构,以实际应用场景为例讲述应用实践过程。
实时业务处理的需求越来越多,也有各种处理方案,比如storm,spark等都可以。那以数据流的方向可以总结成数据源-数据搜集-缓存队列-实时处理计算-数据展现。本文就用阿里云产品简单实现了一个实时处理的方案。
一,背景与概述 复杂系统的灾难恢复是个难题,具有海量数据及复杂业务场景的大数据容灾是个大难题。 MaxCompute是集团内重要数据平台,是自主研发的大数据解决方案,其规模和稳定性在业界都是领先的。
一、总览 一个游戏/系统的业务数据分析,总体可以分为图示的几个关键步骤: 1、数据采集:通过SDK埋点或者服务端的方式获取业务数据,并通过分布式日志收集系统,将各个服务器中的数据收集起来并送到指定的地方去,比如HDFS等;(注:本文Demo中,使用flume,也可选用logstash、Flue.
实际问题 很多大数据计算产品,都对用户提供了SQL API,比如Hive, Spark, Flink等,那么SQL作为传统关系数据库的查询语言,是应用在批查询场景的。Hive和Spark本质上都是Batch的计算模式(在《Apache Flink 漫谈系列 - 概述》我们介绍过Spark是Micr.
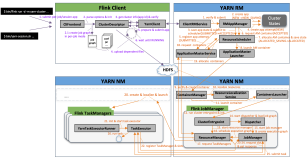
上篇分享了基于 FLIP-6 重构后的资源调度模型介绍 Flink on YARN 应用启动全流程,本文将根据社区大群反馈,解答客户端和 Flink Cluster 的常见问题,分享相关问题的排查思路。
人工智能千千万,没法落地都白干。 自从上次老司机用神经网络训练了热狗识别模型以后,群众们表示想看一波更加接地气,最好是那种能10分钟上手,一辈子受用的模型。 这次,我们就通过某著名电商公司的公开数据集,在阿里云大数据生态之下快速构建一个基于协同过滤的推荐系统!
随着MaxCompute(ODPS)2.0的上线,新增的非结构化数据处理框架也推出一系列的介绍文章,包括 MaxCompute上如何访问OSS数据, 基本功能用法和整体介绍,侧重介绍读取OSS数据进行计算处理; 本文:MaxCompute(ODPS)上处理非结构化数据的Best Practice。
本周关注:马云谈云计算、大数据、人工智能未来三十年,E-MapReduce存储计算分离,真实的大数据故事,spark session及spark mmlib、presto+oss
数据分析和游戏的生命周期与盈利息息相关,同时数据分析对游戏的运维也起到了至关重要的作用,精确的数据分析可以延长游戏的生命和帮助其盈利。本文针对游戏行业的数据特点,结合游戏数据分析的现状,对数据分析上云的技术选型、结合数加大数据计算服务MaxCompute(原ODPS)、SLS、RDS、DPC等产品和
目前E-MapReduce的开源组件还未包含Kylin,下面介绍一种通过创建集群时设置的引导操作来完成集群上Kylin的部署。
案例与解决方案汇总页:阿里云实时计算产品案例&解决方案汇总 1.计算广告背景 广告仍然是互联网公司的主要变现手段,其市场规模2017年已达3000亿元,据统计全球互联网市值前十的公司广告收入占比高达40%,可见其重要性。

本文是根据 Apache Flink 基础篇系列直播整理而成,由 Apache Flink PMC 戴资力与阿里巴巴高级产品专家陈守元共同分享。Apache Flink 系列入门教程每周更新一期,持续推送。
背景及目的 方便和辅助MaxCompute的project owner或安全管理员进行project的日常安全运维,保障数据安全。 MaxCompute有安全模型,DataWorks也有安全模型,当通过DataWorks使用MaxCompute,而DataWorks的安全模型不满足业务安全需求时,合理的将两个安全模型结合使用就尤其重要。
之前有很多DataWorks用户问MaxCompute访问权限问题,比如子账号为什么可以增删查别人在别的项目创建的表,即使这个子账号并没有加入那个项目 。 今天手把手教大家实现子账号授权并关闭跨Project的数据访问权限。
## 引言 iGraph是一个在线图存储和查询服务,从2015年年初正式上线到现在,已经平稳经历了3次双十一大促的历练。这一些长期投入让iGraph赢得了越来越多集团客户的信任,其中包括集团的核心搜索和推荐业务。

大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。




