









RAG 不是万能解,这些场景你一开始就不该用
RAG并非万能,默认滥用反致系统复杂、效果难测。它仅解决“信息获取”,不提升模型能力。最适合四类场景:动态知识更新、需答案溯源、长尾问题密集、需求尚不明确。慎用于强推理、隐性经验、高实时性及高确定性要求场景。核心判断:问题是“找不到信息”,还是“不会处理信息”?
GLM-4V-9B 视觉多模态模型本地部署教程【保姆级教程】
本教程详细介绍如何在Linux服务器上本地部署智谱AI的GLM-4V-9B视觉多模态模型,涵盖环境配置、模型下载、推理代码及4-bit量化、vLLM加速等优化方案,助力高效实现图文理解与私有化应用。

不是吧?这么好用的开源标注工具,竟然还有人不知道…
LabelU是一款专为AI项目设计的强大多模态数据标注工具,支持图像、视频、音频等多样化数据类型。它提供灵活的标注工具与自定义配置选项,让用户根据需求定制高效标注流程。特色功能包括一键载入预标注结果以简化修正工作,以及支持JSON、COCO等多种格式的导出选项。LabelU既可本地部署确保数据安全,也提供在线版本方便快速上手。此外,OpenDataLab还开源了Label-LLM对话标注工具和MinerU文档处理工具,进一步丰富了数据准备的工作流。欢迎访问[LabelU](https://github.com/opendatalab/labelU)了解更多详情,并为这些优秀工具点赞支持!

【最佳实践】esrally:Elasticsearch 官方压测工具及运用详解
由于 Elasticsearch(后文简称 es) 的简单易用及其在大数据处理方面的良好性能,越来越多的公司选用 es 作为自己的业务解决方案。然而在引入新的解决方案前,不免要做一番调研和测试,本文便是介绍官方的一个 es 压测工具 esrally,希望能为大家带来帮助。
向量数据库实战:从建库到第一次翻车
向量数据库首次“建库成功”反而是最危险时刻——表面跑通,实则埋下隐患。真实挑战不在“能否检索”,而在“检出内容能否支撑正确决策”。数据规模扩大、类型变杂后,切分失当、chunk等价化、TopK抖动等问题集中爆发。翻车本质是知识组织问题,而非工具选型问题。
淘宝商品详情API(tb.item_get)
本文详解淘宝开放平台商品详情核心API(如item_get),涵盖对接流程、权限申请、请求规范、参数说明及返回字段,并列举代购集运、选品分析、比价导购等典型应用场景,助力开发者合规高效获取商品数据。(239字)
PPO 实战:第一次跑通 PPO,到底难在哪
PPO实战难点不在算法理解,而在系统性不确定:动态数据、不稳reward、多目标冲突。关键在于明确对齐目标、用SFT模型起步、必备reference、设计偏好型reward、聚焦policy更新、善用KL系数调控风险,并以行为变化而非loss曲线评估进展——耐心跑通最小闭环,才是成功核心。
电脑必备软件:PortableApps便携式软件管理工具安装使用教程:U盘装软件随身带
PortableApps是一款免费开源的便携式软件管理平台,支持将软件安装至U盘,即插即用,拔出不留痕迹。内置近500款实用软件,无需安装,跨平台使用便捷,支持个性化主题设置,让软件随身携带,工作学习更高效。
PyCharm 2025.1 完整教程:下载安装 + 中文设置 + 激活,一步到位,附安装包
PyCharm 2025.1 发布,重磅升级AI代码补全、类型推断与ruff集成,提升开发效率。支持渐进式补全、智能提交信息生成、冲突可视化解决,优化启动速度与内存占用,全面增强云原生及现代Python开发体验。
解锁3D创作新姿势!Autodesk 3ds Max 2022中文版安装教程(附官方下载渠道)
Autodesk 3ds Max 2022 是一款专业三维建模、动画和渲染软件,广泛应用于影视、游戏、建筑等领域。其特点包括智能建模工具、高效Arnold渲染引擎、跨平台协作及多语言支持。安装需满足Win10/11系统、i5以上处理器、8GB内存等要求。正版安装流程包括下载官方程序、配置组件、激活许可证并验证功能。常见问题如安装失败、中文乱码等提供了解决方案。扩展学习资源推荐Forest Pack、V-Ray等插件,助力用户深入掌握软件功能。

给大模型“开小灶”:一文读懂微调原理与实战,让你的AI更懂你
本文深入浅出讲解大模型微调:为何需“开小灶”?详解全量微调、LoRA(装插件)、Prompt Tuning(学咒语)及RLHF等主流方法;手把手演示LoRA三步实践——数据准备、配置训练、测试部署;并提供效果评估与低门槛工具推荐。助力开发者快速打造领域专属AI。(239字)
智能体来了!2026 AI 元年:在全新赛道上重构人类生产力边界
2026年被定义为“智能体元年”:AI从“能说”跃升为“能干”,实现自主决策、跨系统协作与具身执行。产业迎来智能体市场、数字劳动力网络和可信治理三大爆发点,人类角色转向目标设定与智能体调度。技术终指向人的升华。(239字)
智能体对传统行业冲击:中后台,才是产业重塑的第一现场
本文探讨AI从“流程自动化”迈向“认知自主化”后,对传统行业结构性变革的影响:中后台(非一线岗位)正率先被智能体重构——因其任务具数字原生性、决策密度高、协调成本大。供应链、财务、人力三大场景首当其冲。组织正加速演进为“沙漏型”:价值重心转向决策自动化与智能体策略成熟度。(239字)
PDF 转 Markdown 神器:MinerU 2.5 (1.2B) 部署全攻略
MinerU是由OpenDataLab推出的开源PDF解析工具,支持精准布局分析、公式识别与表格提取。本文详解其2.5-2509-1.2B版本在Linux下的部署流程,涵盖环境搭建、模型下载、核心配置及实战应用,助你高效处理复杂PDF文档,提升AI数据清洗效率。
requirement.txt 管理python包依赖
在 Python 项目中,`requirements.txt` 用于记录依赖库及其版本,便于环境复现。本文介绍了多种生成该文件的方法:基础方法使用 `pip freeze`,进阶方法使用 `pipreqs`,专业方法使用 `poetry` 或 `pipenv`,以及手动维护方式。每种方法适用不同场景,涵盖从简单导出到复杂依赖管理,并提供常见问题的解决方案,帮助开发者高效生成精准的依赖列表,确保项目环境一致性。
云栖实录 | GenAI 时代 AI Infra 工程技术趋势与平台演进
本文根据2024云栖大会实录整理而成,演讲信息如下: 演讲人:林伟 | 阿里云智能集团研究员、阿里云人工智能平台 PAI 负责人;黄博远|阿里云智能集团资深产品专家、阿里云人工智能平台 PAI 产品负责人 活动:2024 云栖大会 - AI Infra 核心技术专场、人工智能平台 PAI 年度发布专场
什么是HDR?HDR与SDR的区别?
HDR(高动态范围)技术是一种近年来变得流行的图像技术,用于拍摄更自然、更真实的影像,尤其在Audio / Visual设备和数码相机等方面得到了广泛应用。在这里,我们将解释HDR技术的具体是什么,HDR与SDR的区别,HDR与4K的关系,以及HDR一般内置在哪些设备中。
智启未来:2026年,AI从“技术工具”到“共生文明”的跨代元年
2026年,“会基础设施”范式跃迁开启人类与非生物智能共治的“第二个起源”。AI从工具升维为文明要素:技术迈入工业级确定性应用,能力下沉至个体;产业全链重构,制度启动动态合规、权责厘清与红利再分配;文明契约转向生态共生、意义赋予与思维共同体培育——未来在制度与共识之中。
【跨国数仓迁移最佳实践8】MaxCompute Streaming Insert:大数据数据流写业务迁移的实践与突破
本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第八篇,MaxCompute Streaming Insert:大数据数据流写业务迁移的实践与突破。 注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
Python新手常见问题一:列表、元组、集合、字典区别是什么?
本文针对Python编程新手常遇到的问题,详细阐述了列表(List)、元组(Tuple)、集合(Set)和字典(Dictionary)这四种数据结构的核心区别。列表是一种有序且可变的数据序列,允许元素重复;元组同样有序但不可变,其内容一旦创建就不能修改;集合是无序、不重复的元素集,强调唯一性,主要用于数学意义上的集合操作;而字典则是键值对的映射容器,其中键必须唯一,而值可以任意,它提供了一种通过键查找对应值的有效方式。通过对这些基本概念和特性的对比讲解,旨在帮助初学者更好地理解并运用这些数据类型来解决实际编程问题。
3D目标检测数据集 KITTI(标签格式解析、3D框可视化、点云转图像、BEV鸟瞰图)
本文介绍在3D目标检测中,理解和使用KITTI 数据集,包括KITTI 的基本情况、下载数据集、标签格式解析、3D框可视化、点云转图像、画BEV鸟瞰图等,并配有实现代码。
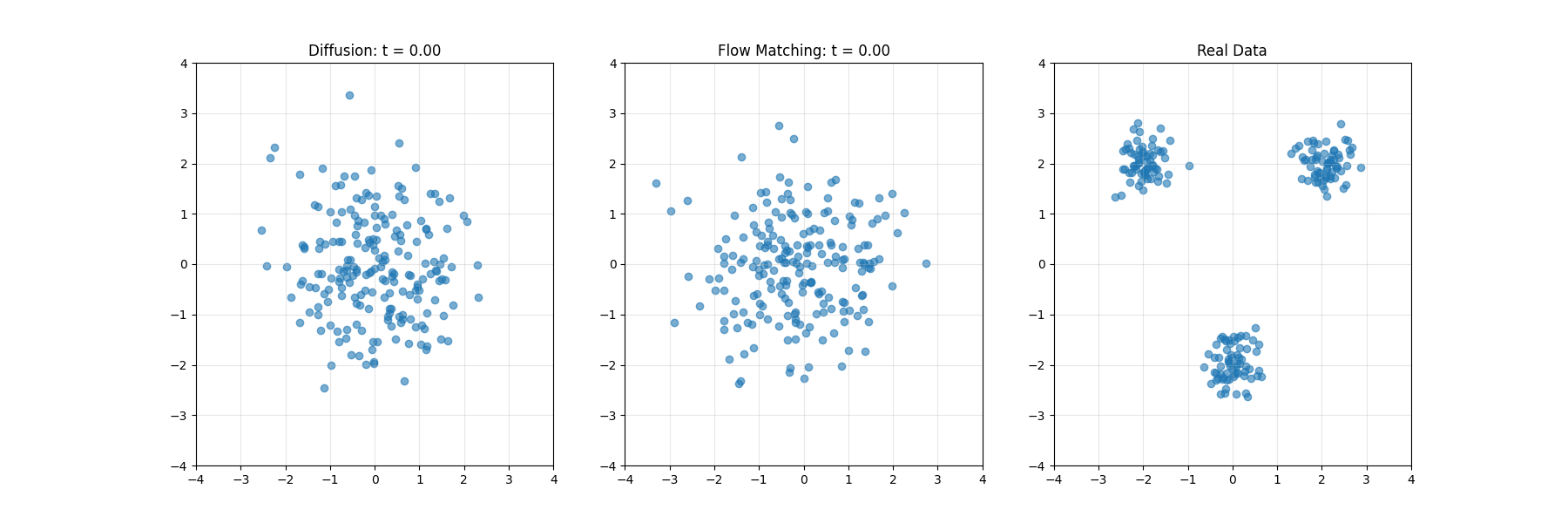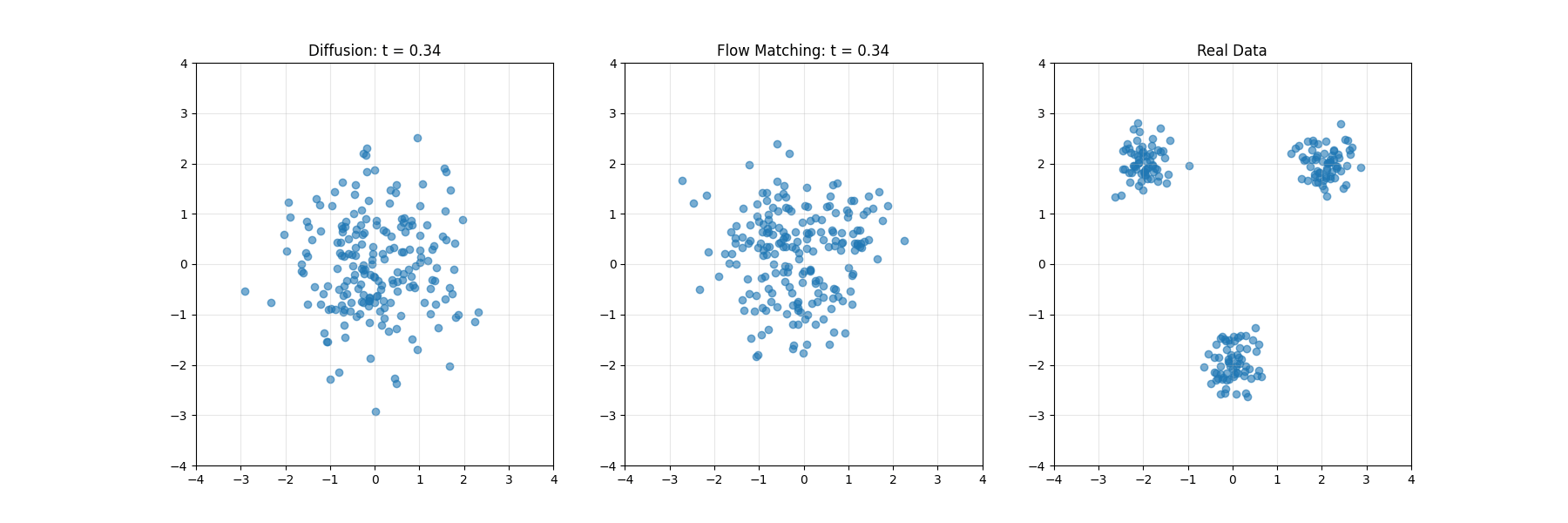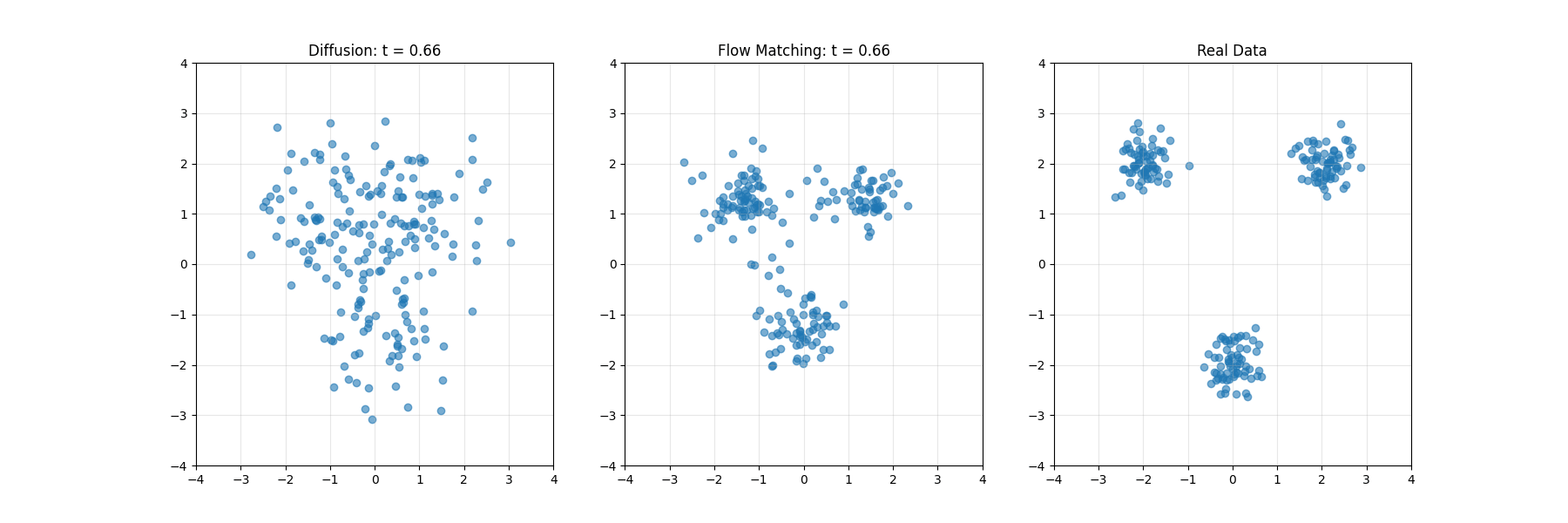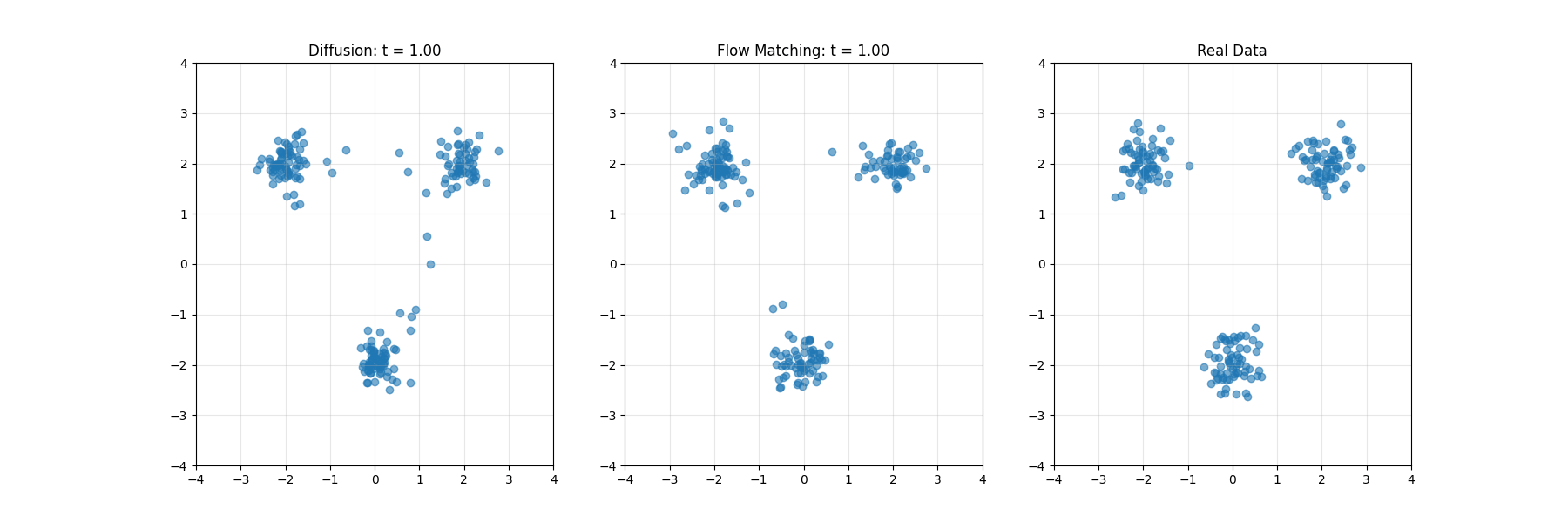
生成AI的两大范式:扩散模型与Flow Matching的理论基础与技术比较
本文系统对比了扩散模型与Flow Matching两种生成模型技术。扩散模型通过逐步添加噪声再逆转过程生成数据,类比为沙堡的侵蚀与重建;Flow Matching构建分布间连续路径的速度场,如同矢量导航系统。两者在数学原理、训练动态及应用上各有优劣:扩散模型适合复杂数据,Flow Matching采样效率更高。文章结合实例解析两者的差异与联系,并探讨其在图像、音频等领域的实际应用,为生成建模提供了全面视角。
淘宝图片搜索API(taobao.item_search_img)
淘宝图片搜索API是阿里基于深度学习的视觉检索服务,支持以图搜同款/相似商品,毫秒级响应、高准确率。提供商品、交易、店铺等结构化数据,适配选品、同款监控、智能上架等场景,合规高效,助力电商数字化升级。(239字)
NumPy技术文档:科学计算的基石
本教程系统讲解NumPy核心知识:从环境搭建与Hello World入门,到ndarray、广播机制、向量化运算三大核心概念;通过销售额分析实战,涵盖统计计算、移动平均、异常检测等典型应用;并总结最佳实践、常见陷阱及进阶方向,助你高效掌握科学计算基石。
机器学习:模型训练术语大扫盲——别再混淆Step、Epoch和Iter等
本文用通俗类比讲清机器学习核心术语:Epoch是完整训练一轮,Batch Size是每次训练的数据量,Step/Iter是每批数据处理及参数更新的最小单位。结合学习率、损失值、过拟合等概念,帮你快速掌握训练过程关键要点,打通术语任督二脉。(238字)
Linux(CentOS7.5) 安装部署 Python3.6(超详细!包含 Yum 源配置!)
该指南介绍了在Linux系统中配置Yum源和安装Python3的步骤。首先,通过`yum install`和`wget`命令更新和备份Yum源,并从阿里云获取CentOS和EPEL的repo文件。接着,清理和更新Yum缓存。然后,下载Python3源代码包,推荐使用阿里云镜像加速。解压后,安装必要的依赖,如gcc。在配置和编译Python3时,可能需要解决缺少C编译器的问题。完成安装后,创建Python3和pip3的软链接,并更新环境变量。最后,验证Python3安装成功,并可选地升级pip和配置pip源以提高包下载速度。
超详细!JetBrains Rider 2025.1 安装到能用,激活 + 安装步骤—附安装包
JetBrains Rider 2025.1 是全能型跨平台全栈 IDE,深度集成 AI 编码助手,支持 .NET 9、Unity 2025、Blazor 等最新技术,覆盖 C#、Python、Go 等 20+ 语言,赋能游戏、云原生与微服务开发,实现 AI 辅助生成、调试、测试与文档一体化。
2025 最新史上最全 Java 面试题独家整理带详细答案及解析
本文从Java基础、面向对象、多线程与并发等方面详细解析常见面试题及答案,并结合实际应用帮助理解。内容涵盖基本数据类型、自动装箱拆箱、String类区别,面向对象三大特性(封装、继承、多态),线程创建与安全问题解决方法,以及集合框架如ArrayList与LinkedList的对比和HashMap工作原理。适合准备面试或深入学习Java的开发者参考。附代码获取链接:[点此下载](https://pan.quark.cn/s/14fcf913bae6)。
Ubuntu 20.04 卸载与安装 MySQL 5.7 详细教程
该文档提供了在Ubuntu上卸载和安装MySQL 5.7的步骤。首先,通过`apt`命令卸载所有MySQL相关软件包及配置。然后,下载特定版本(5.7.32)的MySQL安装包,解压并安装所需依赖。接着,按照特定顺序安装解压后的deb包,并在安装过程中设置root用户的密码。安装完成后,启动MySQL服务,连接数据库并验证。最后,提到了开启GTID和二进制日志的配置方法。
数字孪生核心技术揭秘(三):倾斜摄影
对真实世界的自动化三维重建一直是CG/CV行业前赴后继不断尝试解决的难题;目前业内的进展,对于微型场景如单个饮料瓶等物体,结合AI已经可以实现语义化切割的自动三维重建,媲美人工建模。但是对于室外大场景的自动三维重建,从算法到采集硬件等等,都还未能做到类似微型场景的理想水平。 目前,倾斜摄影虽然在模型语义化分割、模型精度等方面不太完美,但是在贴近真实世界、过程自动化、实施成本、整体技术链成熟度等方面,已经是市面上最理想的低成本大规模三维重建技术方案。 随着国家政策的鼓励和“全景中国”的推进,预计倾斜摄影将会成为数字孪生项目的主流三维模型来源之一。

【DSW Gallery】COMMON_IO使用指南
COMMON_IO模块提供了TableReader和TableWriter两个接口,使用TableReader可以读取ODPS Table中的数据,使用TableWriter可以将数据写入ODPS Table。
向量数据库实战:从“看起来能用”到“真的能用”,中间隔着一堆坑
本文揭示向量数据库实战的七大关键陷阱:选型前需明确业务本质(模糊匹配 or 精确查询?);embedding 比数据库本身更重要,决定语义“世界观”;文档切分是核心工程,非辅助步骤;建库成功≠可用,TopK 准确率会随数据演进失效;“相似但不可用”是常态,必须引入 rerank;需建立可追溯的bad case排查路径;向量库是长期系统,非一次性组件。核心结论:难在“用对”,不在“用上”。
10 万文档 RAG 落地实战:从 Demo 到生产,我踩过的所有坑
本文分享10万级文档RAG系统从Demo到生产的实战经验,剖析检索慢、召回率低、部署复杂三大痛点,涵盖文档切分、Embedding选型、向量库优化、重排序与生成约束等关键步骤,并提供可落地的工程方案与评估方法,助力构建高效、稳定的企业级RAG系统。
大模型产生幻觉的原因,如何解决?
大模型“幻觉”指AI生成看似合理但错误或虚构的信息,源于其概率预测机制、训练数据缺陷及缺乏事实核查能力。可通过RAG、微调、联网检索、自我核查等方法降低幻觉风险,提升输出准确性与可靠性。(238字)
推荐2款免费开源的标注工具,支持大模型对话标注
【LabelLLM】一款开源免费的大模型对话标注平台,专为优化大型语言模型的数据标注过程设计。支持灵活配置与多模态数据(音频、图像、视频),具备全面任务管理和AI辅助标注功能,大幅提升标注效率与准确性。了解更多请前往https://github.com/opendatalab/LabelLLM 【LabelU】一款轻量级开源标注工具,支持图像、视频、音频的高效标注。特色功能包括多功能图像处理、视频和音频分析等,简易灵活,支持多种数据格式输出。了解更多请前往https://github.com/opendatalab/labelU
如何绕过某讯手游保护系统并从内存中获取Unity3D引擎的Dll文件
通过动态分析了它的保护方法,通过改源码刷机的方法绕过了它的保护方案(也可通过hook libc.so中的execve函数绕过保护),接下来就可以直接使用GameGuardain这个神奇附加上去进行各种骚操作了。这里主要讲一下如何去从内存中获取Assembly-CSharp.dll 和 Assembly-CSharp-fristpass.dll文件。
别只看 QPS:一级 NTP 时间服务器在工程现场到底靠什么兜底
本文以NTS-H-442002为例,剖析企业级Stratum 1时间服务器的关键设计:x86高并发架构保障稳定授时;GPS/北斗+蜂窝多源冗余提升可用性;高稳OCXO实现失锁后72小时<1ms守时精度;1PPS/10MHz/TOD物理接口满足硬同步需求;双电源、热备、加密与运维能力确保长期可靠。

阿里云 OpenLake:AI 时代的全模态、多引擎、一体化解决方案深度解析
阿里云徐晟详解OpenLake:构建全模态、多引擎、一体化智能数据体系,融合大数据与AI,支持湖仓一体、Agentic Data及AI搜索,助力企业降本增效、加速AI落地。(239字)
不懂向量数据库?一文讲透其原理与应用场景
向量数据库通过将文本、图像等非结构化数据转化为“数学指纹”(向量),实现语义级相似性检索。它突破传统数据库的精确匹配局限,支撑智能客服、推荐系统与RAG应用。核心原理是Embedding编码+高效索引(如HNSW、IVF),支持亿级数据毫秒搜索。结合元数据过滤的混合查询,显著提升准确性。未来将迈向多模态融合与自适应智能检索,是AI时代不可或缺的基础设施。
AI 十大论文精讲(五):RAG——让大模型 “告别幻觉、实时更新” 的检索增强生成秘籍
本文解读AI十大核心论文之五——《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》。该论文提出RAG框架,通过“检索+生成”结合,解决大模型知识更新难、易幻觉、缺溯源等问题,实现小模型高效利用外部知识库,成为当前大模型落地的关键技术。
基于HPC场景的集群任务调度系统LSF/SGE/Slurm/PBS
在HPC场景中,集群任务调度系统是资源管理和作业调度的核心工具。LSF、SGE、Slurm和PBS是主流调度系统。LSF适合大规模企业级集群,提供高可靠性和混合云支持;SGE为经典开源系统,适用于中小规模集群;Slurm成为HPC领域事实标准,支持多架构和容器化;PBS兼具商业和开源版本,擅长拓扑感知调度。选型建议:超大规模科研用Slurm,企业生产环境用LSF/PBS Pro,混合云需求选LSF/PBS Pro,传统小型集群用SGE/Slurm。当前趋势显示Slurm在TOP500系统中占比超60%,而商业系统在金融、制造等领域保持优势。
前端大模型入门(三):编码(Tokenizer)和嵌入(Embedding)解析 - llm的输入
本文介绍了大规模语言模型(LLM)中的两个核心概念:Tokenizer和Embedding。Tokenizer将文本转换为模型可处理的数字ID,而Embedding则将这些ID转化为能捕捉语义关系的稠密向量。文章通过具体示例和代码展示了两者的实现方法,帮助读者理解其基本原理和应用场景。
Hive 特殊的数据类型 Array、Map、Struct
在Hive中,`Array`、`Map`和`Struct`是三种特殊的数据类型。`Array`用于存储相同类型的列表,如`select array(1, "1", 2, 3, 4, 5)`会产生一个整数数组。`Map`是键值对集合,键值类型需一致,如`select map(1, 2, 3, "4")`会产生一个整数到整数的映射。`Struct`表示结构体,有固定数量和类型的字段,如`select struct(1, 2, 3, 4)`创建一个无名结构体。这些类型支持嵌套使用,允许更复杂的结构数据存储。例如,可以创建一个包含用户结构体的数组来存储多用户信息
若无 DNS 与代理 IP,我们的上网体验会崩塌吗?
DNS是互联网“快递员”,负责将域名精准解析为IP地址;代理IP则是“神秘信使”,隐匿真实身份、中转请求,保障隐私与访问自由。二者协同如接力赛:DNS先定位代理,代理再查目标IP,共同构建高效、安全、灵活的网络访问通路。
StarRocks + Paimon: 构建 Lakehouse Native 数据引擎
12月10日,Streaming Lakehouse Meetup Online EP.2重磅回归,聚焦StarRocks与Apache Paimon深度集成,探讨Lakehouse Native数据引擎的构建。活动涵盖架构统一、多源联邦分析、性能优化及可观测性提升,助力企业打造高效实时湖仓一体平台。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。


