开源大数据平台 E-MapReduce
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
基于阿里云向量检索 Milvus 版和 LangChain 快速构建 LLM 问答系统
本文介绍如何通过整合阿里云Milvus、阿里云DashScope Embedding模型与阿里云PAI(EAS)模型服务,构建一个由LLM(大型语言模型)驱动的问题解答应用,并着重演示了如何搭建基于这些技术的RAG对话系统。
基于阿里云向量检索 Milvus 版与 PAI 搭建高效的检索增强生成(RAG)系统
阿里云向量检索 Milvus 版现已无缝集成于阿里云 PAI 平台,一站式赋能用户构建高性能的检索增强生成(RAG)系统。您可以利用 Milvus 作为向量数据的实时存储与检索核心,高效结合 PAI 和 LangChain 技术栈,实现从理论到实践的快速转化,搭建起功能强大的 RAG 解决方案。

通过阿里云向量检索 Milvus 版和通义千问快速构建基于专属知识库的问答系统
本文展示了如何使用阿里云向量检索 Milvus 版和灵积(Dashscope)提供的通用千问大模型能力,快速构建一个基于专属知识库的问答系统。在示例中,我们通过接入灵积的通义千问 API 及文本嵌入(Embedding)API 来实现 LLM 大模型的相关功能。
EMR Notebook 开启公测,提供交互式数据分析平台
EMR Notebook 是一个 Serverless 化的交互式数据分析和探索平台,满足大数据和 AI 融合下的数据处理需求,现已开启免费公测,欢迎体验!
Apache Hadoop入门指南:搭建分布式大数据处理平台
【4月更文挑战第6天】本文介绍了Apache Hadoop在大数据处理中的关键作用,并引导初学者了解Hadoop的基本概念、核心组件(HDFS、YARN、MapReduce)及如何搭建分布式环境。通过配置Hadoop、格式化HDFS、启动服务和验证环境,学习者可掌握基本操作。此外,文章还提及了开发MapReduce程序、学习Hadoop生态系统和性能调优的重要性,旨在为读者提供Hadoop入门指导,助其踏入大数据处理的旅程。
阿里云向量检索 Milvus 版开启公测,助力企业打造高质量 AI 服务
阿里云向量检索 Milvus 版正式开启公测,诚邀广大开发者及企业用户参与公测,赋能智能检索,解锁 AI 潜能。
Paimon 与 Spark 的集成(二):查询优化
通过一系列优化,我们将 Paimon x Spark 在 TpcDS 上的性能提高了37+%,已基本和 Parquet x Spark 持平,本文对其中的关键优化点进行了详细介绍。

阿里云 EMR Serverless Spark 版免费邀测中
阿里云 EMR Serverless Spark 版,以 Spark Native Engine 为基础,旨在提供一个全托管、一站式的数据开发平台。诚邀您参与 EMR Serverless Spark 版免费测试,体验 100% 兼容 Spark 的 Serverless 服务:https://survey.aliyun.com/apps/zhiliao/iscizrF54
1688API接口推荐:1688口令转换真实链接接口
1688平台的item_password接口用于将淘口令短链接转为商品链接。开发者需注册获取API key和secret,通过POST或GET请求接口,输入淘口令代码和参数,返回结果包含商品ID和详细链接。商品详情可进一步通过商品详情接口获取。注意遵守1688平台的规定和条款,确保合法使用API。

轻喜到家基于 EMR-StarRocks 构建实时湖仓分析平台实践
本文从轻喜到家的历史技术架构与痛点问题、架构升级需求与 OLAP 选型过程、最新技术架构及落地场景应用等方面,详细介绍了轻喜到家基于 EMR-StarRocks 构建实时湖仓分析平台实践经验。
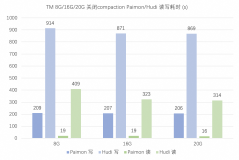
阿里云 EMR 基于 Paimon 和 Hudi 构建 Streaming Lakehouse
Apache Paimon 和 Apache Hudi 作为数据湖存储格式,有着高吞吐的写入和低延迟的查询性能,是构建数据湖的常用组件。本文在阿里云EMR上,针对数据实时入湖场景,对 Paimon 和 Hudi 的性能进行比对,并分别以 Paimon 和 Hudi 作为统一存储搭建准实时数仓。
实战营|阿里云 x StarRocks 邀你现场体验云上极速湖仓--深圳站
1月20日深圳阿里中心,阿里云 x StarRocks 邀你现场体验云上极速湖仓实战营,从 0-1 轻松上手 StarRocks 湖仓分析。
【技术分析】低代码平台的专有存储技术
低代码是一个新兴的技术,有着非常明确而鲜明的技术特点,比如:拖拽组件、可视化编程、零代码编程等等。但传统软件企业在进行技术融合时却往往是困难重重,旧有的技术积累很难能继承应用过来。本文作为一组技术分析,来逐一分解低代码背后的支撑技术。今天我们给大家带来的一个专题分析是,低代码平台的专有存储技术。

用友畅捷通基于阿里云 EMR StarRocks 搭建实时湖仓实战分享
本文从用友畅捷通公司介绍及业务背景;数据仓库技术选型、实际案例及未来规划等方面,分享了用友畅捷通基于阿里云 EMR StarRocks 搭建实时湖仓的实战经验。
Json实现根据关键词搜索请求1688商品列表数据方法,1688商品列表数据接口,1688API接口申请指南
Json实现根据关键词搜索请求1688商品列表数据方法,1688商品列表数据接口,1688API接口申请指南
Json实现根据关键词搜索请求唯品会商品列表数据方法,唯品会商品列表数据接口,唯品会API接口申请指南,支持全站
Json实现根据关键词搜索请求唯品会商品列表数据方法,唯品会商品列表数据接口,唯品会API接口申请指南,支持全站
王日宇:基于 StarRocks 和 Paimon 打造湖仓分析新范式
本文根据 StarRocks Summit 2023 演讲实录整理而成,主要分享了基于 StarRocks 和 Paimon 打造湖仓分析方案及背后的技术原来和未来规划。
2023云栖陈守元,阿里云开源大数据产品年度发布
阿里云计算平台事业部开源大数据产品总监陈守元围绕EMR、Flink Streaming Lakehouse、 Elasticsearch、Milvus等产品发布展开分享介绍。
【云栖2023】李钰:阿里云 E-MapReduce 全面开启 Serverless 时代
本文根据 2023 云栖大会,阿里云资深技术专家、阿里云开源大数据平台EMR负责人李钰演讲实录整理而成。

耳朵经济快速增长背后,喜马拉雅数据价值如何释放 | 创新场景
喜马拉雅和阿里云的合作,正走在整个互联网行业的最前沿,在新的数据底座之上,喜马拉雅的AI、大数据应用也将大放光彩。本文摘自《云栖战略参考》

Json实现根据关键词搜索请求淘宝商品列表数据方法,淘宝商品列表数据接口,淘宝API接口申请指南
Json实现根据关键词搜索请求淘宝商品列表数据方法,淘宝商品列表数据接口,淘宝API接口申请指南
杭州 Meetup| Apache Kyuubi & Celeborn,助力 Spark 拥抱云原生
10月14日13:00-17:30,Apache Kyuubi & Celeborn 社区将在杭州举办「Apache Kyuubi & Celeborn (Incubating) 助力 Spark 拥抱云原生」Meetup,欢迎报名参会!
阿里云“玩转云上 StarRocks3.0 湖仓分析”训练营火热报名中,开启数据分析新范式
阿里云 EMR OLAP 团队与 StarRocks 社区联合出品,玩转云上 StarRocks3.0 湖仓分析训练营,围绕 StarRocks3.0 系列解读、EMR Serverless StarRocks 存算分离功能与应用场景介绍,开启数据分析新范式!
阿里云E-MapReduce集群不同计算引擎sleep task使用笔记
需求:日常在E-MapReduce集群中进行相关测试,验证一些切换或变更是否会影响业务的运行导致任务failed。所以需要在测试集群中运行指定资源数(vcore及memory)或者指定运行时间的任务。 目前用到MapReduce和spark任务两种,其余的持续更新补充中……
阿里云E-MapReduce节点优雅下线-基于Yarn Node Labels特性
背景:阿里云E-MapReduce集群(简称EMR集群)部分节点需要下线迁移,但集群资源常年跑满,诉求是节点下线迁移过程中不影响任一任务执行。 本次方案基于Yarn Node Labels的特性进行资源隔离后下线。 下期对官网Graceful Decommission of YARN Nodes的方案进行验证,参考:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/GracefulDecommission.html。
Json实现根据商品ID请求天猫商品详情数据方法,天猫商品详情API接口,天猫API接口申请指南
Json实现根据商品ID请求天猫商品详情数据方法,天猫商品详情API接口,天猫API接口申请指南
Json实现根据商品ID请求淘宝商品详情数据方法,淘宝商品详情API接口,淘宝API接口申请指南
Json实现根据商品ID请求淘宝商品详情数据方法,淘宝商品详情API接口,淘宝API接口申请指南
Json实现根据商品ID请求1688商品详情数据方法,1688商品详情API接口,1688API接口申请指南
Json实现根据商品ID请求1688商品详情数据方法,1688商品详情API接口,1688API接口申请指南
Json实现根据商品ID请求京东商品详情数据方法,京东商品详情API接口,京东API接口申请指南
Json实现根据商品ID请求京东商品详情数据方法,京东商品详情API接口,京东API接口申请指南
Json实现根据商品ID请求唯品会商品详情数据方法,唯品会商品详情API接口,唯品会API接口申请指南
Json实现根据商品ID请求唯品会商品详情数据方法,唯品会商品详情API接口,唯品会API接口申请指南
Json实现根据商品ID请求阿里巴巴商品详情数据方法,阿里巴巴商品详情API接口,阿里巴巴API接口申请指南
Json实现根据商品ID请求阿里巴巴商品详情数据方法,阿里巴巴商品详情API接口,阿里巴巴API接口申请指南
Json实现根据商品ID请求亚马逊商品详情数据方法,亚马逊商品详情API接口,亚马逊API接口申请指南
Json实现根据商品ID请求亚马逊商品详情数据方法,亚马逊商品详情API接口,亚马逊API接口申请指南
Json实现根据商品ID请求易贝商品详情数据方法,ebay商品详情API接口,易贝API接口申请指南
Json实现根据商品ID请求易贝商品详情数据方法,ebay商品详情API接口,易贝API接口申请指南
Json实现根据商品ID请求微店商品详情数据方法,微店商品详情API接口,微店API接口申请指南
Json实现根据商品ID请求微店商品详情数据方法,微店商品详情API接口,微店API接口申请指南
Json实现根据商品ID请求速卖通商品详情数据方法,速卖通商品详情API接口,速卖通API接口申请指南
Json实现根据商品ID请求速卖通商品详情数据方法,速卖通商品详情API接口,速卖通API接口申请指南
Json实现根据商品ID请求lazada商品详情数据方法,lazada商品详情API接口,lazadaAPI接口申请指南
Json实现根据商品ID请求lazada商品详情数据方法,lazada商品详情API接口,lazadaAPI接口申请指南
Json实现根据商品ID请求拼多多商品详情数据方法,拼多多商品详情API接口,拼多多API接口申请指南
Json实现根据商品ID请求拼多多商品详情数据方法,拼多多商品详情API接口,拼多多API接口申请指南

Apache Kyuubi & Celeborn (Incubating) 助力 Spark 拥抱云原生
网易数帆软件工程师潘成,在 ASF CommunityOverCode Asia 2023(北京)的分享。
EMR Serverless StarRocks + DataWorks 开启极速分析新体验
EMR Serverless StarRocks + DataWorks ,开启极速分析体验
CommunityOverCode Asia 精彩回顾|阿里云开源大数据 EMR 技术实践分享
阿里云开源大数据 EMR 在 CommunityOverCode Asia 的精彩分享。
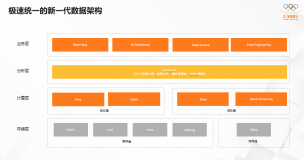
全链路数据湖开发治理解决方案2.0重磅升级,全面增强数据入湖、调度和治理能力
阿里云全链路数据湖开发治理解决方案能力持续升级,发布2.0版本。解决方案包含开源大数据平台E-MapReduce(EMR) , 一站式大数据数据开发治理平台DataWorks ,数据湖构建DLF,对象存储OSS等核心产品。支持EMR新版数据湖DataLake集群(on ECS)、自定义集群(on ECS)、Spark集群(on ACK)三种形态,对接阿里云一站式大数据开发治理平台DataWorks,沉淀阿里巴巴十多年大数据建设方法论,为客户完成从入湖、建模、开发、调度、治理、安全等全链路数据湖开发治理能力,帮助客户提升数据的应用效率。
直播|深入解析 StarRocks 存算分离--云原生湖仓 Meetup#2
8月17日19点,云原生湖仓线上Meetup,深入解析 StarRocks 存算分离,多位大咖分享,干货满满,快来报名!~




