作者介绍
魏彬,普翔科技 CTO,开源软件爱好者,中国第一位 Elastic 认证工程师,《Elastic日报》和 《ElasticTalk》社区项目发起人,被 elastic 中国公司授予 2019 年度合作伙伴架构师特别贡献奖。对 Elasticsearch、Kibana、Beats、Logstash、Grafana 等开源软件有丰富的实践经验,为零售、金融、保险、证券、科技等众多行业的客户提供过咨询和培训服务,帮助客户在实际业务中找准开源软件的定位,实现从 0 到 1 的落地、从 1 到 N 的拓展,产生实际的业务价值。
解决方案
1、减少 Logstash 重启的次数,也就节省宝贵的时间
2、方便快捷地向 Logstash 输入需要处理的内容
1、打开 reload 配置开关
Logstash 启动的时候可以加上 -r 的参数来做到配置文件热加载,效果是:
• 当你修改了配置文件后,无需重启 Logstash 即可让新配置文件生效。
它的含义如下:

当你写好配置文件,比如 test.conf ,启动命令如下:
bin/logstash -f test.conf -r
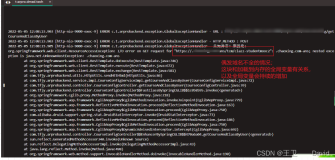
启动完毕,修改 test.conf 的内容并保存后,过 1 秒钟,你会发现 Logstash 端有类似如下日志输出(注意红色框标记的部分),此时说明 reload 的成功。

如果你修改的配置文件有错误,会看到报错的日志,你可以根据错误提示修改。

至此,第一个问题解决!
2. 使用 HTTP INPUT
编写配置文件的另一个痛点是需要针对不同格式的输入内容进行详细的测试,以防解析报错的情况出现。此时大家常用标准输入来解决这个问题(stdin input),但是标准输入对于文字编辑支持不太友好,而且配置文件热更新的功能也不支持标准输入。
在这里向大家推荐使用 http input 插件,配置如下:
input{
http{
port => 7474
codec => "json"
}
}然后大家再用自己喜欢的 http 请求工具,比如 POSTMan、Insomnia 等向 http://loclahost:7474发送待测试内容即可,如下是 Insomnia 的截图。

至此,第二个问题也解决了。
总结
相信看到这里,大家一定是跃跃欲试了,赶紧打开电脑,找到 Logstash,然后编辑 test.conf,输入如下内容:
input{
http{
port => 7474
codec => "json"
}
}
filter{
}
output{
stdout{
codec => rubydebug{
metadata => true
}
}
}然后执行启动命令:
bin/logstash -f test.conf -r
打开 Insomnia ,输入要测试的内容,点击发送,开始舒爽流畅的配置文件编写之旅吧!
声明:本文由原文《不可不掌握的Logstash使用技巧》作者“魏彬”授权转载,对未经许可擅自使用者,保留追究其法律责任的权利。

【阿里云Elastic Stack】100%兼容开源ES,独有9大能力,提供免费X-pack服务(单节点价值$6000)
相关活动
更多折扣活动,请访问阿里云 Elasticsearch 官网
阿里云 Elasticsearch 商业通用版,1核2G ,SSD 20G首月免费
阿里云 Logstash 2核4G首月免费