前言
大家好,今天开始和大家分享,我在自然语言处理(Natural Language Processing,NLP)的一些学习经验和心得体会。
随着人工智能的快速发展,自然语言处理和机器学习技术的应用愈加广泛。为使大家对该领域整体概况有一个系统、明晰的认识,同时入门一些工程实践,也借CSDN为NLP的学习,开发者们搭建一个交流的平台。我希望能够通过这个专栏《自然语言处理实战入门》和广大NLP爱好者一起学习自然语言处理技术,分享学习资料,打破NLP 技术 的实战应用壁垒。
由于网络上的教程等,基本都已英文NLP 作为切入点,但本人认为汉语NLP还是有着很多根本性不同的,所以本专栏的所有代码与DEMO也都是围绕着汉语自然语言处理进行构建。
本专栏持续更新中,内容还未完整的请稍安勿躁,部分内容有参考其他书籍或是网络文献,都会给出原始出处
配套前期视频课程 ---- 持续更新中
综论
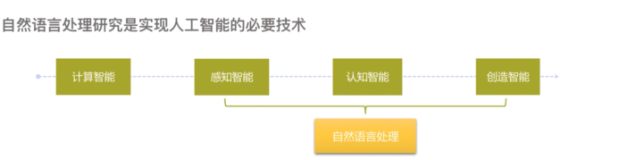
what is it?
自然语言处理(Natural Language Processing,简称 NLP)是人工智能和语言学交叉领域下的分支学科。
用于分析、理解和生成自然语言,以方便人和计算机设备进行交流,以及人与人之间的交流
自然语言处理在深度学习的支撑下取得了迅猛发展,总结的过去5年ACL文章中自然语言发展的主要工作,包括 Word embeddings、LSTM、Encode decoder、RNN、Pre-trainedmodel 等,这些技术推动了自然语言的应用,包括基于神经网络的机器翻译,预训练模型演化,阅读理解技术等。
现在自然语言处理相关专业人才属于供不应求的状态,这种状态是因为过去很长一段时间,高校NLP人才的培养是跟不上业界需求的。毕竟目前国内高校比较有积淀的自然语言处理实验室不是很多,可能也就二三十家,而对于高校来说,建立一个学科是需要时间积累的。这就导致了培育人才的速度跟不上工业界的需求。目前,工业界对于能够理论与实践相结合、学习能力强、能够推动产品落地的人才是十分渴求的。通过对企业用人端的分析,以及NLP知识框架分析,我们可以从核心能力、工作能力两个方面回答:
NLP 前置技术
莫要轻视前置基础,所有技术都不是一蹴而就的 。希望大家能够沉下心来,慢慢打磨自己的技术,首先将前置技术融汇贯通。本篇章从搭建 开发环境开始讲起,以网络爬虫作为工程化学习NLP的引入。其次通过学习通用的开源框架,夯实NLP基础知识,最后带领大家查看NLP 工程中常用的资源、语料库。
开发环境
基础技术
网络爬虫
开源库
- NLP开源工具包与云服务提供商
- 基础库 ---- NumPy
- 基础库 ---- Pandas
- 基础库 ---- Pandas(练习篇)
- 基础库 ---- SciPy
- 基础库 ---- matplotlib
- 机器学习 ---- Gensim
- 机器学习 ---- Scikit-learn
- 深度学习 ---- TensorFlow
- 深度学习 ---- Keras
- 深度学习 ---- Pytorch
深度学习基础
常用资源
序列标注与分词算法
“数学上,序列是被排成一列的对象(或事件);这样每个元素不是在其他元素之前,就是在其他元素之后。在自然语言处理领域,语句便是序列,对其进行标注是最常见的任务之一,只要涉及对一个序列中的各个元素进行打标签的问题,都可以通过序列标注模型解决。
简介
- 中文分词原理及相关组件简介 之 ---- 汉语语言学
- 中文分词原理及相关组件简介 之 ---- 分词领域主要分词算法、组件、服务(上)
- 中文分词原理及相关组件简介 之 ---- 分词领域主要分词算法、组件、服务(中)
- 中文分词原理及相关组件简介 之 ---- 分词领域主要分词算法、组件、服务(下)
分词算法原理
- 中文分词原理及相关组件简介 之 ---- 分词算法原理
- 中文分词原理及相关组件简介 ---- 分词算法原理(CRF)
- 中文分词原理及相关组件简介 ---- 结构化感知机
- 中文分词原理及相关组件简介 ---- 分词算法原理(HMM)
实践
评测
词嵌入(分布式文本表示)
word2vector顾名思义,其实就是旨在把每个单词转化为词向量,其实很多方式都可以实现这个功能,最简单的当然就是one-hot了,但是面对无敌庞大的词库,直接使用one-hot来进行表示将会面临很大的内存占用和很高的计算时间,于是有了LDA、GloVe以及现在比较新的bert等,都是尝试通过使用连续的词向量模型来进行词向量转化,从而进行后续的自然语言处理任务。
文本分类
文本分类用电脑对文本集(或其他实体或物件)按照一定的分类体系或标准进行自动分类标记。 它根据一个已经被标注的训练文档集合, 找到文档特征和文档类别之间的关系模型, 然后利用这种学习得到的关系模型对 新的文档进行类别判断 。文本分类从基于知识的方法逐渐转变为基于统计 和机器学习的方法。
文本分类一般包括了文本的表达、 分类器的选择与训练、 分类结果的评价与反馈等过程,其中文本的表达又可细分为文本预处理、索引和统计、特征抽取等步骤。
- 文本分类简介
- 使用词向量与SVM 进行文本分类
- CNN与中文文本分类
- 使用词向量与TestCNN 进行文本分类
- 预训练模型 文本分类
- 基于 Django 3.2 框架开发 机器学习在线 系统
- 模型在线部署 -- 使用Django在线预测
NLP 可视化
人眼是一个高带宽的巨量视觉信号输入并行处理器,最高带宽为每秒100MB,具有很强的模式识别能力,对可视符号的感知速度比对数字或文本快多个数量级,且大量的视觉信息的处理发生在潜意识阶段.
其中的一个例子是视觉突变:在一大堆灰色物体中能瞬时注意到红色的物体。由于在整个视野中的视觉处理是并行的,无论物体所占区间大小,这种突变都会发生.视觉是获取信息的最重要通道,超过50%的人脑功能用于视觉的感知,包括解码可视信息、高层次可视信息处理和思考可视符号。

文本检索
信息检索定义为对用户做出的查询进行响应并检索出最合适的信息的过程。在信息检索中,根据元数据或基于上下文的索引,进行搜索。搜索引擎 是信息检索的一个示例,对于每个用户的查询,它基于所使用的信息检索算法进行响应。信息检索算法中使用了倒排索引的索引机制。
信息抽取
信息抽取 (Information Extraction) 是把文本中包含的信息进行结构化处理,变成表格一样的组织形式。信息抽取的主要任务是将各种各样的信息点从文档中抽取出来。然后以统一的形式集成在一起,方便后序的检索和比较。
使用深度学习进行自然语言处理
深度学习是利用多层次神经网络结合机器学习 形成的,使计算机通过自动完成学习过程的一类算 法。其与以设计为主的传统机器学习相比,不仅实 现了机器学习的自动化,减少了面对不同问题时的 人工设计成本,还增强了对数据中潜在信息的提取 与分析能力。
在深度学习技术成熟之前,机器学习主要使用 的算法建模是带有一层或是没有隐形节点的,如条件随机场(Conditional Random Field,CRF)、支持向 量机(Support Vector Machine, SVM)及最大嫡模型 (Maximum Entropy,ME)等。这些带有一层或是没 有隐形节点的建模在面对结构复杂的数据泛化问题
精确度的需要⑵。2006年,深度学习 被用于手写文字识别的领域,并取得了很好的效果。 此后,深度学习的方法也被用于解决自然语言处理 (NLP)领域中的问题2011年到2012年,深度 神经网络(Deep Neural Network,DNN)被应用在图 像识别领域和语音识别领域,并取得了显著的成绩。 但是,由于自然语言处理领域待解决的问题的复杂 性、多样性以及对训练数据海量的要求,导致深度学 习在该领域还没有重大的突破。
- 综论
- Transformer 与Attention 架构初探
- 预训练模型初探
- 使用深度学习进行汉语分词
- 预训练模型的使用(BERT)
- 预训练模型的使用(ALBERT)
- 深度学习与中文短文本分析总结与梳理(早期文章)
知识图谱
2012 年,谷 歌 提 出 了 知 识 图 谱 (knowledge Graph)的概念,为世界知识和领 域知识的构建提供了一个可资借鉴的手段。
知识图谱的基本组成是由头实体、尾实体和两者之间的关 系组成的三元组关系。目前,对知识图谱 的研究应用主要 包括通用知识图谱和垂直领域知识图谱。
典型的通用知识图谱有 google knowledgegraph、 DBpedia、CN-DBpedia、XLore等。虽然通用知识图谱收集了大量的领域知识,但是受到概念约束,无法完整描述比较复杂 的领域知识。垂直领域知识图谱在领域知识的描述方面优于通用知识图谱,但常采用手工构建方法,因此其构建成本很高。
文本生成
文本生成目前主要试用的是GPT-2 模型
基本上只要了解 Transformer 架构,你馬上就懂 GPT-2 了。
聊天机器人
自动问答是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务。问答系统是信息服务的一种高级形式,系统反馈给用户的不再是基于关键词匹配排序的文档列表,而是精准的自然语言答案,这和搜索引擎提供给用户模糊的反馈是不同的。在自然语言理解领域,自动问答和机器翻译、复述和文本摘要一起被认为是验证机器是否具备自然理解能力的四个任务。
自动问答系统在回答用户问题时,首先要正确理解用户所提出的问题,抽取其中关键的信息,在已有的语料库或者知识库中进行检索、匹配,将获取的答案反馈给用户。这一过程涉及了包括词法句法语义分析的基础技术,以及信息检索、知识工程、文本生成等多项技术。
传统的自动问答基本集中在某些限定专业领域,但是伴随着互联网的发展和大规模知识库语料库的建立,面向开放领域和开放性类型问题的自动问答越来越受到关注。根据目标数据源的不同,问答技术大致可以分为检索式问答、社区问答以及知识库问答
三种。检索式问答和搜索引擎的发展紧密联系,通过检索和匹配回答问题,推理能力较弱。社区问答是 web2.0 的产物,用户生成内容是其基础,Yahoo!、Answer、百度知道等是典型代表,这些社区问答数据覆盖了大量的用户知识和用户需求。检索式问答和社区问答的核心是浅层语义分析和关键词匹配,而知识库问答则正在逐步实现知识的深层逻辑推理。
纵观自动问答发展历程,基于深度学习的端到端的自动问答将是未来的重点关注,同时,多领域、多语言的自动问答,面向问答的深度推理,篇章阅读理解以及对话也会在未来得到更广阔的发展
语音识别
语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术。
- 语音识别本质上是一种模式识别的过程,未知语音的模式与已知语音的参考模式逐一进行比较,最佳匹配的参考模式被作为识别结果。
- 语音识别的目的就是让机器赋予人的听觉特性,听懂人说什么,并作出相应的动作。目前大多数语音识别技术是基于统计模式的,从语音产生机理来看,语音识别可以分为语音层和语言层两部分。
- 当今语音识别技术的主流算法
主要有基于动态时间规整(DTW)算法、基于非参数模型的矢量量化(VQ)方法、基于参数模型的隐马尔可夫模型(HMM)的方法、基于人工神经网络(ANN)和支持向量机等语音识别方法。
笔试、面试
参考文献
- 《Python自然语言处理实战-核心技术与算法》
- 《汉语自然语言处理原理与实践》
- 《自然语言处理理论与实践》
- 做项目一定能用到的NLP资源