









推理降本与提升资源效率的实践
本课程从业务角度探讨大模型推理部署及资源利用率提升。首先分析大模型与GPU发展趋势,包括模型开源、规模增长及多模态能力增强;其次介绍高效部署大模型推理业务的步骤,涵盖业务场景选择、架构优化及显存规划;接着讲解如何通过DeepCPU-LLM框架和DeepNCCL通讯库优化推理效率;最后探讨通过KuberGPU实现细粒度GPU资源管理,提升整体资源利用率,降低推理成本。
基于阿里云AI购物助手解决方案的深度评测
阿里云推出的AI购物助手解决方案,采用模块化架构,涵盖智能对话引擎、商品知识图谱和个性化推荐引擎。评测显示其在智能咨询问答、个性化推荐和多模态交互方面表现出色,准确率高且响应迅速。改进建议包括提升复杂问题理解、简化推荐过程及优化话术。总体评价认为该方案技术先进,应用效果好,能显著提升电商购物体验并降低运营成本。

Flink 三种时间窗口、窗口处理函数使用及案例
Flink 是处理无界数据流的强大工具,提供了丰富的窗口机制。本文介绍了三种时间窗口(滚动窗口、滑动窗口和会话窗口)及其使用方法,包括时间窗口的概念、窗口处理函数的使用和实际案例。通过这些机制,可以灵活地对数据流进行分析和计算,满足不同的业务需求。
从行业痛点到AI前沿:揭秘AGI时代企业培训的终极之选
近几年接触到的各类培训合作方越来越多,从国际咨询巨头、互联网科技培训平台,到本土独角兽型的专业培训公司;从专攻新技术与创新场景的培训团队,到深谙传统行业痛点的咨询顾问。作为一名在央企、国企、上市公司人力资源培训条线深耕多年的HR负责人,深知在这片竞争激烈的培训服务蓝海中,寻找高质、高效的合作伙伴并不简单,因为企业培训的逻辑正在悄然改变。

Apache Flink错误处理实战手册:2年生产环境调试经验总结
本文由 Ververica 客户成功经理 Naci Simsek 撰写,基于其在多个行业 Flink 项目中的实战经验,总结了 Apache Flink 生产环境中常见的三大典型问题及其解决方案。内容涵盖 Kafka 连接器迁移导致的状态管理问题、任务槽负载不均问题以及 Kryo 序列化引发的性能陷阱,旨在帮助企业开发者避免常见误区,提升实时流处理系统的稳定性与性能。
2025 年最新 Java 学习路线图含实操指南助你高效入门 Java 编程掌握核心技能
2025年最新Java学习路线图,涵盖基础环境搭建、核心特性(如密封类、虚拟线程)、模块化开发、响应式编程、主流框架(Spring Boot 3、Spring Security 6)、数据库操作(JPA + Hibernate 6)及微服务实战,助你掌握企业级开发技能。

Dots.ocr:告别复杂多模块架构,1.7B参数单一模型统一处理所有OCR任务22
Dots.ocr 是一款仅1.7B参数的视觉语言模型,正在重塑文档处理技术。它将布局检测、文本识别、阅读顺序理解和数学公式解析等任务统一于单一架构,突破传统OCR多模块流水线的限制。在多项基准测试中,其表现超越大参数模型,展现出“小而精”的实用价值,标志着OCR技术向高效、统一、灵活方向演进。
Java 大视界 -- Java 大数据机器学习模型在舆情分析中的情感倾向判断与话题追踪(185)
本篇文章深入探讨了Java大数据与机器学习在舆情分析中的应用,重点介绍了情感倾向判断与话题追踪的技术实现。通过实际案例,展示了如何利用Java生态工具如Hadoop、Hive、Weka和Deeplearning4j进行舆情数据处理、情感分类与趋势预测,揭示了其在企业品牌管理与政府决策中的重要价值。文章还展望了多模态融合、实时性提升及个性化服务等未来发展方向。
DataWorks 千万级任务调度与全链路集成开发治理赋能智能驾驶技术突破
智能驾驶数据预处理面临数据孤岛、任务爆炸与开发运维一体化三大挑战。DataWorks提供一站式的解决方案,支持千万级任务调度、多源数据集成及全链路数据开发,助力智能驾驶模型数据处理与模型训练高效落地。
AI是如何收集体育数据的?从摄像头到算法,揭秘赛场背后的“数字间谍网“!
⚽ 你是否好奇:AI如何知道哈兰德每秒跑多快?教练的平板为何比裁判还清楚谁偷懒?本文揭秘AI收集体育数据的“黑科技”:视觉追踪、传感器网络、数据清洗与高阶分析。从高速摄像机捕捉梅西肌肉抖动,到GPS背心记录姆巴佩冲刺速度;从表情识别判断装伤,到量子计算模拟战术可能,AI正让体育更透明、精准。未来已来,2030年世界杯或将实现AI替代球探、裁判甚至教练!你认为AI数据收集算侵犯隐私吗?最想统计哪些奇葩指标?留言互动吧!
大数据≠大样本:基于Spark的特征降维实战(提升10倍训练效率)
本文探讨了大数据场景下降维的核心问题与解决方案,重点分析了“维度灾难”对模型性能的影响及特征冗余的陷阱。通过数学证明与实际案例,揭示高维空间中样本稀疏性问题,并提出基于Spark的分布式降维技术选型与优化策略。文章详细展示了PCA在亿级用户画像中的应用,包括数据准备、核心实现与效果评估,同时深入探讨了协方差矩阵计算与特征值分解的并行优化方法。此外,还介绍了动态维度调整、非线性特征处理及降维与其他AI技术的协同效应,为生产环境提供了最佳实践指南。最终总结出降维的本质与工程实践原则,展望未来发展方向。
国内快递地址解析技术的工作原理详解
随着电商和快递行业快速发展,非结构化地址问题日益突出,如字段混杂、拼写错误等,传统方式难以高效处理。为此,探数平台推出基于NLP和地理信息的快递地址解析API,可将原始地址文本解析为标准结构化字段(如省、市、区、街道等),并支持收件人姓名与电话提取。 技术上,该API采用深度学习模型(如BERT、BiLSTM)进行语义理解,结合地址知识图谱实现纠错与补全。服务支持SaaS调用或私有化部署,性能稳定,适用于各类前端场景。通过地址结构化处理,企业可显著提升订单处理效率,减少配送错误,优化用户体验,助力全链路智能化升级。无论是电商平台还是物流系统,均可从中受益。
基于机器学习的数据分析:PLC采集的生产数据预测设备故障模型
本文介绍如何利用Python和Scikit-learn构建基于PLC数据的设备故障预测模型。通过实时采集温度、振动、电流等参数,进行数据预处理和特征提取,选择合适的机器学习模型(如随机森林、XGBoost),并优化模型性能。文章还分享了边缘计算部署方案及常见问题排查,强调模型预测应结合定期维护,确保系统稳定运行。
阿里万相重磅开源,人工智能平台PAI一键部署教程来啦
阿里云视频生成大模型万相2.1(Wan)重磅开源!Wan2.1 在处理复杂运动、还原真实物理规律、提升影视质感以及优化指令遵循方面具有显著的优势,轻松实现高质量的视频生成。同时,万相还支持业内领先的中英文文字特效生成,满足广告、短视频等领域的创意需求。阿里云人工智能平台 PAI-Model Gallery 现已经支持一键部署阿里万相重磅开源的4个模型,可获得您的专属阿里万相服务。
Transformer 学习笔记 | Seq2Seq,Encoder-Decoder,分词器tokenizer,attention,词嵌入
本文记录了学习Transformer过程中的笔记,介绍了Seq2Seq模型及其编码器-解码器结构。Seq2Seq模型通过将输入序列转化为上下文向量,再由解码器生成输出序列,适用于机器翻译、对话系统等任务。文章详细探讨了Seq2Seq的优势与局限,如信息压缩导致的细节丢失和短期记忆限制,并引入注意力机制来解决长序列处理问题。此外,还介绍了分词器(tokenizer)的工作原理及不同类型分词器的特点,以及词嵌入和Transformer架构的基础知识。文中包含大量图表和实例,帮助理解复杂的概念。参考资料来自多个权威来源,确保内容的准确性和全面性。
本地部署企业级自适应 RAG 应用的方法与实践
本文介绍了本地部署企业级自适应RAG(Adaptive Retrieval-Augmented Generation)应用的方法与实践。RAG结合信息检索与文本生成,广泛应用于问答、编程等领域。自适应RAG通过分类器评估查询复杂度,动态选择无检索、单步检索或多步检索策略,优化生成结果。其特点在于灵活性和适应性,能够根据输入情况调整检索和生成策略。核心技术包括检索策略的自适应、生成策略的自适应以及模型参数的自适应调整。通过实战,深入了解了RAG的工作原理和应用场景,并获得了宝贵经验。
新手零代码建站指南:3步搭建适配阿里云的企业官网
本文介绍新手用 PageAdmin CMS 搭建企业官网的核心流程:先准备阿里云资源(域名注册备案、2 核 4G 入门级 ECS、LNMP/LAMP 环境)及下载该 CMS;再分 3 步搭建(部署程序到 ECS、配置数据库完成安装、选模板填内容 + 域名解析与 SSL 配置);上线后需做数据备份、安全优化与性能监控。
Python | 网格搜索参数优化的XGBoost+SHAP可解释性分析回归预测及可视化算法
本教程将推出Python实现的XGBoost回归预测,结合网格搜索调参与SHAP可解释性分析,涵盖数据处理、模型训练、可视化及结果保存,助力科研论文提升模型可解释性,附完整代码与保姆级环境配置指南。
GEO优化:AI时代的流量新密码
生成式引擎优化(GEO)是针对AI驱动的搜索引擎(如ChatGPT、DeepSeek、Perplexity等)进行内容优化的策略,旨在提升品牌在AI生成回答中的可见性。 一、 GEO优化的核心框架:SEO + RAG GEO优化主要围绕两个核心环节展开,因为AI搜索通常分为“检索”和“生成”两步。 1. SEO (S…

AAAI2025!北理工团队提出FBRT-YOLO:面向实时航拍图像更快更好的目标检测 |计算机视觉|目标检测
FBRT-YOLO提出专用于航拍图像的实时目标检测模型,通过轻量化设计、增强多尺度融合与小目标优化,在保证高精度的同时显著提升速度,实现复杂场景下更优的性能平衡。
阿里云 Elasticsearch 的 AI 革新:高性能、低成本、智能化的搜索新纪元
本文介绍了数智化浪潮下, 阿里云 Elasticsearch 打通了 云原生内核优化、RAG 闭环方案、云原生推理平台 三大能力模块,实现了从底层到应用的全链路升级,助力企业构建面向未来的智能搜索中枢。
淘宝API图片搜索 | 天猫商品图片识别 | 一键上传找相似商品
淘宝图片搜索API(拍立淘)基于图像识别与深度学习技术,支持通过图片查找相似商品,适用于比价、找同款等场景。提供精准匹配、多参数调节,助力开发者打造智能购物应用,提升搜索效率与用户体验。
编写第一个MCP Server之Hello world
本文介绍如何使用Node.js编写一个简单的MCP Server——“Echo”服务。通过环境搭建、项目初始化、代码实现及验证,完成MCP服务的开发与调用测试,助力快速入门MCP协议开发。
基于springboot的大学生心理咨询管理系统
本研究针对大学生心理健康问题,构建基于Spring Boot、Vue等技术的心理咨询管理系统,实现心理数据电子化、智能化管理。系统支持在线预约、匿名咨询、心理测评与数据分析,兼具隐私保护与危机预警功能,提升服务可及性与干预精准度,助力高校心理健康工作科学化发展。
Mixture of Experts架构的简要解析
Mixture of Experts(MoE)架构起源于1991年,其核心思想是通过多个专门化的“专家”网络处理输入的不同部分,并由门控网络动态组合输出。这种架构实现了稀疏激活,仅激活部分专家,从而在模型规模与计算成本之间取得平衡。MoE的关键在于门控机制的设计,如线性门控、噪声Top-K门控等,确保模型能根据输入特征自适应选择专家。
大语言模型的核心算法——简要解析
大语言模型的核心算法基于Transformer架构,以自注意力机制为核心,通过Q、K、V矩阵动态捕捉序列内部关系。多头注意力增强模型表达能力,位置编码(如RoPE)解决顺序信息问题。Flash Attention优化计算效率,GQA平衡性能与资源消耗。训练上,DPO替代RLHF提升效率,MoE架构实现参数扩展,Constitutional AI实现自监督对齐。整体技术推动模型在长序列、低资源下的性能突破。
1688查询榜单列表API详解
1688榜单API提供实时热销、新品等商品榜单数据,支持20+品类及40+字段筛选,适用于选品与市场分析。每小时更新,响应迅速。提供Python调用示例,开发者可快速集成。
Apache InLong:构建10万亿级数据管道的全场景集成框架
Apache InLong(应龙)是一站式、全场景海量数据集成框架,支持数据接入、同步与订阅,具备自动、安全、可靠和高性能的数据传输能力。源自腾讯大数据团队,现为 Apache 顶级项目,广泛应用于广告、支付、社交等多个领域,助力企业构建高效数据分析与应用体系。
抖音集团基于Paimon的流式数据湖应用实践
本文整理自抖音集团数据工程师在Flink Forward Asia 2024的分享,围绕流式湖仓架构的背景、实践与未来展望展开。内容涵盖实时数仓架构演进、Paimon的应用与优化,以及在长周期指标计算和大流量场景下的落地实践经验。

Apache Iceberg数据湖高级特性及性能调优
性能调优涵盖索引优化、排序策略与元数据管理。通过布隆过滤器、位图索引等提升查询效率,结合文件内/间排序优化I/O与压缩,辅以Z-Order实现多维数据聚集。同时,合理配置元数据缓存与清单合并,加速查询规划。适用于点查、全表扫描及高并发写入场景,显著提升系统性能与资源利用率。

信息检索重排序技术深度解析:Cross-Encoders、ColBERT与大语言模型方法的实践对比
本文将深入分析三种主流的重排序技术:Cross-Encoders(交叉编码器)、ColBERT以及基于大语言模型的重排序器,并详细阐述各方案在实际应用中的性能表现、成本考量以及适用场景。
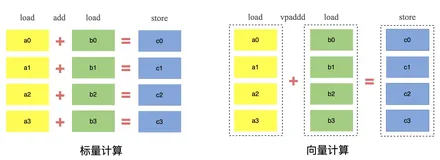
流批一体向量化引擎Flex
本文整理自蚂蚁集团技术专家刘勇在Flink Forward Asia 2024上的分享,聚焦流批一体向量化引擎的背景、架构及未来规划。内容涵盖向量化计算的基础原理(如SIMD指令)、现有技术现状,以及蚂蚁在Flink 1.18中引入的C++开发向量化计算实践。通过Flex引擎(基于Velox构建),实现比原生执行引擎更高的吞吐量和更低的成本。文章还详细介绍了功能性优化、正确性验证、易用性和稳定性建设,并展示了线上作业性能提升的具体数据(平均提升75%,最佳达14倍)。最后展望了未来规划,包括全新数据转换层、与Paimon结合及支持更多算子和SIMD函数。
1688商品详情API接口指南
1688 商品详情 API 是阿里巴巴提供的开发者接口,用于获取 1688 平台商品的详细信息,包括 ID、标题、价格、销量、评价、SKU 等。通过构造 HTTP 请求并使用 App Key 和 App Secret 验证,可实现安全调用。该接口适用于电商网站、内容管理系统、数据分析工具及第三方开发场景,助力商品信息同步、市场分析与应用开发。
企业级AI搜索解决方案:阿里云AI搜索开放平台
本文介绍了 阿里云 AI 搜索开放平台作提供丰富的 AI 搜索组件化服务,兼容主流开发框架 LangChain和 LlamaIndex,支持搜索专属大模型、百炼等大模型服务,以及 Elasticsearch、Havenask 等开源引擎。用户可灵活调用多模态数据解析、大语言模型、效果测评等数十个服务,实现智能搜索、检索增强生成(RAG)、多模态搜索等场景的搭建。
淘宝商品列表API接口攻略(附代码示例)
淘宝商品列表API接口用于获取淘宝商品信息,支持按关键词、类目、价格区间等条件查询,返回商品标题、价格、销量等数据。通过构造HTTP请求并解析JSON响应,可提取所需信息。示例代码展示了使用Python调用该API的流程,包括生成签名和请求参数配置,方便开发者快速上手。

PINN应用案例:神经网络求解热扩散方程高质量近似解
本文探讨了物理信息神经网络(PINN)在求解一维热扩散方程中的应用,对比分析了多层感知器(MLP)、残差网络(ResNet)和Wang2020架构的性能。PINN通过构建损失函数整合偏微分方程残差、边界条件和初始条件,实现对物理系统的近似求解。实验结果表明,传统架构如MLP和ResNet虽能大致还原解析解,但在部分区域存在显著偏差;而Wang2020架构因专门设计以应对PINN训练挑战,表现更为优越,与解析解高度一致。研究还揭示了PINN训练中“平台期后突变”的优化特性,并提出通过构造满足约束条件的网络架构以简化多目标优化问题,为未来研究提供了新方向。
云上玩转Qwen3系列之二:PAI-LangStudio搭建联网搜索和RAG增强问答应用
本文详细介绍了如何使用 PAI-LangStudio 和 Qwen3 构建基于 RAG 和联网搜索 的 AI 智能问答应用。该应用通过将 RAG、web search 等技术和阿里最新的推理模型 Qwen3 编排在一个应用流中,为大模型提供了额外的联网搜索和特定领域知识库检索的能力,提升了智能回答的效果,减少了幻觉。开发者可以基于该模板进行灵活扩展和二次开发,以满足特定场景的需求。
浏览器自动化检测对抗:修改navigator.webdriver属性的底层实现
本文介绍了如何构建一个反检测爬虫以爬取Amazon商品信息。通过使用`undetected-chromedriver`规避自动化检测,修改`navigator.webdriver`属性隐藏痕迹,并结合代理、Cookie和User-Agent技术,实现稳定的数据采集。代码包含浏览器配置、无痕设置、关键词搜索及数据提取等功能,同时提供常见问题解决方法,助你高效应对反爬策略。
深入研究:京东图片搜索商品API详解
京东图片搜索商品API简介:在电商快速发展的背景下,用户需求日益多样化。为提升购物体验,京东推出图片搜索商品API,通过上传商品图片(如实物图或宣传图),利用图像识别技术匹配京东商品库,返回相似商品的信息(如名称、价格、销量等)。该API采用HTTP POST请求方式,支持JPEG、PNG等常见图片格式,并可设置分类范围和结果数量限制等可选参数,助力开发者实现更精准的商品搜索,优化用户体验,同时为数据分析与个性化推荐提供支持。本文详细介绍了其功能、使用方法及Python请求示例。
PeptideBERT:基于Transformer用于肽性质预测的语言模型
本文介绍了PeptideBERT模型及其在昇腾设备上的部署方法。PeptideBERT是一种基于Transformer架构的蛋白质语言模型,通过微调预训练模型ProtBERT,可预测肽的溶血性、溶解性和抗非特异性吸附性等关键性质。其输入表示包括词嵌入、物理化学属性编码和位置编码,并采用多头自注意力机制捕捉序列依赖关系。

Apache Flink 2.0.0: 实时数据处理的新纪元
Apache Flink 2.0.0 正式发布!这是自 Flink 1.0 发布九年以来的首次重大更新,凝聚了社区两年的努力。此版本引入分离式状态管理、物化表、流批统一等创新功能,优化云原生环境下的资源利用与性能表现,并强化了对人工智能工作流的支持。同时,Flink 2.0 对 API 和配置进行了全面清理,移除了过时组件,为未来的发展奠定了坚实基础。感谢 165 位贡献者的辛勤付出,共同推动实时计算进入新纪元!
体育应用怎么通过API接口接入数据源与直播源
本文介绍了体育类应用接入数据源与直播源的API接口方案。主要包括:1) 数据源API接入,涉及选择提供商、接入流程及常见数据类型;2) 直播源接入,涵盖直播源类型、提供商和技术方案;3) 技术实现要点,如数据缓存、实时更新机制和安全性考虑;4) 成本优化建议。附有HLS播放示例及Node.js完整集成代码,帮助开发者高效实现体育应用功能。
强化学习:时间差分(TD)(SARSA算法和Q-Learning算法)(看不懂算我输专栏)——手把手教你入门强化学习(六)
本文介绍了时间差分法(TD)中的两种经典算法:SARSA和Q-Learning。二者均为无模型强化学习方法,通过与环境交互估算动作价值函数。SARSA是On-Policy算法,采用ε-greedy策略进行动作选择和评估;而Q-Learning为Off-Policy算法,评估时选取下一状态中估值最大的动作。相比动态规划和蒙特卡洛方法,TD算法结合了自举更新与样本更新的优势,实现边行动边学习。文章通过生动的例子解释了两者的差异,并提供了伪代码帮助理解。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
