编辑
编辑
👨🏻🎓博主介绍:大家好,我是芝士味的椒盐,一名在校大学生,热爱分享知识,很高兴在这里认识大家🌟
🌈擅长领域:Java、大数据、运维、电子
🙏🏻如果本文章各位小伙伴们有帮助的话,🍭关注+👍🏻点赞+🗣评论+📦收藏,相应的有空了我也会回访,互助!!!
🤝另本人水平有限,旨在创作简单易懂的文章,在文章描述时如有错,恳请各位大佬指正,在此感谢!!!
大数据业务分为两大:实时计算,离线计算
实时计算:实时对来到的数据进行及时计算
离线计算:对堆积已久的数据进行计算(MapReduce(效率低)、Hive)
Hive提供了 一种类SQL的操作进行查询统计
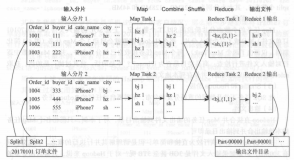
Hive的底层:是基于MapReduce的引擎,会将查询语句转换为Map阶段和Reduce阶段
MR、Hive:离线计算处理模块的技术
Hive特点:
- 可扩展性———>Hive自由扩展集群的规模,一般无需重启服务
- 延展性————>Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
- 容错性————>节点宕机,SQL任然可以完成执行
数据仓库(DataWarehouse):可以包含多个数据库
数据库:包含多个表
Hive与传统数据库的对比:
 编辑
编辑
安装Hive
Hive常用交互命令:
- "-e" 不进入hive的交互窗口执行sql
hive -e "show databases;"

- “-f” 执行脚本中的sql语句
- 编写selectdata.sql脚本
use testdatas; select * from stu;

- 执行sql脚本
hive -f selectdata.sql

- 将sql执行的结果写入文件中
hive -f selectdata.sql >> ./restult1.txt

Hive其他命令操作:
- 退出hive窗口(老版本有区别,新版没有区别):
exit;#先隐形提交数据,再退出 quit;不提交数据,退出

- 在hive cli命令窗口中查看hdfs文件系统
- 在hive cli命令窗口中查看本地文件系统
- 查看在hive中输入的所有的历史命令
cat /home/当前用户/.hivehistory

Hive数据仓库位置配置:
- 配置Default数据仓库的位置,默认是在hdfs上的:/user/hive/warehouse/(预先存在的路径)下,可以将下面的标签片段编写到hive-site.xml中就可以改变Default数据创库的位置
<property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> <description>location of default database for the warehouse</description> </property>

- 切记配置完Default数据创库的位置,需要设置同组可读的权限
hadoop fs -chmod g+w /user/hive/warehouse

- 后台信息查询配置hive-site.xml,就可以实现显示当前数据库,以及查询表的头信息配置
<property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property>

Hive运行日志信息配置:
- 在/tmp/hadoop目录下可以看到hive的日志文件,进行排错,hive.log、hive.log.2020-09-27....
- 拷贝并修改hive-log4j.properties. template——>hive-log4j.properties
#可以修改日志存储的位置 hive.log.dir=/usr/local/src/hive/logs #可以修改日志打印日志时间的格式 log4j.appender.DRFA.DatePattern=.yyyy-MM-dd

参数配置方式:
- 查看当前所有的配置信息
hive>set ;

- 参数配置的三种方式
- 配置文件方式
- 默认配置文件:hive-default.xml
- 用户自定义配置文件:hive-site.xml(会覆盖默认配置)
- 命令行参数方式
- 启动hive时,在命令行添加-hiveconf param=value来进行参数设定(
本次有效) - 查看参数设置:
hive(default)>set mapred.reduce.tasks;

- 参数声明方式
可以在HQL中使用SET关键字设定参数(本次有效)
hive(Default)>set mapred.reduce.tasks=100

- 三种配置的优先级:配置文件<命令行参数<参数声明
Hive的基本概念:
- 用户可以在Hive中执行Hadoop的fs命令,如“dfs -ls /;”查询hdfs上存储的数据
- 在hive中使用hadoop命令比直接在bash shell中执行hadoop dfs更加高效,在hive中是会在同一个进程中执行这些命令,而在bash shell执行则会每次启动一个JVM的新实例。
Hive中的基本数据类型:
- Hive v0.8.0版本中增加了时间戳数据类型和二进制数组数据类型

 编辑
编辑

 编辑
编辑
- 所有的数据类型都是对Java中的数据类型接口的实现
- 新增数据类型TIMESTAMP的值可以是整数,也就是距离Unix新纪元时 间( 1 970年1月1日, 午夜12点)的秒数;也可以是浮点数,即距离 Unix新纪元时间的秒数,精确到纳秒(小数点后保留9位数) ; 还可以 是字符串,即JDBC所约定的时间字符串格式,格式为YYYY-MM-DD hh:mm:s.ffffff。
- TIMESTAMPS表示的是UTC时间。Hive本身提供了不同时区间互相转 换的内置函数,也就是to_ utctimestamp函数和from utc_ timestamp函数
- BINARY数据类型和很多关系型数据库中的VARBINARY数据类型是 类似的,但其和BLOB数据类型并不相同。因为BINARY的列是存储在 记录中的,而BLOB则不同。BINARY可以在记录中包含任意字节,这 样可以防止Hive尝试将其作为数字,字待串等进行解析。
- String相当于varchar,可以单个存储2G的字符数
操作
- 创建stu表
#**row format delimited----》表示对行格式化 #fields terminated by '\\t'----》表示参数按什么分割这里,这为一个制表符** **create table stu(id bigint,name string ,score double,age int) row format delimited fields terminated by '\\t';**

- 在/home/hadoop/databasesdata/下创建stu.txt,并加入以下内容
20192023 Marry 99.9 18 20192022 Lucrh 78 22 20192021 Marry 89.0 99

- tips:数据和数据之间要严格按照创建表时指定的数据分割格式,不然之后加载进表中会出现
NULL值
- 将数据加载进stu表
load data local inpath '/home/hadoop/databasesdata/stu.txt' into table stu;

集合数据类型
- Hive中的列支持使用struct、map和array集合数据类型

 编辑
编辑
操作
- 创建star表
create table star(name string, friends array<string >, childern map<string, int>, address struct<street:string, city:string>) row format delimited fields terminated by ',' collection items terminated by '_' map keys terminated by ':' line terminated by '\\n';

- row format delimited fields terminated by ',':每行每条语句的分隔符
- collection items terminated by '_' :array的数据分隔符
- line terminated by '\n':行分隔符
类型转化
- Hive的原子数据类型可以进行隐式转化,可以正向转化,不会进行反向转化,如果传入的值不是低于属性的数据类型,而是高于其,则会直接报错,可以使用CAST进行操作,将不会进行报错。
隐式类型转换
- 任何类型都可以准换成一个更广的类型
TINYINT—>INT—>BIGINT - 所有整数类型、FLOAT和STRING都可以隐式转换成DOUBLE
- TINYINT、SMALLINT、INT都可以转换成FLOAT
- BOOLEAN不允许转换成其他类型
强制转换
例子:
- CAST('1' AS INT)是将字符串型‘1’转换成整数1,
- 如果强制类型转换失败,执行了CAST('X' AS INT) 表达式将返回空值NULL
DDL数据定义
创建数据库
- 创建的数据库默认是在/user/hive/warehouse/下
hive (default)> create database star;

- 使用not exitis判断是否预先已有数据库
hive (default)> create database if not exitis star;

- 创建数据库,并制定数据库在HDFS上存储的位置
create database if not exists kos location '/koss.db';

查询数据库
显示数据库
- 显示数据库
show databases;

- 过滤显示查询的数据库,*
show databases like 'ko*';

查询数据库详情
- 显示数据库信息
desc database star;

- 显示数据库详细信息,extended
desc database extended star;

切换当前数据库
use kos;

修改数据库
alter database kos set dbproperties('createtime'='20180818');

- tips:通过设置键值对的形式修改数据库的属性信息,
数据库其他的元数据都是不可以更改的,包括数据库名和数据库所在的目录位置,可以通过extend查看修改之后的信息
删除数据库
drop database kos;

- tips:可以采取if exists进行判断数据库是否存在,数据库不为空的情况下采取cascade命令将其删除
drop database kos cascade;

创建表
语法:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]

管理表
- 默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期,当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
- 普通表创建
create table if not exists student2( id int, name string ) row format delimited fields terminated by '\\t' stored as textfile location '/user/hive/warehouse/student2';

- 根据查询结果创表
create table if not exists restl as select * from stu;

- 根据已经存在的表结构创建表
create table if not exists re2 like stu;

- 查询表的类型
desc formatted stu;

外部表
- 因为表是外部表,所以Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉
案例:
- dept.txt
10 ACCOUNTING 1700 20 RESEARCH 1800 30 SALES 1900 40 OPERATIONS 1700

- emp.txt
7369 SMITH CLERK 7902 1980-12-17 800.00 20 7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30 7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30 7566 JONES MANAGER 7839 1981-4-2 2975.00 20 7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30 7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30 7782 CLARK MANAGER 7839 1981-6-9 2450.00 10 7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20 7839 KING PRESIDENT 1981-11-17 5000.00 10 7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30 7876 ADAMS CLERK 7788 1987-5-23 1100.00 20 7900 JAMES CLERK 7698 1981-12-3 950.00 30 7902 FORD ANALYST 7566 1981-12-3 3000.00 20 7934 MILLER CLERK 7782 1982-1-23 1300.00 10

- 建表语句(dept、emp)
create external table if not exists testdatas.dept(deptno int, deptname string, money int) row format delimited fields terminated by '\\t'; create external table if not exists testdatas.emp(empno int, empname string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) row format delimited fields terminated by '\\t';

- 加载数据进表中
load data local inpath '/home/hadoop/databasesdata/dept.txt' into table dept; load data local inpath '/home/hadoop/databasesdata/emp.txt' into table emp;

管理表和外部表的互相转换
- 首先查询表的类型使用
desc formatted stu;

- 修改内部表stu为外部表
alter table stu set tblproperties('EXTERNAL'='TRUE');

- 修改外部表stu为内部表
alter table stu set tblproperties('EXTERNAL'='FLASE');

分区表
- 分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。谓词下推(先where筛选)
- 创建分区表
create table depts_partition (dept int, dname string, loc string) partitioned by (month string) row format delimited fields terminated by '\\t';

- 加载数据到分区表中
load data local inpath '/home/hadoop/databasesdata/dept.txt' into table depts_partition partition(month='2020-9-29');

- 查询分区表中数据
select * from depts_partition where month='2020-9-23';

- 增加分区
#添加单个分区 alter table depts_partition add partition(month='2020-9-30'); #添加多个分区 alter table depts_partition add partition(month='2020-10-2') partition(month='2020-10-1');

- 删除分区
#删除单个分区 alter table depts_partition drop partition(month='2020-10-2'); #删除多个分区 alter table depts_partition drop partition(month='2020-10-2') partition(month='2020-10-1');

- 查看分区表中有分区
show partitions depts_partition;

- 查看分区结构
desc formatted depts_partition;

二级分区:
- 创建二级分区
create table kos_deptss_partition(dept int, dname string, loc string) partitioned by (month string, day string) row format delimited fields terminated by '\\t';

- 正常加载数据到分区
load data local inpath '/home/hadoop/databasesdata/dept.txt' into table kos_deptss_partition partition(month='1999-9',day='9');

- 把数据直接上传到分区目录,让分区和数据表产生关联的三种方式
- 方式一:上传数据后修复上传数据
hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=201709/day=12; hive (default)> dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=201709/day=12;

- 此时查询分区是查询不到的,需要修复分区
hive (default)> select * from dept_partition2 where month='201709' and day='12';

- 执行修复分区的命令
hive> msck repair table dept_partition2;

- 方式二:上传数据后添加分区
上传数据
ive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=201709/day=11; hive (default)> dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=201709/day=11;
 添加分区
添加分区
hive (default)> alter table dept_partition2 add partition(month='201709', day='11');

- 方式三:创建文件夹后load数据到分区
创建目录
hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=201709/day=10;
 上传数据
上传数据
hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=201709/day=10;

- 修改表
- 修改表名
alter table table_name rename to new_table_name

- 增加/修改/替换列信息
- 语法更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
 增加和替换列
增加和替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)

- 注:ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段。
- 例子:
查询结构
hive> desc dept_partition;
 添加列
添加列
hive (default)> alter table dept_partition add columns(deptdesc string);
 更新列
更新列
hive (default)> alter table dept_partition change column deptdesc desc int;
 替换列
替换列
hive (default)> alter table dept_partition change column deptdesc desc int;