嘉宾简介:辛现银,花名辛庸,阿里巴巴计算平台事业部 EMR 技术专家,Apache Hadoop,Apache Spark contributor,对 Hadoop、Spark、Hive、Druid 等大数据组件有深入研究。目前从事大数据云化相关工作,专注于计算引擎、存储结构、数据库事务等内容,今天为大家介绍Delta Lake 如何帮助云用户解决数据实时入库的问题。
直播回放:https://developer.aliyun.com/live/2894
以下是视频内容精华整理。
一、CDC简介
CDC是Change Data Capture的缩写,也就是改变数据捕获。比如在最开始的时候我们用工具将业务数据导入数据仓库、数据湖当中,之后导入数据的时候我们希望反映数据的动态变化,进行增量导入,并且能够尽快的捕获这些变化数据,以便更快地进行后续的分析,而CDC技术能够帮助我们捕获这些变化的数据。
大数据场景下我们常用的工具是Sqoop,它是一个批处理模式的工具,我们可以用它把业务库中的数据导入到数据仓库。需要注意的时候我们在导入之前要在业务库中的数据中选出能反映时间变化的字段,然后依据时间戳将发生变化的数据导入数据仓库中,这是使用它的一个限制。另外,这个工具还有如下几个缺点:
- 对源库产生压力;
- 延迟大,依赖于调用它的频次;
- 无法处理delete事件,源库中被delete的数据无法同步在数仓中被delete;
- 无法应对schema变动,一旦源库中的scheme发生变化,就在对数仓中的表模型重新建模和导入。
除了使用 sqoop,还有一种方式是使用binlog 的方式进行数据同步。源库在进行插入、更新、删除等操作的时候会产生binlog,我们只需要将binlog打入KafKa,从 Kafka 中读取 binlog,逐条解析后执行对应的操作即可。但是这种方式要求下游能够支持比较频繁的update/delete操作,以应对上游频繁的 update/delete 情形。这里可以选择KUDU或者HBASE 作为目标存储。但是,由于KUDU和HBASE不是数仓,无法存储全量的数据,所以需要定期把其中的数据导入到Hive中,如下图所示。需要注意的是,这种方式存在多个组件运维压力大、Merge逻辑复杂等缺点。

二、基于Spark Streaming SQL & Delta 的CDC方案
(一)Spark Streaming SQL
Spark Streaming SQL是阿里巴巴计算平台事业部EMR团队基于Spark Streaming开发的SQL支持,社区版本是没有的。Spark Streaming SQL在这套CDC方案中不是必须的,但是它对于用户更加的友好,尤其是对习惯于使用SQL的用户来说,因此 EMR 团队开发了 Spark Streaming SQL 的支持。如下图所示,EMR 的 Spark Streaming SQL在诸多方面实现了对SQL语法的支持,比如DDL、DML、SELECT等等,下面捡几个分别予以介绍。

(1)CREATE SCAN & CREATE STREAM
下面所示的是一个例子,我们的目标是从KafKa中的一张表中select一些数据,设计目标是尽可能的支持批和流两种方式。在普通的SQL中,实际上select就产生了读操作,但是这里为了区分batch和Streaming,我们需要显式的create scan,因为我们无法从data source上区分是batch读还是Streaming读,如果是batch,我们就使用 USING batch,如果是Streaming,我们就使用USING stream。
对于 batch scan,在create scan之后就可以直接从scan中select,把scan当作一张表;然而对于Streaming,如果要读这个scan,就需要设计很多参数,因为要发起一个job,于是有了如下图所示的create stream语法,其本质是对select语法的封装。

(2)MERGE INTO
另外一个比较核心的语法是MERGE INTO,其在Delta Lake的CDC方案中有着非常重要的地位。MERGE INTO的语法是比较复杂的,具体如下图所示。需要注意的是MERGE INTO中的mergeCondition必须在源表和target表中产生一一对应的关系,不然如果一条 source record 对应多条 target records,系统就不知道应该对哪条进行操作了。所以这里实际上要求 mergeCondition 是一个主键连接,或者等同于主键连接的效果。

除了上面介绍的几个语法,为了大家更加方便地使用Spark Streaming SQL,我们还实现了一些其他的UDF,比如DELAY、TUMBLING等。
(二)Delta Lake
数据湖是近些年比较火热的一个技术。早先大家用的都是一些比较成熟的数据仓库系统,数据通过 ETL 导入到数仓。数仓的典型用途是用于 BI 报表之类的分析场景,场景比较有限。在移动互联网时代,数据来源更加丰富多样,数据结构也不仅仅是结构化数据,数据用途也不仅限于分析,于是出现了数据湖。数据先不做,或者仅做简单的处理导入到数据湖,然后再进行筛选、过滤、转换等 transform 操作,于是数仓时代的 ETL 变成了数据湖时代的 ELT。
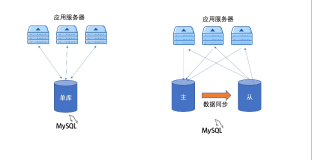
数据湖的典型架构是上层一个/或者多个分析引擎/或者其他计算框架,下层架设一个分布式存储系统,如下图左边所示。但是这种原始的数据湖用法是缺少管理的,比如缺少事务的支持,缺少数据质量的校验等等,一切数据管理完全靠人工手动保证。

Delta Lake 就是在统一的存储层上面架上一层管理层,以解决人们手动管理数据湖数据的痛点。加上了一层管理层,首先我们就可以引入meta data管理,有了meta data管理,如果数据有schema,我们就可以管理schema,在数据入库的过程中对数据质量进行校验,并将不符合的数据剔除。另外,管理了meta data,还可以实现ACID Transactions,也就是事务的特性。在没有管理层的时候如果进行并发的操作,多个操作之间可能互相影响,比如一个用户在查询的时候另外一个用户进行了删除操作,有了事务的支持,就可以避免这种情况,在事务的支持下,每个操作都会生成一个快照,所有操作会生成一个快照序列,方便进行时间上的回溯,也就是时间旅行。
Data Warehouse、Data Lake和Delta Lake三者的主要特性对比如下图所示。可以看出,Delta Lake相当于结合了Data Warehouse和Data Lake的优点,引入一个管理层,解决了大部分两者的缺点。

(三)基于Spark Streaming SQL & Delta 的CDC方案
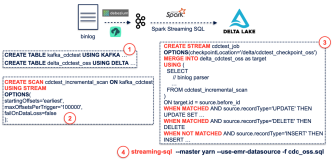
那么,我们现在回到我们的主题,即,如何实现基于Spark Streaming SQL & Delta 的CDC方案呢?如下图所示,还是先从binlog到KafKa,与之前的方式不同的是无需将KafKa中的binlog回放到HBASE或者KUDU,而是直接放入Delta Lake即可。这种方案使用方便,无需额外运维,Merge逻辑容易实现,且几乎是一个实时的数据流。

上述方案的具体操作步骤如下图所示。其本质就是不断的将每一个mini batch给Merge INTO到目标表中。由于 Spark Streaming 的 mini batch 调度建个可以设置在秒级,因此该方案实现了近实时的数据同步。
在该方案的实际执行的过程中我们也遇到了一些问题,最主要的就是小文件问题,比如每五秒执行一次batch,那么一天就会有非常多的batch,可能产生海量的小文件,严重影响表的查询性能。对于小文件问题,其解决思路有以下几个:
- 增大调度批次间隔:如果对实时性要求不是很高,可以增大调度批次间隔,减少小文件产生的频率;
- 小文件合并:进行小文件的合并,减小小文件的数量,其语法如下:
OPTIMIZE WHERE where_clause] - 自适应执行:自适应执行可以合并一些小的reduce task,从而减少小文件数量。
对于小文件合并的optimize触发我们做了两种方式。第一种是自动化的optimize,就是在每一个mini batch执行完之后都进行检测是否需要进行合并,如果不需要就跳到下一个mini batch,判断的规则有很多,比如小文件达到一定数量、总得文件体积达到一定大小就进行合并,当然在合并的时候也进行了一些优化,比如过滤掉本身已经比较大的文件。自动化的optimize方式每过一定数量的batch就要进行一次merge操作,可能对数据数据摄入造成一定影响,因此还有第二种方式,就是定期执行optimize的方式,这种方式对于数据实时摄入没有影响。但是,定期执行optimize的方式会存在事务冲突的问题,也就是optimize与流冲突,对于这种情况我们优化了Delta内部的事务提交机制,让insert流不必失败,如果在optimize之前进行了update/delete,而optimize成功了,那么在成功之后要加一个重试的过程,以免流断掉。
OPTIMIZE的实现也是比较复杂的,我们开发了bin-packing机制和自适应机制,达成的效果就是在OPTIMIZE后所有文件(除了最后一个)都达到目标大小(比如128M),而不论是否做了 re-partition。

三、未来工作
未来,以下几方面将会是我们的工作目标:
(1)自动Schema检测
使用Delta Lake的用户接触的可能不只是业务数据,还可能有机器数据。在很多场景下,机器数据的字段可能会发生变化。对于这种场景的用户来说,迫切需要一种自动Schema检测的机制。下一阶段我们的目标就是在binlog解析的时候能够自动检测新增字段、变化字段等,并且反映在Delta表中。
(2)流式Merge性能(Merge on Read)
上面提到了Spark Streaming SQL & Delta 的CDC方案本质上是发起了一个流处理,然后按照mini batch将数据merge到目标表中,merge的实现实际上是一个join,当表越来越大的时候merge性能会越来越差,严重影响性能。解决这个问题的方式是采用merge on read的方式,就是类似于HIVE的方式,是我们下一步的目标。
(3)更易用的体验
可以看到,上文提到的CDC方案还是需要用户有一定的专业知识,并且需要手动做一些工作,下一步我们希望能够提供更易用的体验,进一步降低用户的使用负担。
关键词:Delta Lake、CDC、实时数仓、OPTIMIZE、Spark Streaming SQL
EMR钉钉产品交流群
对开源大数据和感兴趣的同学可以加小编微信(下图二维码,备注“进群”)进入技术交流微信群。

Apache Spark技术交流社区公众号,微信扫一扫关注