作者:王晓龙 阿里云开源大数据平台技术专家
一、Delta Lake介绍

大数据平台架构发展至今,已经经历了三个阶段的技术演进:从最早的数仓,到数据湖+数仓的架构,再到最近两年的Lakehouse架构。

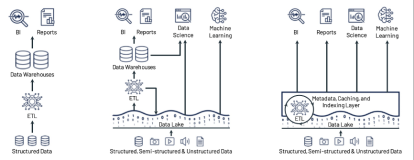
最早的数仓架构是Schema-on-write的设计。如上图,数据首先由关系型数据库经过ETL导入数据仓库里,可以做一些BI分析以及报表分析。它的底层是数据库技术,因此能够提供比较好的数据管理能力,比如能够支持 ACID事务,能够基于Schema-on-write在上游数据写入的时候提供比较强的Schema约束,以此保证数据的质量。
同时,基于它自身的诸多优化特性,数仓架构对分析型场景能够提供非常好的支持。但是支持的场景比较有限,基本局限于常用的分析场景。而在大数据时代,随着数据规模的逐渐增加,企业对于数据分析的场景要求越来越多,逐渐产生了一些高级的分析场景需求,比如数据科学类或者机器学习类的场景,而数据仓库对此类需求难以支持。
另外,数据仓库也无法支持半结构化以及非结构化的数据。

2003年前后,Hadoop面市。伴随着数据规模体量的爆炸式增长,我们对低成本存储的需求也愈发迫切。于是第二代大数据平台架构雏形初现。它以数据湖为基础,能够支持对结构化、非结构化以及半结构化数据的存储。与数据仓库相比,它是一种Schema-on-read的设计,数据能够比较高效地存入数据湖,但是会给下游的分析提供较高的负担。
因为数据在写入之前没有做校验,随着时间的推移,数据湖里的数据会变得越来越脏乱,数据治理的复杂度非常高。同时因为数据湖底层是以开放的数据格式存储在云对象存储上,云对象存储的一些特性会导致数据湖架构缺少像数仓一样的数据管理特性。另外因为云对象存储在大数据查询场景上的性能上不足,导致很多场景下都无法很好地体现数据湖的优势。

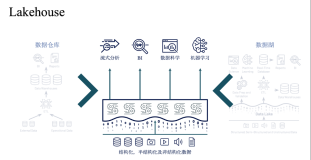
于是第三代大数据平台架构——Lakehouse应运而生。它在数据湖之上抽象出了事务管理层,能够提供传统数仓的一些数据管理特性,还可以针对云对象存储中的数据做一些数据的性能优化。从而能够针对大数据时代各种复杂的分析场景提供支持,且对于流批两种场景也能够提供统一的处理方式。

有了Lakehouse架构的背景之后,Delta Lake也应运而生,它是由Databricks开源的一个数据库解决方案,架构清晰简洁,能够提供比较可靠的保障。
上图呈现了Delta lake的Multi-hop Medallion架构,即通过多个表结构来提供不同分析场景的支持。数据可以通过streaming的方式流入Delta Lake,也可以使用batch方式导入。
Delta Lake里的表可以分为三类:
- 第一类:数据最先导入的表称为bronze table。direct事务的特性能够保证在bronze table中数据的可靠性,因此它是整个数据湖的source of truth(事实表)。某些场景可以直接读取bronze table。
- 第二类:如果对数据有更高的要求,希望对数据做一些清洗,可以通过silver表来实现。它的结构更清晰也更规范,能够支持一些机器学习或其他简单的分析场景。
- 第三类:如果分析对数据的质量要求非常严格,可以在Gold table的基础之上做进一步演进,特征抽取和聚合之后生成Gold table,可以做更高级别的分析。

Delta lake底层提供了一种基于事务日志的机制来实现ACID的事务特性,能够实现读写数据的一致性,同时提供较高质量的数据保证。
在ACID事务的基础之上,Delta lake提供了更多的数据管理及性能优化特性,比如时间回溯、数据版本等,能够基于它的事务日志回溯到某个时间或某个版本的数据;同时还可以实现数据的高效upsert和delete,以及可扩展的元数据管理的能力。
在大数据的场景下,元数据管理本身可能会成为一种负担,因为对于较大的表来说,元数据本身就能成为大数据。所以如何高效地支持元数据管理,也是对架构挑战。
Delta lake事务日志场景下,元数据是以文件形式存储在事务log里,因此可以借助Spark这种大数据引擎,来实现数据元数据的扩展性。同时Delta lake还能够提供统一的流批方式,可以以统一的方式对数据的注入提供支持,上述实现的前提是说因为Delta lake能够支持可串行化的隔离级别,实现一些典型的流式需求,比如CDC。
同时,为了保证数据湖中的数据质量,Delta lake也提供了Schema的强制约束以及自动演化的能力。
此外,在Delta lake的商业版本里,还提供了数据库中的数据布局自动优化的能力,同时实现了传统数仓数据库一系列性能优化特性,比如缓存、索引等优化能力。
二、发展回顾

Delta lake项目最早开源在2019年4月,事务、流批一体等最核心的功能在0.1版本都已实现。此后,Delta Lake便致力于易用性和开放性的方向在不断努力,Lakehouse也开放了更多技术在开源社区。
- 0.2-0.4版本:提供了对不同云对象存储的支持;0.3版本在API层面的能力也逐渐增强,同时支持了一些常见的DML操作;0.4版本支持了将parquet表格式直接转换成Delta。
- 0.5版本:Delta lake开始尝试对Spark之外的查询引擎提供读场景的支持,这也是社区第一次在Spark之外提供引擎的支持,也是Delta lake开放性目标的一部分;同时0,5版本还提供了一些优化的特性,以及通过SQL的方式直接将parque转成Delta 。
- 0.6版本:Delta Lake做了一些Schema的演化性支持,同时对merge性能也提供了进一步优化,对比如describe history的命令提供了更多metrics信息。
- 0.7版本:随着Spark3.0的开源,Delta lake提供了Spark3.0的兼容。并且基于Spark3.0提供了更多特性:在元数据层面,支持读取Hive metastore元数据,因为元数据本身是 transaction log事务日志的一部分,所以有了Hive metastore的支持,就能够与其他引擎比如presto去共享元数据;在易用性方面,从SQL层面提供了对dml的支持。
- 0.8版本:Delta lake主要贡献是在merge操作上提供了更多性能增强的特性,同时支持了VACUUM的并发删除能力。
- 2021年5月,Delta lake1.0版本正式发布。
纵观Delta lake的发展历程,可以清晰地看出,它一直坚定地朝着Everywhere——支持更多元、更开放的生态发展。
三、Delta Lake1.0+

上图展示了Delta lake 1.0的一些核心特性。

首先是Generated Columns特性,这里将以一个示例对特性做介绍。
大数据开发场景里有一个比较典型需求:对数据表做分区。比如对日期字段做分区,但是在写入表之前的原始数据里可能并没有日期字段,而是时间戳字段。如上图,eventTime本身是时间戳,但是数据中并没有eventDate的类型。那么应该如何做分区?
- 方案1:直接使用时间戳的字段做分区。时间戳是一个比较细粒度的字段,使用它来做会产生大量的分区,对于查询性能会造成非常大的影响。因此,此方案被排除。
- 方案2:数据写入表之前手动维护额外字段。比如从eventTime字段中抽取得到eventDate。但这需要人工维护字段,而但凡涉及到人工,就容易引入错误,尤其是多种数据源同时写入的情况,要求对多种数据源同时做转换,极易出现差错。
因此Delta Lake1.0提供了generated columns,它是一种特殊类型的列,它的值可以根据用户指定的函数自动生成。

可以通过如上图简单的SQL语法,将eventTime转换成date类型,从而生成 eventDate字段。整个过程自动完成的,用户只需要在最开始创建表的时候提供这个语法即可。

Delta lake1.0提供的第二个重要特性是Standalone。它的目标是可以在Spark之外对接更多引擎,但是诸如Presto、Flink等引擎本身并不需要依赖Spark,如果Delta lake只能强绑定Spark就违背了Delta lake开放性的目标。
于是社区推出了Standalone,它在jvm层面实现了对Delta lake事务协议的处理。有了Standalone,后面会有更多引擎接入进来。Standalone最早版本只提供了Reader,随着今年年初Delta Connector 0.3.0版本的发布,Standalone也正式开始支持写操作。此外,社区对Flink Sink/Source、Hive以及Presto的支持也正在开发中。

此外,Delta Lake1.0还提供了Delta-rs Rust库。目标也是希望通过Delta-rs库实现对更多高层编程语言的支持,使Delta Lake更加开放。有了Delta-rs库,更多的编程语言,比如Python、Ruby语言可以直接访问Delta Lake table。

依赖Delta-rs Rust库,Delta Lake1.0版本提供了两种Python库的安装选项,可以直接使用pip install的方式安装;此外,如果不想依赖于Spark,也可以简单地使用pip install Deltalake命令行完成对Delta Lake的安装。安装完之后,即可直接使用 Python读取Delta表的数据。

最早的Delta Lake是Spark的一个子项目,因此Delta Lake对Spark引擎的兼容性做得非常好。同时,由于Spark社区发展迅速,能够第一时间兼容Spark也是Delta Lake社区的首要目标。所以在1.0版本,Delta Lake首先兼容了Spark 3.1,并对其提供的一些特性进行优化,以便第一时间在Delta Lake里投入使用。

很多企业在使用 Delta Lake的时候,一个常用场景是使用单一集群去访问/关联一个存储系统。有Delta Lake1.0对此提供了delegating log store功能,通过log store的方式来支持不同云厂商的对象存储系统,以便能够支持混合云部署的场景,同时也可以避免对单一云服务商产生locking绑定的情况。
四、未来展望
未来,Delta Lake社区会朝着一个更加开放的方向发展。

除了借助于前文提到的核心功能,Delta Lake还能够连接Spark之外的引擎类产品。上图展示了相关功能的上线计划。

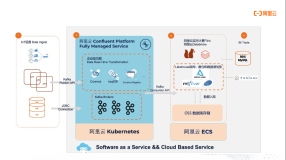
社区版的Delta Lake里,目前有两个特性的呼声比较高,分别是Optimize和Z-Ordering。这两个特性在Databricks目前开源的Delta Lake版本里面并没有提供,但是在商业版本里已经做了很好的支持。目前阿里云已经推出了基于Databricks商业版本引擎的全托管Spark产品 – Databricks数据洞察,除了此处列出的Optimize及Z-Ordering,可以在上面体验到更多商业版Spark及Delta引擎特性。除此之外,阿里云E-MapReduce产品上也对Optimize和Z-Ordering提供了阿里云自研的实现。

Databricks数据洞察产品是基Databricks的引擎提供的全托管数据平台,它最核心的部分是Databricks引擎,Databricks RunTime提供了商业版的Delta Engine以及 Spark引擎。相比于开源的Spark和Delta,商业版在性能上有非常大的提升。

最后,看一下Delta Lake当前在全球范围内的应用情况,越来越多的企业已经开始使用Delta Lake来构建Lakehouse。从Databricks给的数据看,目前已有超过3000+客户在生产环境中部署了Delta Lake,每天处理Exabytes级别数据量,其中超过75%的数据已采用Delta格式。