原理:数据分布策略
(一)为什么会有数据分布问题?
首先我们先看一个问题,就是为什么会有数据分布的问题。
在过去,大家都是用单机的数据库系统或者是用大型机,随着行业的发展,数据越来越多,单机或者是大型机已经存不下了,所以我们需要一个多机或者多盘的方式来管理更多的数据。

如上所示,这里面有两种扩展方式,一种是Scale Up,也是大家都比较熟知的方式。
Scale Up就是提高硬件的配置,比如我们由1T的盘变成4T、8T的盘,未来可能是更大的盘。但这种方式很容易遇到硬件的瓶颈,因为单盘不可能做得很大,除非技术上有里程碑式的突破。
目前业界比较常用的是另一种方式 Scale Out,这种方式就是一块盘不够就用多块盘,一台机器可能连个十几块盘甚至几十块盘就差不多了,还不够的话就用更多的机器,如果更多的机器连成一个集群还不够,那就建更多的机房,这样就可以 很容易地扩展到一个非常大的规模。
这就是我们实现线性扩展的方式,也就是系统可以通过加盘、加机器来扩充存储容量,同时也可以通过这种方式来扩展计算能力,加多少得多少。
另外,我们还需要这个系统具有负载均衡的能力,当进行扩容或者缩容,整个系统的数据以及它的请求在系统之间是均匀负载的情况。
最后,我们可以通过分布来解决可靠性的问题,也就是常见的多副本问题,但是多副本不在本文的主题范围内,本文主要聚焦在前面两个目标。
(二)HBase的数据分布策略:顺序分布
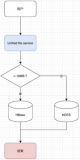
下面我们看一下HBase到底是怎么组织数据的,目前业界有两种比较常用的方案,一种是顺序分布,也是HBase采用的方式,还有一种一致性Hash的分布,比如像Cassandra这类产品。

我们先看一下HBase的顺序分布,举个例子如上所示。
我们有一个表,它有两个主键,一个是user_id,然后它有一个时间戳以及在时间戳上面这个user在哪个位置。对于任何一个用户来讲,他的user_id加上时间戳构成了他唯一的主键,也就是我们的Rowkey。
先抛开数据分布本身来说,数据自己的存储是按照user_id的顺序往下排的,对user_id相同的时候,是按照TS顺序来排的,对于Region分布来说,我们可能把表按照整个Rowkey的分布拆成三个Region。比如100~300拆一下,然后300~500拆一下,这样的话我们产生了三个Region。
在HBase层面,它在管理的时候,Region的边界可能是一个虚拟的 Rowkey,比如上图右边的小表,第一个Region开始时候是负无穷,任何一个小于2的Rowkey,都分在第一个Region里面。
2这个Rowkey在整个表里是不存在的,它是一个虚拟的边界,只是用来做参与比较的,也就是说所有比2大的user_id,包括2本身,它都会分到第二个Region里面。对于3这样的数据,我们出现了一个情况,就是user_id=3的数据被分到两个Region里面,也就是说我们这里面的一个Region边界,把Region的前置打散了。
然后到第三个Region的时候,先是3~600,然后到+∞,这样的话我们就通过Region的边界,把整个Rowkey的值域全部覆盖,从负无穷到正无穷。那么中间这部分,比如说200、300、600这些点,它其实是可以人工指定的。
我们把这个表称为路由表,在HBase里面叫Meta表。所有基于对HBase的请求都会先查这个表,来找到要请求的数据在哪个位置,然后根据Region找到所在的机器,然后请求到这个机器里面去,路由表在客户端也缓存来提高定位的速度。
对于一个Region能分到哪个机器,这件事情在建表的时候是随机分布的,因为这样的话可以保证这一个表里的Region能够在整个集群范围内,获得比较好的随机分布。同时因为它有路由表的存在,所以我们可以通过人工介入的方式来改变一 个Region所在的机器,这样的好处是Region分布可以非常灵活。
比如,当某个Region出现热点的时候,我们可以手工把它挪到另外一个空闲的机器里面,甚至可以单独扩一台机器,把这个Region挪过去,这样的话就可以很从容地处理线上的一些突发状况,也就是Region其实可以通过人工干预来做分配。
同时,Region边界可以修改,比如把Region 1按照100~200再拆成两个,同时可以对它们进行合并,比如Region太多的时候可以合并。
但注意一点, HBase没有Partition Key的概念,对于一致性Hash的分布,我们往往会认为user_id这一列可能是一个分区列,或者它比较适合作为一个分区列/键。但是对于HBase而言,我们其实不看分区键,因为HBasee的Region分布以及它的请求路由全部都是基于整个或者说基于完整的Rowkey进行。
比如我们会聚集300~400这样整个的Rowkey来对它进行路由和拆分,因此可以认为HBase没有 Partition Key 的概念,或者说可以认为 Partition Key 在HBase里面其实是个逻辑的概念,并不是一个物理概念。比如说我们认为user_id是Partition Key的时候,那么具有相同前缀的user_id,比如1,逻辑上它可能会分布在一起,但是在物理上可能不一定分在一起。
(三)顺序分布策略分析
看完HBase的顺序分布以后,结合前文提到的这几个指标,我们来具体分析一下HBase是怎么来做负载均衡以及线性扩展。

在理想情况下,我们希望HBase每一个Region都差不多大,也就是它们的数据量大体相同。
同时,我们希望一个表里所有的Region能在整个机器里面均匀分布,也就是每台机器服务的Region数量大致相同,这样的话可以让每台机器的整个负载或者吞吐大致相同的。
除此之外,我们希望Region在发生分裂或者合并以后,以及机器发生扩容或者缩容以后,整个集群仍然处于负载均衡的状态,这是一个最理想的状态。
但事实上,大部分时候系统会处于一种近似负载均衡的状态,如果业务有一些突发情况,比如大促,很可能就会打破这种状态,这个时候往往就需要人工介入了。
当然,为了保证系统在大部分时候都处于负载均衡的状态,我们需要对整个系统做一个很好的设计,设计目标就是希望数据和请求能够在Region之间进行随机均匀分布。
(四)顺序分布的常见问题
HBase顺序分布的策略有一些缺陷,这里面列举了几点。

以上方表格为例,user_id这个场景特别容易出现数据倾斜。因为user_id往往都是从1开始分配,它不是一个随机数,而是12345678这样由小到大的递增分布。
对于HBase这种顺序分布的表来说,当我们产生一些新的User的时候,往往都会产生在表尾这个位置,也就是说大的user_id都是产生在表尾。对于一个会运行很久的系统来说,小的user_id往往都比较冷了,而大的user_id一般都比较热,这样也会产生一个访问的情景,就是表尾会比表头更热。对于数据来说,也是表尾的数据会比表头的更多,这是因为 user_id本身的分布顺序导致的数据倾斜以及访问倾斜。
如果有一些user_id特别大,比如它占了整个表数据分布的50%以上,它就属于一个超大的用户。这种超大用户对于整个数据分布也会产生一个倾斜,对于这样的数据分布,往往我们需要特别处理。比如说我们把它识别出来,单独放到一张表里,或者是对它进行二次拆分策略,来解决它局部热点的问题。
下面我们结合物流详情的业务场景,来看一下HBase的数据分布策略到底是怎么做的。
物流详情管理系统设计
(一)需求分析
在电商物流订单场景,每个订单会经历多轮中转最后达到用户手中。每一次中转会产生一个事件,比如已揽收、装车、到达XX中转站、派送中、已签收。构建一个系统,记录全网所有物流订单的状态变化,为用户提供订变更记录的查询服务。

功能需求(业务场景抽象):
1)存储所有物流订单的状态变化信息
2)查询指定物流订单
所有状态变化数据,按时间倒序排列 最近一条状态数据
非功能需求: 1)海量订单数据(上百亿),系统容量/吞吐可线性扩展 2)高并发,高性能
这样的系统我们该怎么设计呢?
(二)第一版表设计

首先从直觉来看,第一版的表设计如上所示。我们拿OrderID的时间戳作为主键,然后根据时间戳上OrderID的状态变化,也就是根据查询来反推表的数据,得到一个直接的设计。
这个设计有个特点是一个订单的每一次状态变化,在表里是作为一行来存储的,这个我们称为高表的设计。
还有另外一种设计是一个订单所有的变化存在一行里面,也就说这个Detail本身不是叫Detail,而叫TS,可能每一列有不同的列名,就是用TS做它的列名,然后Value是它的状态变化。
对于Detail只有一列或者只有这一个信息要存的话,这种宽表的设计是没问题的。但事实上,作为一个生产系统而言,我们往往需要能够扩展其他的列,比如这一次操作的人员是谁,是否有一些其他的信息需要记录,我们都需要扩展到后面的列当中。
因此我们这里采用了高表的设计,这也是实际生产中使用的设计。
(三)第一版表设计:数据分布解析
这个设计有什么问题,我们先来看写。

假设我们现在新增两行数据,一个是订单111某一次的事件记录,另一个是新订单333的一个记录,如上图所示。
从这个图上我们其实看不出来什么问题,但是当我们仔细分析这个系统的时候,会发现订单的ID其实不具有全局随机性的,也就是它跟我们之前 User ID有差不多的问题。User ID是一个比较明显的顺序分布的状态,但Order ID由于我们有 很多的物流公司,每家物流公司的订单规则都不太一样,但是我们大致可以看到物流的订单有比较明显的前缀的关系,比 如申通是有固定前缀。
这样的话我们就可以得到一个结论,就是物流订单其实不具有全局随机性,也就是说如果我们直接物流订单存在这儿的话,很可能会导致这个数据倾斜或者局部的热点,尤其是当整个体量非常大的时候,这种微小的数据分布不均匀将会放大,阻碍系统的扩展。为了解决物流订单本身分布不均匀的问题,我们需要对它做一个处理,让这种不均匀的数据能够变得均匀。
一个比较直接的方案就是做一个Hash。
比如说我们对物流订单本身算一个MD5或者算一个Hash,然后取这个结果的前4位或者前8位来拼到前面,将“Rowkey = hash + orderId + ts”作为新的Rowkey。
(四)第二版表设计:orderId加Hash
这样的话,对于任何一个订单来讲,因为前面拼了Hash,此时整个数据的分布就取决于Hash值在整个Region里面的位置,而不是取决于Order ID,因为Hash本身具有随机性,一个订单的数据也具有随机性。

这里需要注意是我们算Hash的时候,只给Order ID算,TS是不参与Hash计算的。
为什么要这样做?
因为我们期望同一个订单的所有变化数据要排在一起,这样我们查的时候能够一次性查出来。如果TS也参与了计算,这意味着同一个订单里不同时间戳的数据算出来Hash可能是不一样的,可能会散布到整个表不同的地方。这样的话就没有办法拿到这个订单的所有数据,因为无法预测一个订单可能会有多少个变化的事件,而且也不知道这个事件到底是什么,所以就没法查了。
因此只能给Order ID算Hash,我们通过加Hash的方式就能很好地解决订单本身的分布问题。
(五)第二版表设计:查询
下面来看一下查询,前面我们提到系统要支持两种查询,一种是支持查所有变化,一种是查最近一次变化。
查所有的我们怎么查?
从SQL的角度来讲,我们要做一次前缀扫描,就是我们有Order ID之后,算出来Hash值,基于Hash和Order ID做一个前缀查询。

对于前缀查询,我们写Scan要特别注意的是STOPTARTROW 是通过加1的方式实现的,也就是说这里面其实是112,这样的话能把111的全部数据查出来。
如果需要在查完之后做一个按时间戳倒排,按照现在的设计,需要在客户端做倒排。
另外,对于查询一个订单的最近一条记录,它也是需要做倒排的,写的SQL是:
select * from events where hash = '00aa' and orderId='111' order by ts desc limit 1;
对于当前的表设计,我们需要把Order的所有数据都查出来,然后取最后一条。这就有一个问题,如果我们只想要最后一条记录,但是这个查询会把Order所有数据都查出来,这样其实是比较低效的。
如果我们是用MySQL来做这个表设计,在建表的时候很自然地就会把TS设为DESC排序的过程。但是对于HBase,它天然不支持DESC排序,我们怎么来做这件事情?
(六)终版表设计:TS DESC
我们可以在业务侧实现倒序的排序,这种方法就是通过Long.MAX_VALUE – ts作为TS来存储。

这在数学据上是可以证明的,通过计算机的补码设计,就可以证明通过LONG来减的方式没有问题。
这样的话,当我们想要查一个订单最近一条记录的时候,直接读一行数据就可以了。而且当我们去扫一个Order所有的数据时,读到的数据也天然是按时间戳倒排,业务侧不用再做一次排序,因此这个表设计可以很好地解决写的分布以及查询 这两个问题。
(七)设计考量
·分布:Rowkey的随机分布非常重要,如果原始的业务字段随机性较差,可以添加Hash前缀。
1)Hash通常取md5/murmurhash的前4-8个字节;
2)加Hash的副作用:不支持跨orderId的范围查询(业务上不需要);
3)Hash的替代方案:Reverse,如1112345经Reverse是5432111:不增加rowkey长度,适用于有公共前缀但末尾有良好离散度的数据,如时间戳字段。
·值类型的DESC组织:MAX–原始值,适用于整形类型,如Short,Int,Long。
浮点数的DESC实现:按Bit进行Reverse。
·查询效率分析:
1)服务端扫描的数据量 == 结果集的数据量,查询没有浪费,最优;
2)如果读的多,返回的少,则查询有浪费。
·成本:
1)数据压缩:文本类数据通常有较好的压缩比,一般可提供;
2)TTL:物流订单不需要永久保留,结合业务设置合理的TTL;
3)冷热分离:云HBase提供业务透明的冷热分离能力,自动将冷数据迁移到低成本介质中。
物流详情管理系统编码实战
(一)准备工作
前面主要阐述的是设计,下面来看一下实践方面的问题。

首先我们先要做一些准备的工作,比如买集群,配置账号,开通一些白名单,开通官网服务等操作,这些按照上方去做即可。 在这里给大家提供了一个已经写好的代码工程,配上自己买的HBase集群,然后通过Idea打开就可以直接运行。 如果有用户想要自己从头开始写的话,也可以用这里的 Spring模板生成器生成,然后直接导入就可以了。
(二)系统设计
下面简单介绍一下这个系统的设计和代码实现。


设计上大概分为上图几个层次,一个是前端,也就是我们通过浏览器操作的部分,我们有一个简单的界面。然后下面是 EventController,负责与前端做一个交互,比如插入一个订单状态,查询订单,这些操作都会直接落到EventController,然后EventController会调用EventService层的业务逻辑来处理具体的订单查询和写入。
再下面会有一个基于HBaseTemplate参数的封装,最下面就是HBase数据库,我们可以通过Event的方式来管理任何一个订单的状态描述。
(三)Service层
Service层有三个接口,每个接口正好对应了前面说的三个操作,分别是记录一个订单状态变更的写入操作,和一个是读所有时间的读操作,和另一个读最近一个时间的读操作。这些操作都是把用户的请求转成对HBase调用,就是写的时候把 Event转成HBase的Put,然后把查询变成Scan。

这里面有很多具体的实现细节,比如Rowkey是怎么拼的,STARTROW、STOPROW是怎么设计的,这些大家可以仔细阅读上方代码。
本次案例的业务逻辑比较简单,在实际的生产中,Service层可以实现非常复杂的逻辑。
(四)总结

整个设计可以分为三步,第一步是看需要存什么样的数据,以及怎么对这个数据进行查询。有了两个信息之后,就可以反推整个系统的表设计,可以得到一个主键设计和索引设计。有了表设计以后,就可以对这个表设计做实现,用的方式取决于业务的情况。
这里有一个进阶的思考,就是前面例子的设计其实隐含了一个假设,就是物流订单ID在全表范围内一定要全局唯一。如果有两个订单ID碰巧相同,这个时候这两个订单会变成一个订单来处理,所以问题在于,物流订单的ID它是全局唯一的吗?不同物流公司的单号会重复吗?
我们在做系统设计的时候不知道这个事情,或者说想知道这件事情的成本可能会比较高。由于国家对物流订单ID没有一个比较明确的标准,各个公司都会制定自己的订单ID生成规则,鉴于我们对物流相关行业的知识所限,我们不知道订单ID到底是不是唯一的,此时在设计上就要遵循一个原则,就是不要依赖不确定的假设,或者说不要依赖弱假设。
也就是说,在系统设计的时候,我们可以认为物流订单ID不是全局唯一的,怎么做表设计来保证或者说让系统能够不依赖订单ID的唯一性,这个问题也需要我们思考。
交易订单管理系统
(一)需求分析
淘宝的交易订单管理系统,提供订单的存储、查询服务,数据具有体量大、增长快、查询复杂等特点。

功能需求
1)写入
- 下单
- 订单状态变更(付款、发货、交易完成、退款等等)
2)查询
-列topN
- 按状态查询top N
- ad hoc查询

这样的系统我们怎么去做设计?
(二)方案设计
其实跟前面物流详情的案例比较像的是我们也可以以订单ID为主键,然后通过Hash做散列,通过冷热分离解决弹性成本的问题。

主表:以订单ID为主键,hash散列,冷热分离
索引:
·买家订单:数据相对较小,可暴力扫描,也可构建少量的常用索引
·卖家订单:数据量一般较大,通过Lindorm Search构建索引,支持多列随机组合查询和复杂分析
但是对于按照非Order ID做的复杂查询,我们往往通过索引来解决。
对于买家而言,订单往往不会特别多,订单上千已经属于凤毛麟角,大部分情况是不到100,因此这种场景数据量少,可以通过暴力扫描解决。
但有些场景,比如卖家的订单,订单可能就非常多了。例如双11、618等场景,某些卖家一天的订单量可能就非常巨大,通过暴力扫描解决不了。这个时候我们可以通过Lindorm Search来构建一个全文索引,更好地支持多列随机组合的查询以及一些复杂分析,比如说查看某一类交易额的订单。

当然,对于服务商家,淘宝有一系列复杂的数据产品,这里只是举个例子。
(三)更多企业级功能: Serverless
对于HBase或Lindorm,还有更多企业级的能力Serverless。
简单来说Serverless就是按量付费,用多少付多少,不是买集群的模式。这适用于业务不断发展,或者刚开始规模很小的业务。

按照传统的方式,我们一般是先规划一个容量,比如说买4台机器。当我们的业务人员上涨,我们就扩容,也就是上图中的直线。每次扩容可以让容量增加很多,但问题是容量增加的时候,其实业务体量并没有跟着涨那么多,因为我们往往都是按照业务峰值来做容量评估,此时势必有很多资源的浪费。
用户为了不必要的东西花钱是我们不希望看到的,因此Lindorm有Serverless模式,用多少付多少,不用不付钱,与此同时整个系统的扩展性和稳定性跟买集群基本一样,实现了最优成本。
(四)Serverless

Serverless比较适用的场景是变化、不可预测的工作负担。
同时,Serverless还有定时任务,比如可能每周跑一个任务,然后跑任务的时候流量很大,跑完了流量就下来了,这种场景非常适合Serverless,并且它还会自动根据业务的负载来选择合适的机器。
除此之外,Serverless对于开发阶段特别友好,可以不用买独立的集群做开发测试,完全按需付费。

此外再简单提一下Lindorm,Lindorm可以理解为下一代的HBase。

Lindorm本身是一个多模数据库,它提供了HBase API的兼容以及NoSQL体系下常见的生态服务,比如Hadoop、Phoenix 等,同时也兼容Cassandra和Solr的语法。这样的话,大家可以在一个数据产品里面完成多种业务的实现,不用在多个系统之间导通数据,一个系统就可以解决。